Return the absolute value of a number. The argument may be an integer, a floating point number, or an object implementing__abs__(). If the argument is a complex number, its magnitude is returned.
A random forest is a meta estimator that fits a number of classifying decision trees on various sub-samples of the dataset and uses averaging to improve the predictive accuracy and control over-fitting. The sub-sample size is controlled with themax_samplesparameter ifbootstrap=True(default), otherwise the whole dataset is used to build each tree.
Changed in version 0.22:The default value ofn_estimatorschanged from 10 to 100 in 0.22.
criterion{“mse”, “mae”}, default=”mse”
The function to measure the quality of a split. Supported criteria are “mse” for the mean squared error, which is equal to variance reduction as feature selection criterion, and “mae” for the mean absolute error.
New in version 0.18:Mean Absolute Error (MAE) criterion.
max_depthint, default=None
The maximum depth of the tree. If None, then nodes are expanded until all leaves are pure or until all leaves contain less than min_samples_split samples.
min_samples_splitint or float, default=2
The minimum number of samples required to split an internal node:
If int, then considermin_samples_splitas the minimum number.
If float, thenmin_samples_splitis a fraction andceil(min_samples_split*n_samples)are the minimum number of samples for each split.
Changed in version 0.18:Added float values for fractions.
min_samples_leafint or float, default=1
The minimum number of samples required to be at a leaf node. A split point at any depth will only be considered if it leaves at leastmin_samples_leaftraining samples in each of the left and right branches. This may have the effect of smoothing the model, especially in regression.
If int, then considermin_samples_leafas the minimum number.
If float, thenmin_samples_leafis a fraction andceil(min_samples_leaf*n_samples)are the minimum number of samples for each node.
Changed in version 0.18:Added float values for fractions.
min_weight_fraction_leaffloat, default=0.0
The minimum weighted fraction of the sum total of weights (of all the input samples) required to be at a leaf node. Samples have equal weight when sample_weight is not provided.
max_features{“auto”, “sqrt”, “log2”}, int or float, default=”auto”
The number of features to consider when looking for the best split:
If int, then considermax_featuresfeatures at each split.
If float, thenmax_featuresis a fraction andint(max_features*n_features)features are considered at each split.
If “auto”, thenmax_features=n_features.
If “sqrt”, thenmax_features=sqrt(n_features).
If “log2”, thenmax_features=log2(n_features).
If None, thenmax_features=n_features.
Note: the search for a split does not stop until at least one valid partition of the node samples is found, even if it requires to effectively inspect more thanmax_featuresfeatures.
max_leaf_nodesint, default=None
Grow trees withmax_leaf_nodesin best-first fashion. Best nodes are defined as relative reduction in impurity. If None then unlimited number of leaf nodes.
min_impurity_decreasefloat, default=0.0
A node will be split if this split induces a decrease of the impurity greater than or equal to this value.
The weighted impurity decrease equation is the following:
whereNis the total number of samples,N_tis the number of samples at the current node,N_t_Lis the number of samples in the left child, andN_t_Ris the number of samples in the right child.
N,N_t,N_t_RandN_t_Lall refer to the weighted sum, ifsample_weightis passed.
New in version 0.19.
min_impurity_splitfloat, default=None
Threshold for early stopping in tree growth. A node will split if its impurity is above the threshold, otherwise it is a leaf.
Deprecated since version 0.19:min_impurity_splithas been deprecated in favor ofmin_impurity_decreasein 0.19. The default value ofmin_impurity_splithas changed from 1e-7 to 0 in 0.23 and it will be removed in 0.25. Usemin_impurity_decreaseinstead.
bootstrapbool, default=True
Whether bootstrap samples are used when building trees. If False, the whole dataset is used to build each tree.
oob_scorebool, default=False
whether to use out-of-bag samples to estimate the R^2 on unseen data.
Controls both the randomness of the bootstrapping of the samples used when building trees (ifbootstrap=True) and the sampling of the features to consider when looking for the best split at each node (ifmax_features<n_features). SeeGlossaryfor details.
verboseint, default=0
Controls the verbosity when fitting and predicting.
warm_startbool, default=False
When set toTrue, reuse the solution of the previous call to fit and add more estimators to the ensemble, otherwise, just fit a whole new forest. Seethe Glossary.
ccp_alphanon-negative float, default=0.0
Complexity parameter used for Minimal Cost-Complexity Pruning. The subtree with the largest cost complexity that is smaller thanccp_alphawill be chosen. By default, no pruning is performed. SeeMinimal Cost-Complexity Pruningfor details.
New in version 0.22.
max_samplesint or float, default=None
If bootstrap is True, the number of samples to draw from X to train each base estimator.
If None (default), then drawX.shape[0]samples.
If int, then drawmax_samplessamples.
If float, then drawmax_samples*X.shape[0]samples. Thus,max_samplesshould be in the interval(0,1).
New in version 0.22.
Attributes
base_estimator_DecisionTreeRegressor
The child estimator template used to create the collection of fitted sub-estimators.
y_truearray-like of shape (n_samples,) or (n_samples, n_outputs)
Ground truth (correct) target values.
y_predarray-like of shape (n_samples,) or (n_samples, n_outputs)
Estimated target values.
sample_weightarray-like of shape (n_samples,), optional
Sample weights.
multioutputstring in [‘raw_values’, ‘uniform_average’] or array-like of shape (n_outputs)
Defines aggregating of multiple output values. Array-like value defines weights used to average errors.
‘raw_values’ :
Returns a full set of errors in case of multioutput input.
‘uniform_average’ :
Errors of all outputs are averaged with uniform weight.
Returns
lossfloat or ndarray of floats
If multioutput is ‘raw_values’, then mean absolute error is returned for each output separately. If multioutput is ‘uniform_average’ or an ndarray of weights, then the weighted average of all output errors is returned.
MAE output is non-negative floating point. The best value is 0.0.
// 값이 작을 수록 좋기 때문에 초기 값은 매우 큰 값으로 정의함.
// LightGBM 에서 DataFrame 이 잘 처리 되지 않는 것을 방지하기 위해서 .values 를 사용하였다.
06. Ch 23. 진짜 문제를 해결해 보자 (1) - 상점 신용카드 매출 예측 - 05. (5) 모델 적용
// 모델 학습이 다 끝나서 새로 들어온 데이터에서 대해서 예측을 해보는 것이다.
// pipeline 을 이용해서 구축할 수 있다.
07. Ch 24. 진짜 문제를 해결해 보자 (2) - 아파트 실거래가 예측 - 01. (1) 문제 소개
* 아파트 실거래가 예측
// 실제 데이터는 크기가 크기 때문에 샘플 데이터로 주었다.
// 참조 데이터는 대회 문제 해결을 위해, 강사가 직접 수집한 데이터이며, 어떠한 정제도 하지 않았다.
08. Ch 24. 진짜 문제를 해결해 보자 (2) - 아파트 실거래가 예측 - 02. (2) 변수 변환 및 부착
Calculateselement in test_elements, broadcasting overelementonly. Returns a boolean array of the same shape aselementthat is True where an element ofelementis intest_elementsand False otherwise.
Parameters
elementarray_like
Input array.
test_elementsarray_like
The values against which to test each value ofelement. This argument is flattened if it is an array or array_like. See notes for behavior with non-array-like parameters.
assume_uniquebool, optional
If True, the input arrays are both assumed to be unique, which can speed up the calculation. Default is False.
invertbool, optional
If True, the values in the returned array are inverted, as if calculatingelement not in test_elements. Default is False.np.isin(a,b,invert=True)is equivalent to (but faster than)np.invert(np.isin(a,b)).
Returns
isinndarray, bool
Has the same shape aselement. The valueselement[isin]are intest_elements.
Thepicklemodule implements binary protocols for serializing and de-serializing a Python object structure.“Pickling”is the process whereby a Python object hierarchy is converted into a byte stream, and“unpickling”is the inverse operation, whereby a byte stream (from abinary fileorbytes-like object) is converted back into an object hierarchy. Pickling (and unpickling) is alternatively known as “serialization”, “marshalling,”1or “flattening”; however, to avoid confusion, the terms used here are “pickling” and “unpickling”.
JSON is a text serialization format (it outputs unicode text, although most of the time it is then encoded toutf-8), while pickle is a binary serialization format;
JSON is human-readable, while pickle is not;
JSON is interoperable and widely used outside of the Python ecosystem, while pickle is Python-specific;
JSON, by default, can only represent a subset of the Python built-in types, and no custom classes; pickle can represent an extremely large number of Python types (many of them automatically, by clever usage of Python’s introspection facilities; complex cases can be tackled by implementingspecific object APIs);
Unlike pickle, deserializing untrusted JSON does not in itself create an arbitrary code execution vulnerability.
sampling_strategyfloat, str, dict or callable, default=’auto’
Sampling information to resample the data set.
Whenfloat, it corresponds to the desired ratio of the number of samples in the minority class over the number of samples in the majority class after resampling. Therefore, the ratio is expressed as
where
is the number of samples in the minority class after resampling and
is the number of samples in the majority class.
Warning
floatis only available forbinaryclassification. An error is raised for multi-class classification.
Whenstr, specify the class targeted by the resampling. The number of samples in the different classes will be equalized. Possible choices are:
'minority': resample only the minority class;
'notminority': resample all classes but the minority class;
'notmajority': resample all classes but the majority class;
'all': resample all classes;
'auto': equivalent to'notmajority'.
Whendict, the keys correspond to the targeted classes. The values correspond to the desired number of samples for each targeted class.
When callable, function takingyand returns adict. The keys correspond to the targeted classes. The values correspond to the desired number of samples for each class.
If int,random_stateis the seed used by the random number generator;
IfRandomStateinstance, random_state is the random number generator;
IfNone, the random number generator is theRandomStateinstance used bynp.random.
k_neighborsint or object, default=5
If int, number of nearest neighbours to used to construct synthetic samples. If object, an estimator that inherits from sklearn.neighbors.base.KNeighborsMixin that will be used to find the k_neighbors.
n_jobsint, default=None
Number of CPU cores used during the cross-validation loop. None means 1 unless in a joblib.parallel_backend context. -1 means using all processors. See Glossary for more details.
Whenfloat, it corresponds to the desired ratio of the number of samples in the minority class over the number of samples in the majority class after resampling. Therefore, the ratio is expressed as
where
is the number of samples in the minority class and
is the number of samples in the majority class after resampling.
Warning
floatis only available forbinaryclassification. An error is raised for multi-class classification.
Whenstr, specify the class targeted by the resampling. The number of samples in the different classes will be equalized. Possible choices are:
'majority': resample only the majority class;
'notminority': resample all classes but the minority class;
'notmajority': resample all classes but the majority class;
'all': resample all classes;
'auto': equivalent to'notminority'.
Whendict, the keys correspond to the targeted classes. The values correspond to the desired number of samples for each targeted class.
When callable, function takingyand returns adict. The keys correspond to the targeted classes. The values correspond to the desired number of samples for each class.
versionint, default=1
Version of the NearMiss to use. Possible values are 1, 2 or 3.
n_neighborsint or object, default=3
If int, size of the neighbourhood to consider to compute the average distance to the minority point samples. If object, an estimator that inherits from sklearn.neighbors.base.KNeighborsMixin that will be used to find the k_neighbors.
n_neighbors_ver3int or object, default=3
If int, NearMiss-3 algorithm start by a phase of re-sampling. This parameter correspond to the number of neighbours selected create the subset in which the selection will be performed. If object, an estimator that inherits from sklearn.neighbors.base.KNeighborsMixin that will be used to find the k_neighbors.
n_jobsint, default=None
Number of CPU cores used during the cross-validation loop. None means 1 unless in a joblib.parallel_backend context. -1 means using all processors. See Glossary for more details.
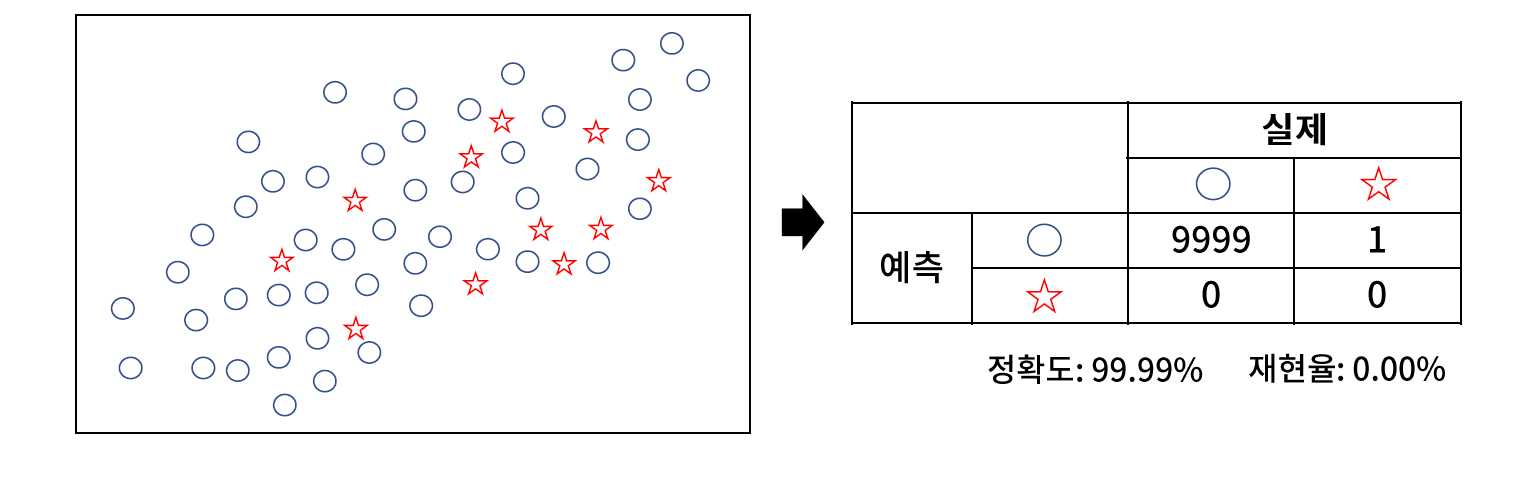
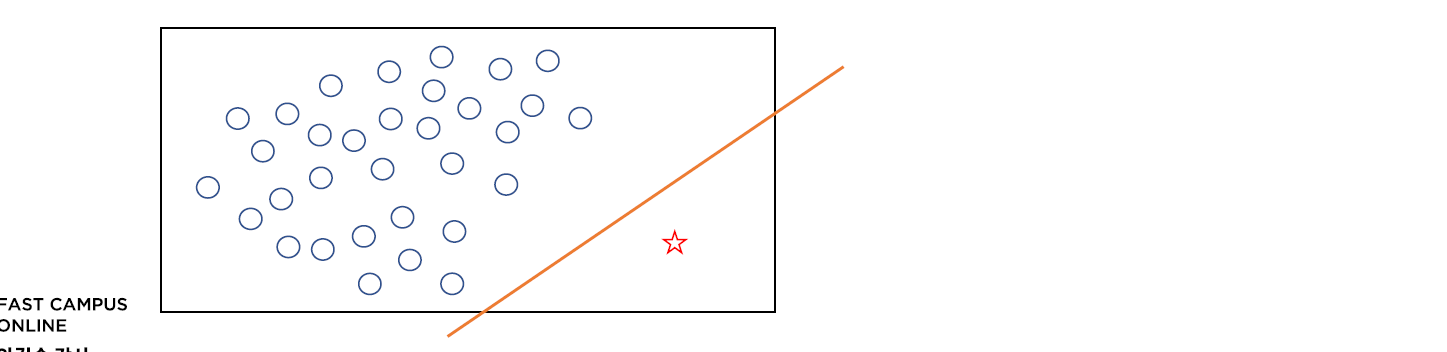
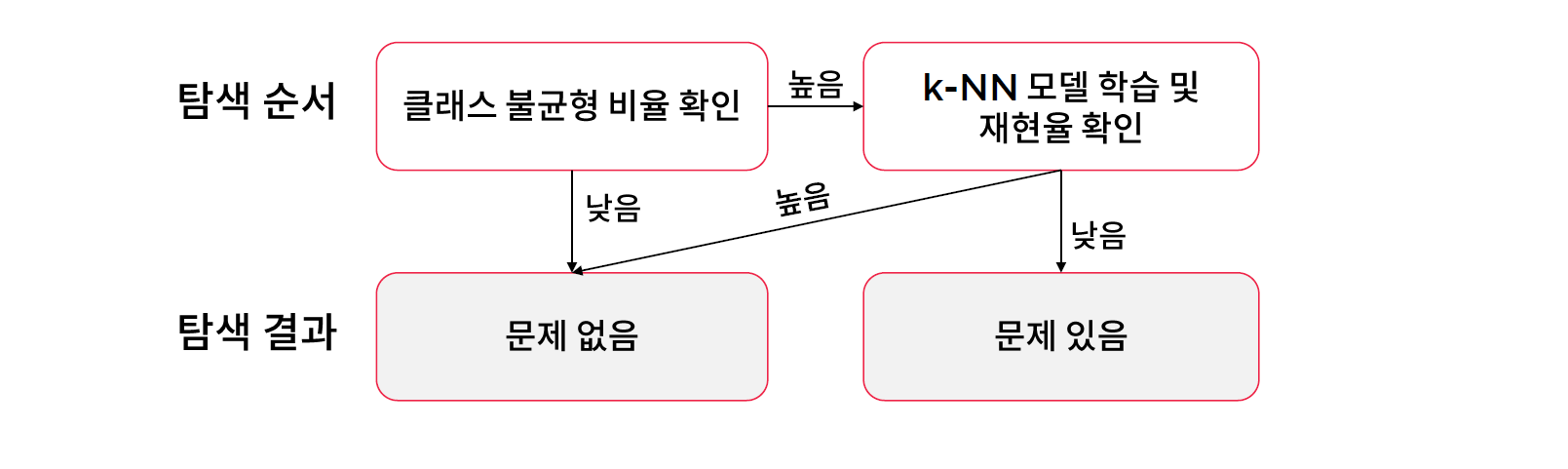
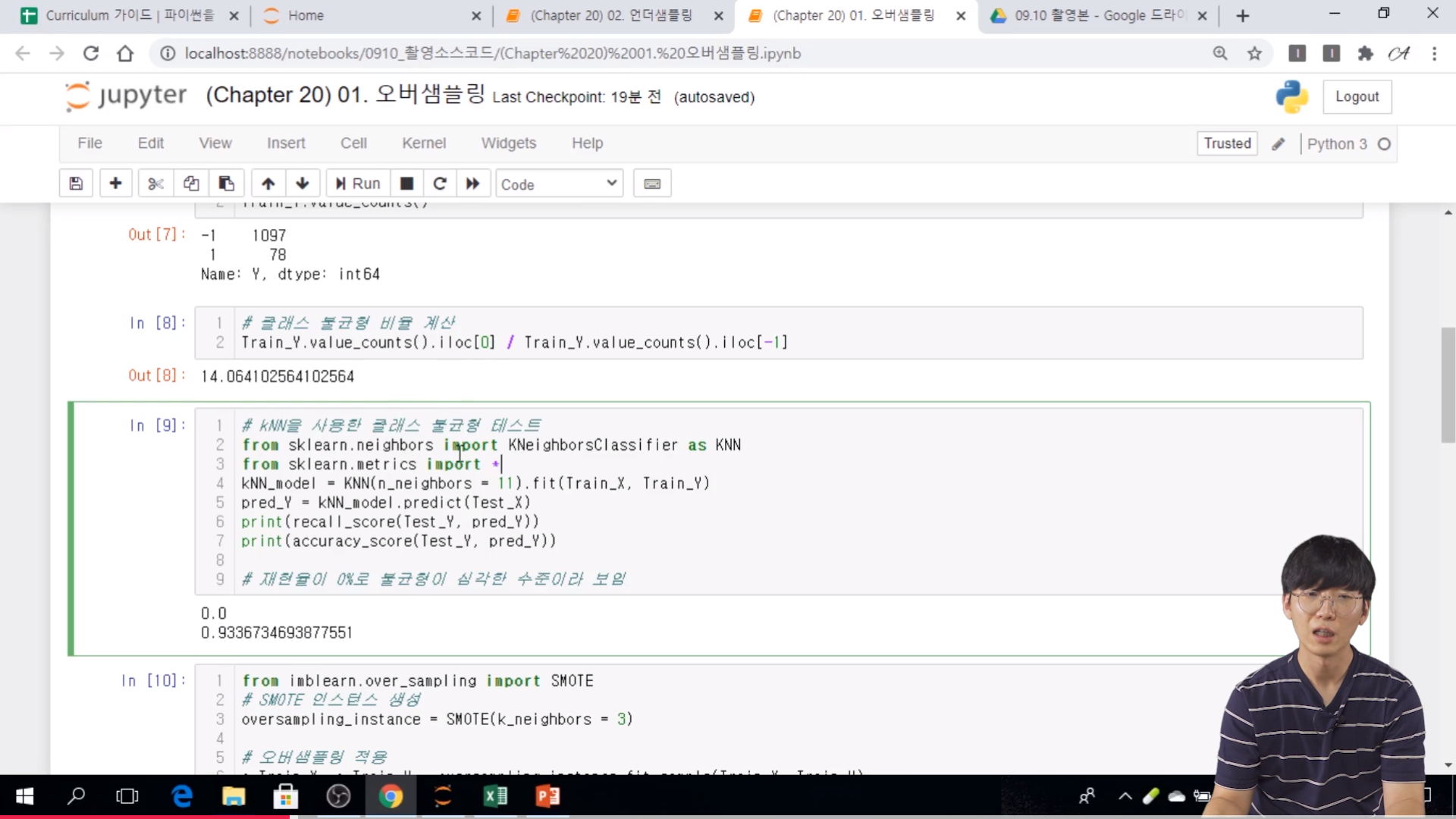
[05. Part 5) Ch 20. 편향된 모델은 쓸모 없어 - 클래스 불균형 문제 - 02-2. 재샘플링 - 오버샘플링과 언더 샘플링(실습)]
// kNN 을 사용해서 클래스 불균형도 테스트를 해준다.
// KNeighborsClassifier
// 재현율 0% 로 불균형이 심각한 수준이라 볼 수 있다.
[05. Part 5) Ch 20. 편향된 모델은 쓸모 없어 - 클래스 불균형 문제 - 03-1 비용 민감 모델 (이론)]
// 모델의 학습 변경한 모델이라고 볼 수 있다. 전처리라고 보기는 좀 어렵다.
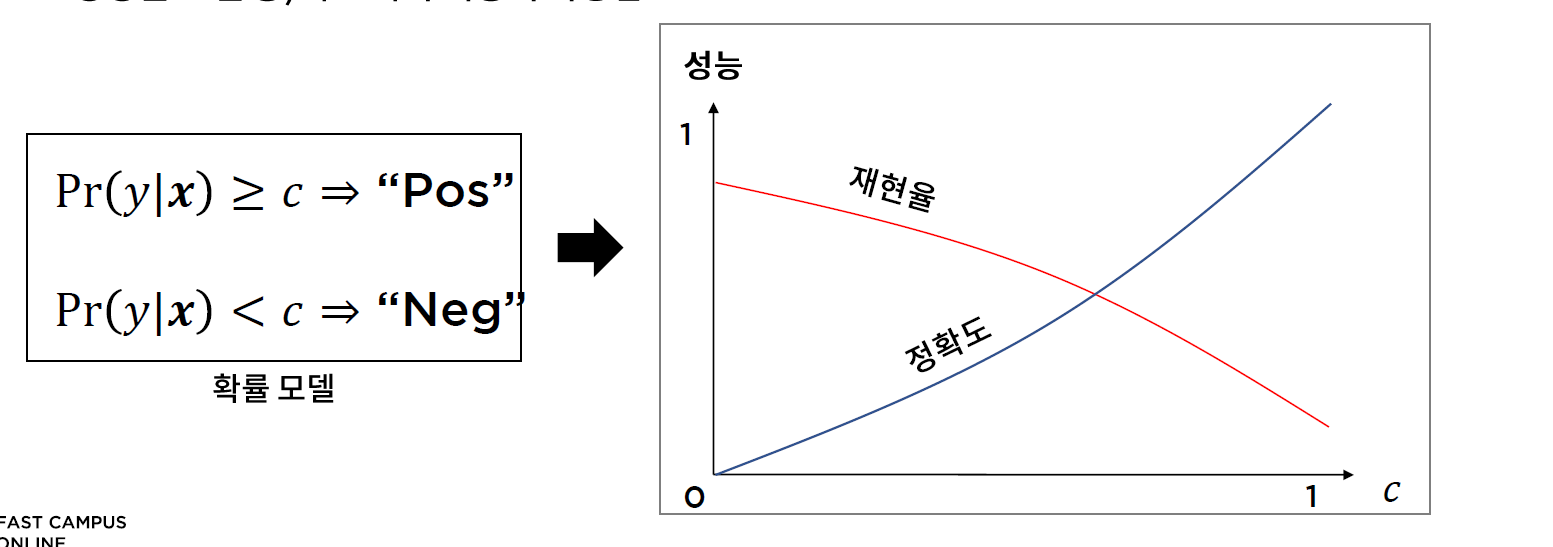
* 정의
// 비용을 위양성 비용보다 크게 설정
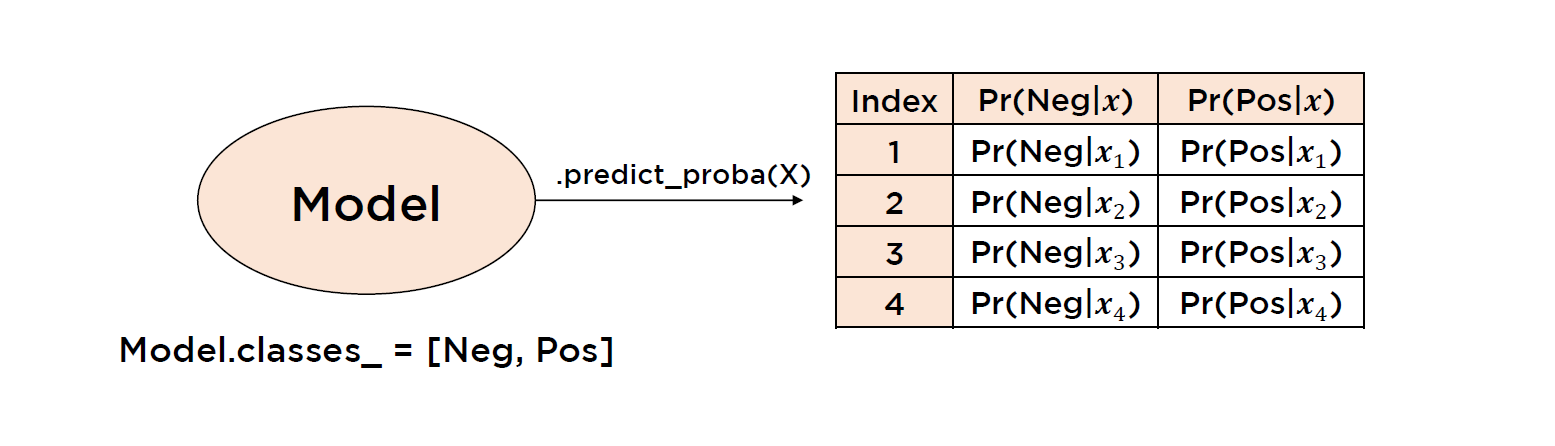
* 확률 모델
* 관련문법: .predict_proba
* Tip.Numpy 와 Pandas 잘 쓰는 기본 원칙 : 가능하면 배열 단위 연산을 하라
// 유니버설 함수, 브로드캐스팅, 마스크 연산을 최대한 활용
* 비확률 모델 (1) 서포트 벡터 머신
* 비확률 모델 (2) 의사결정 나무
* 관련문법 : class_weight
[05. Part 5) Ch 20. 편향된 모델은 쓸모 없어 - 클래스 불균형 문제 - 03-2 비용 민감 모델 (실습)]
The multiclass support is handled according to a one-vs-one scheme.
For details on the precise mathematical formulation of the provided kernel functions and how gamma, coef0 and degree affect each other, see the corresponding section in the narrative documentation: Kernel functions.
Regularization parameter. The strength of the regularization is inversely proportional to C. Must be strictly positive. The penalty is a squared l2 penalty.
Specifies the kernel type to be used in the algorithm. It must be one of ‘linear’, ‘poly’, ‘rbf’, ‘sigmoid’, ‘precomputed’ or a callable. If none is given, ‘rbf’ will be used. If a callable is given it is used to pre-compute the kernel matrix from data matrices; that matrix should be an array of shape (n_samples, n_samples).
degreeint, default=3
Degree of the polynomial kernel function (‘poly’). Ignored by all other kernels.
gamma{‘scale’, ‘auto’} or float, default=’scale’
Kernel coefficient for ‘rbf’, ‘poly’ and ‘sigmoid’.
ifgamma='scale'(default) is passed then it uses 1 / (n_features * X.var()) as value of gamma,
if ‘auto’, uses 1 / n_features.
Changed in version 0.22: The default value of gamma changed from ‘auto’ to ‘scale’.
coef0float, default=0.0
Independent term in kernel function. It is only significant in ‘poly’ and ‘sigmoid’.
shrinkingbool, default=True
Whether to use the shrinking heuristic. See the User Guide.
probabilitybool, default=False
Whether to enable probability estimates. This must be enabled prior to calling fit, will slow down that method as it internally uses 5-fold cross-validation, and predict_proba may be inconsistent with predict. Read more in the User Guide.
tolfloat, default=1e-3
Tolerance for stopping criterion.
cache_sizefloat, default=200
Specify the size of the kernel cache (in MB).
class_weightdict or ‘balanced’, default=None
Set the parameter C of class i to class_weight[i]*C for SVC. If not given, all classes are supposed to have weight one. The “balanced” mode uses the values of y to automatically adjust weights inversely proportional to class frequencies in the input data as n_samples / (n_classes * np.bincount(y))
verbosebool, default=False
Enable verbose output. Note that this setting takes advantage of a per-process runtime setting in libsvm that, if enabled, may not work properly in a multithreaded context.
max_iterint, default=-1
Hard limit on iterations within solver, or -1 for no limit.
Whether to return a one-vs-rest (‘ovr’) decision function of shape (n_samples, n_classes) as all other classifiers, or the original one-vs-one (‘ovo’) decision function of libsvm which has shape (n_samples, n_classes * (n_classes - 1) / 2). However, one-vs-one (‘ovo’) is always used as multi-class strategy. The parameter is ignored for binary classification.
Changed in version 0.19: decision_function_shape is ‘ovr’ by default.
New in version 0.17: decision_function_shape=’ovr’ is recommended.
Changed in version 0.17: Deprecated decision_function_shape=’ovo’ and None.
break_tiesbool, default=False
If true, decision_function_shape='ovr', and number of classes > 2, predict will break ties according to the confidence values of decision_function; otherwise the first class among the tied classes is returned. Please note that breaking ties comes at a relatively high computational cost compared to a simple predict.
New in version 0.22.
random_stateint or RandomState instance, default=None
Controls the pseudo random number generation for shuffling the data for probability estimates. Ignored when probability is False. Pass an int for reproducible output across multiple function calls. See Glossary.
Attributes
support_ndarray of shape (n_SV,)
Indices of support vectors.
support_vectors_ndarray of shape (n_SV, n_features)
Support vectors.
n_support_ndarray of shape (n_class,), dtype=int32
Number of support vectors for each class.
dual_coef_ndarray of shape (n_class-1, n_SV)
Dual coefficients of the support vector in the decision function (see Mathematical formulation), multiplied by their targets. For multiclass, coefficient for all 1-vs-1 classifiers. The layout of the coefficients in the multiclass case is somewhat non-trivial. See the multi-class section of the User Guide for details.
coef_ndarray of shape (n_class * (n_class-1) / 2, n_features)
Weights assigned to the features (coefficients in the primal problem). This is only available in the case of a linear kernel.
coef_ is a readonly property derived from dual_coef_ and support_vectors_.
intercept_ndarray of shape (n_class * (n_class-1) / 2,)
Constants in decision function.
fit_status_int
0 if correctly fitted, 1 otherwise (will raise warning)
classes_ndarray of shape (n_classes,)
The classes labels.
probA_ndarray of shape (n_class * (n_class-1) / 2)probB_ndarray of shape (n_class * (n_class-1) / 2)
If probability=True, it corresponds to the parameters learned in Platt scaling to produce probability estimates from decision values. If probability=False, it’s an empty array. Platt scaling uses the logistic function 1 / (1 + exp(decision_value * probA_ + probB_)) where probA_ and probB_ are learned from the dataset [2]. For more information on the multiclass case and training procedure see section 8 of [1].
class_weight_ndarray of shape (n_class,)
Multipliers of parameter C for each class. Computed based on the class_weight parameter.
shape_fit_tuple of int of shape (n_dimensions_of_X,)
One hot encoding consists in replacing the categorical variable by a combination of binary variables which take value 0 or 1, to indicate if a certain category is present in an observation.
Each one of the binary variables are also known as dummy variables. For example, from the categorical variable “Gender” with categories ‘female’ and ‘male’, we can generate the boolean variable “female”, which takes 1 if the person is female or 0 otherwise. We can also generate the variable male, which takes 1 if the person is “male” and 0 otherwise.
The encoder has the option to generate one dummy variable per category, or to create dummy variables only for the top n most popular categories, that is, the categories that are shown by the majority of the observations.
If dummy variables are created for all the categories of a variable, you have the option to drop one category not to create information redundancy. That is, encoding into k-1 variables, where k is the number if unique categories.
The encoder will encode only categorical variables (type ‘object’). A list of variables can be passed as an argument. If no variables are passed as argument, the encoder will find and encode categorical variables (object type).
The encoder first finds the categories to be encoded for each variable (fit).
The encoder then creates one dummy variable per category for each variable (transform).
Note: new categories in the data to transform, that is, those that did not appear in the training set, will be ignored (no binary variable will be created for them).
Parameters
top_categories(int,default=None) – If None, a dummy variable will be created for each category of the variable. Alternatively, top_categories indicates the number of most frequent categories to encode. Dummy variables will be created only for those popular categories and the rest will be ignored. Note that this is equivalent to grouping all the remaining categories in one group.
variables(list) – The list of categorical variables that will be encoded. If None, the encoder will find and select all object type variables.
drop_last(boolean,default=False) – Only used if top_categories = None. It indicates whether to create dummy variables for all the categories (k dummies), or if set to True, it will ignore the last variable of the list (k-1 dummies).
Learns the unique categories per variable. If top_categories is indicated, it will learn the most popular categories. Alternatively, it learns all unique categories per variable.
Parameters
X(pandas dataframe of shape =[n_samples,n_features]) – The training input samples. Can be the entire dataframe, not just seleted variables.
y(pandas series,default=None) – Target. It is not needed in this encoded. You can pass y or None.
encoder_dict\_
The dictionary containing the categories for which dummy variables will be created.
numpy.quantile(a, q, axis=None, out=None, overwrite_input=False, interpolation='linear', keepdims=False)
Compute the q-th quantile of the data along the specified axis.
New in version 1.15.0.
Parameters
aarray_like
Input array or object that can be converted to an array.
qarray_like of float
Quantile or sequence of quantiles to compute, which must be between 0 and 1 inclusive.
axis{int, tuple of int, None}, optional
Axis or axes along which the quantiles are computed. The default is to compute the quantile(s) along a flattened version of the array.
outndarray, optional
Alternative output array in which to place the result. It must have the same shape and buffer length as the expected output, but the type (of the output) will be cast if necessary.
overwrite_inputbool, optional
If True, then allow the input arrayato be modified by intermediate calculations, to save memory. In this case, the contents of the inputaafter this function completes is undefined.
This optional parameter specifies the interpolation method to use when the desired quantile lies between two data pointsi<j:
linear:i+(j-i)*fraction, wherefractionis the fractional part of the index surrounded byiandj.
lower:i.
higher:j.
nearest:iorj, whichever is nearest.
midpoint:(i+j)/2.
keepdimsbool, optional
If this is set to True, the axes which are reduced are left in the result as dimensions with size one. With this option, the result will broadcast correctly against the original arraya.
Returns
quantilescalar or ndarray
Ifqis a single quantile andaxis=None, then the result is a scalar. If multiple quantiles are given, first axis of the result corresponds to the quantiles. The other axes are the axes that remain after the reduction ofa. If the input contains integers or floats smaller thanfloat64, the output data-type isfloat64. Otherwise, the output data-type is the same as that of the input. Ifoutis specified, that array is returned instead.
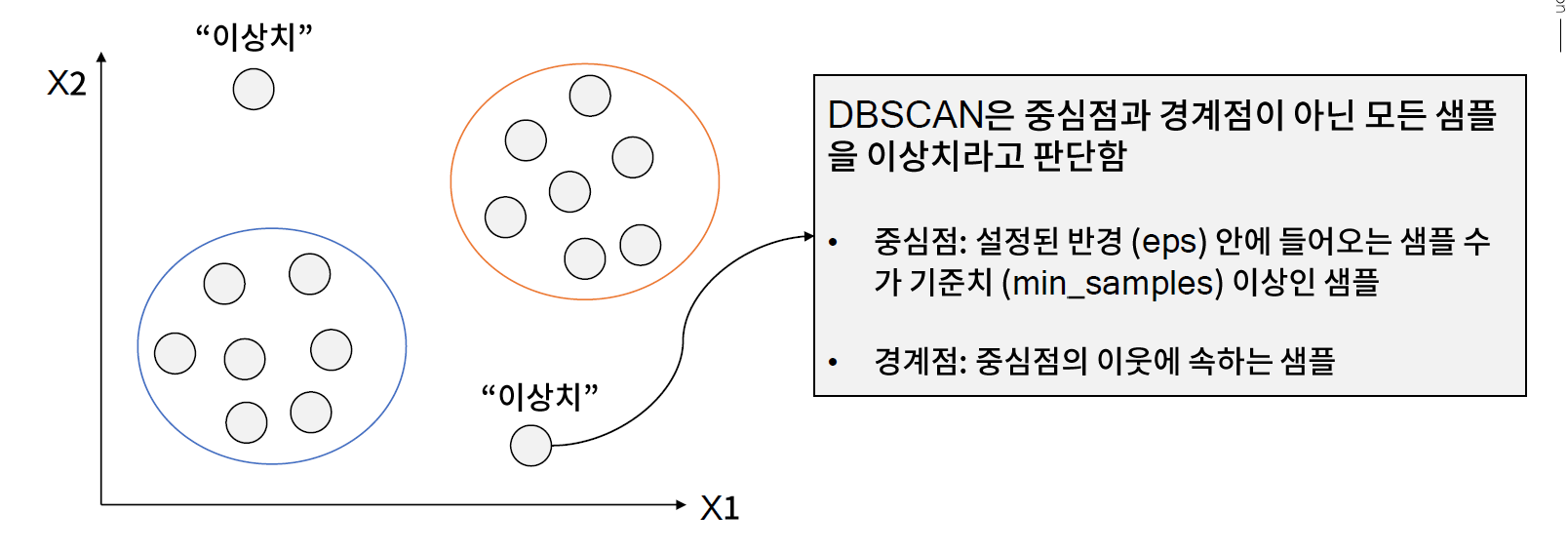
[05. Part 5) Ch 19. 이상적인 분포를 만들순 없을까 변수 분포 문제 - 03. 이상치 제거 (2) 밀도 기반 군집화 활용]
* 이상치 판단 방법 2. 밀도 기반 군집화 수행
// 특정 반경내에서는 중심점.. 중심점에 안 들어오면 경계점 그 모두에 속하지 않는 것들이 이상치라고 부른다.
class sklearn.cluster.DBSCAN(eps=0.5, *, min_samples=5, metric='euclidean', metric_params=None, algorithm='auto', leaf_size=30, p=None, n_jobs=None)
Perform DBSCAN clustering from vector array or distance matrix.
DBSCAN - Density-Based Spatial Clustering of Applications with Noise. Finds core samples of high density and expands clusters from them. Good for data which contains clusters of similar density.
The maximum distance between two samples for one to be considered as in the neighborhood of the other. This is not a maximum bound on the distances of points within a cluster. This is the most important DBSCAN parameter to choose appropriately for your data set and distance function.
min_samplesint, default=5
The number of samples (or total weight) in a neighborhood for a point to be considered as a core point. This includes the point itself.
metricstring, or callable, default=’euclidean’
The metric to use when calculating distance between instances in a feature array. If metric is a string or callable, it must be one of the options allowed bysklearn.metrics.pairwise_distancesfor its metric parameter. If metric is “precomputed”, X is assumed to be a distance matrix and must be square. X may be aGlossary, in which case only “nonzero” elements may be considered neighbors for DBSCAN.
New in version 0.17:metricprecomputedto accept precomputed sparse matrix.
metric_paramsdict, default=None
Additional keyword arguments for the metric function.
The algorithm to be used by the NearestNeighbors module to compute pointwise distances and find nearest neighbors. See NearestNeighbors module documentation for details.
leaf_sizeint, default=30
Leaf size passed to BallTree or cKDTree. This can affect the speed of the construction and query, as well as the memory required to store the tree. The optimal value depends on the nature of the problem.
pfloat, default=None
The power of the Minkowski metric to be used to calculate distance between points.
n_jobsint, default=None
The number of parallel jobs to run.Nonemeans 1 unless in ajoblib.parallel_backendcontext.-1means using all processors. SeeGlossaryfor more details.
Attributes
core_sample_indices_ndarray of shape (n_core_samples,)
Indices of core samples.
components_ndarray of shape (n_core_samples, n_features)
Copy of each core sample found by training.
labels_ndarray of shape (n_samples)
Cluster labels for each point in the dataset given to fit(). Noisy samples are given the label -1.
* 실습
// cdist 은 DBSCAN 을 볼때 참고할 때를 위해서 가져온 library 이다.
// 파라미터를 조정하면서 값들을 확인한다.
[05. Part 5) Ch 19. 이상적인 분포를 만들순 없을까 변수 분포 문제 - 04. 특징 간 상관성 제거]
class sklearn.decomposition.PCA(n_components=None, *, copy=True, whiten=False, svd_solver='auto', tol=0.0, iterated_power='auto', random_state=None)
Principal component analysis (PCA).
Linear dimensionality reduction using Singular Value Decomposition of the data to project it to a lower dimensional space. The input data is centered but not scaled for each feature before applying the SVD.
It uses the LAPACK implementation of the full SVD or a randomized truncated SVD by the method of Halko et al. 2009, depending on the shape of the input data and the number of components to extract.
It can also use the scipy.sparse.linalg ARPACK implementation of the truncated SVD.
Notice that this class does not support sparse input. SeeTruncatedSVDfor an alternative with sparse data.
Number of components to keep. if n_components is not set all components are kept:
n_components==min(n_samples,n_features)
Ifn_components=='mle'andsvd_solver=='full', Minka’s MLE is used to guess the dimension. Use ofn_components=='mle'will interpretsvd_solver=='auto'assvd_solver=='full'.
If0<n_components<1andsvd_solver=='full', select the number of components such that the amount of variance that needs to be explained is greater than the percentage specified by n_components.
Ifsvd_solver=='arpack', the number of components must be strictly less than the minimum of n_features and n_samples.
Hence, the None case results in:
n_components==min(n_samples,n_features)-1
copybool, default=True
If False, data passed to fit are overwritten and running fit(X).transform(X) will not yield the expected results, use fit_transform(X) instead.
whitenbool, optional (default False)
When True (False by default) thecomponents_vectors are multiplied by the square root of n_samples and then divided by the singular values to ensure uncorrelated outputs with unit component-wise variances.
Whitening will remove some information from the transformed signal (the relative variance scales of the components) but can sometime improve the predictive accuracy of the downstream estimators by making their data respect some hard-wired assumptions.
svd_solverstr {‘auto’, ‘full’, ‘arpack’, ‘randomized’}If auto :
The solver is selected by a default policy based onX.shapeandn_components: if the input data is larger than 500x500 and the number of components to extract is lower than 80% of the smallest dimension of the data, then the more efficient ‘randomized’ method is enabled. Otherwise the exact full SVD is computed and optionally truncated afterwards.
If full :
run exact full SVD calling the standard LAPACK solver viascipy.linalg.svdand select the components by postprocessing
If arpack :
run SVD truncated to n_components calling ARPACK solver viascipy.sparse.linalg.svds. It requires strictly 0 < n_components < min(X.shape)
If randomized :
run randomized SVD by the method of Halko et al.
New in version 0.18.0.
tolfloat >= 0, optional (default .0)
Tolerance for singular values computed by svd_solver == ‘arpack’.
New in version 0.18.0.
iterated_powerint >= 0, or ‘auto’, (default ‘auto’)
Number of iterations for the power method computed by svd_solver == ‘randomized’.
Percentage of variance explained by each of the selected components.
Ifn_componentsis not set then all components are stored and the sum of the ratios is equal to 1.0.
singular_values_array, shape (n_components,)
The singular values corresponding to each of the selected components. The singular values are equal to the 2-norms of then_componentsvariables in the lower-dimensional space.
New in version 0.19.
mean_array, shape (n_features,)
Per-feature empirical mean, estimated from the training set.
Equal toX.mean(axis=0).
n_components_int
The estimated number of components. When n_components is set to ‘mle’ or a number between 0 and 1 (with svd_solver == ‘full’) this number is estimated from input data. Otherwise it equals the parameter n_components, or the lesser value of n_features and n_samples if n_components is None.
n_features_int
Number of features in the training data.
n_samples_int
Number of samples in the training data.
noise_variance_float
The estimated noise covariance following the Probabilistic PCA model from Tipping and Bishop 1999. See “Pattern Recognition and Machine Learning” by C. Bishop, 12.2.1 p. 574 orhttp://www.miketipping.com/papers/met-mppca.pdf. It is required to compute the estimated data covariance and score samples.
Equal to the average of (min(n_features, n_samples) - n_components) smallest eigenvalues of the covariance matrix of X.
* 실습
// 특징간 상관 관계가 너무 크다.
// VIF 계산. LinearRegression 으로 작업한 후 R sqaure
// PCA 를 활용
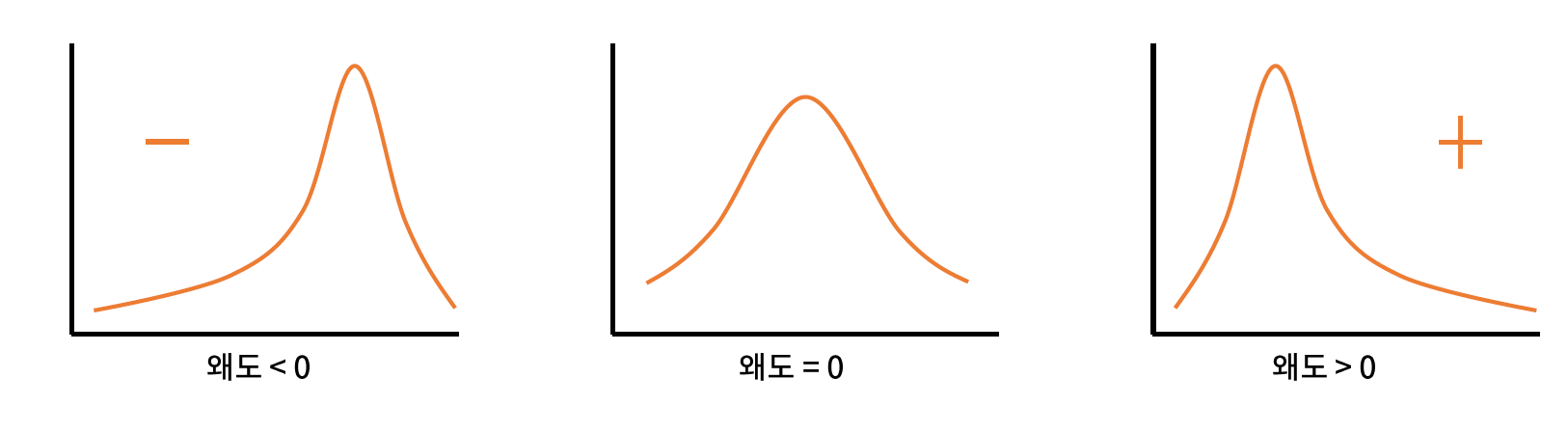
[05. Part 5) Ch 19. 이상적인 분포를 만들순 없을까 변수 분포 문제 - 05. 변수 치우침 제거]
For normally distributed data, the skewness should be about zero. For unimodal continuous distributions, a skewness value greater than zero means that there is more weight in the right tail of the distribution. The functionskewtestcan be used to determine if the skewness value is close enough to zero, statistically speaking.
Parameters
andarray
Input array.
axisint or None, optional
Axis along which skewness is calculated. Default is 0. If None, compute over the whole arraya.
biasbool, optional
If False, then the calculations are corrected for statistical bias.
Compute the kurtosis (Fisher or Pearson) of a dataset.
Kurtosis is the fourth central moment divided by the square of the variance. If Fisher’s definition is used, then 3.0 is subtracted from the result to give 0.0 for a normal distribution.
If bias is False then the kurtosis is calculated using k statistics to eliminate bias coming from biased moment estimators
Usekurtosistestto see if result is close enough to normal.
Parameters
aarray
Data for which the kurtosis is calculated.
axisint or None, optional
Axis along which the kurtosis is calculated. Default is 0. If None, compute over the whole arraya.
fisherbool, optional
If True, Fisher’s definition is used (normal ==> 0.0). If False, Pearson’s definition is used (normal ==> 3.0).
biasbool, optional
If False, then the calculations are corrected for statistical bias.
Defines how to handle when input contains nan. ‘propagate’ returns nan, ‘raise’ throws an error, ‘omit’ performs the calculations ignoring nan values. Default is ‘propagate’.
Returns
kurtosisarray
The kurtosis of values along an axis. If all values are equal, return -3 for Fisher’s definition and 0 for Pearson’s definition.
[05. Part 5) Ch 19. 이상적인 분포를 만들순 없을까 변수 분포 문제 - 06. 스케일링]
class sklearn.preprocessing.StandardScaler(*, copy=True, with_mean=True, with_std=True)
Standardize features by removing the mean and scaling to unit variance
The standard score of a samplexis calculated as:
z = (x - u) / s
whereuis the mean of the training samples or zero ifwith_mean=False, andsis the standard deviation of the training samples or one ifwith_std=False.
Centering and scaling happen independently on each feature by computing the relevant statistics on the samples in the training set. Mean and standard deviation are then stored to be used on later data usingtransform.
Standardization of a dataset is a common requirement for many machine learning estimators: they might behave badly if the individual features do not more or less look like standard normally distributed data (e.g. Gaussian with 0 mean and unit variance).
For instance many elements used in the objective function of a learning algorithm (such as the RBF kernel of Support Vector Machines or the L1 and L2 regularizers of linear models) assume that all features are centered around 0 and have variance in the same order. If a feature has a variance that is orders of magnitude larger that others, it might dominate the objective function and make the estimator unable to learn from other features correctly as expected.
This scaler can also be applied to sparse CSR or CSC matrices by passingwith_mean=Falseto avoid breaking the sparsity structure of the data.
If False, try to avoid a copy and do inplace scaling instead. This is not guaranteed to always work inplace; e.g. if the data is not a NumPy array or scipy.sparse CSR matrix, a copy may still be returned.
with_meanboolean, True by default
If True, center the data before scaling. This does not work (and will raise an exception) when attempted on sparse matrices, because centering them entails building a dense matrix which in common use cases is likely to be too large to fit in memory.
with_stdboolean, True by default
If True, scale the data to unit variance (or equivalently, unit standard deviation).
Attributes
scale_ndarray or None, shape (n_features,)
Per feature relative scaling of the data. This is calculated usingnp.sqrt(var_). Equal toNonewhenwith_std=False.
New in version 0.17:scale_
mean_ndarray or None, shape (n_features,)
The mean value for each feature in the training set. Equal toNonewhenwith_mean=False.
var_ndarray or None, shape (n_features,)
The variance for each feature in the training set. Used to computescale_. Equal toNonewhenwith_std=False.
n_samples_seen_int or array, shape (n_features,)
The number of samples processed by the estimator for each feature. If there are not missing samples, then_samples_seenwill be an integer, otherwise it will be an array. Will be reset on new calls to fit, but increments acrosspartial_fitcalls.
[파이썬을 활용한 데이터 전처리 Level UP-Comment] - 범주형 변수 문자에 대한 처리 방법
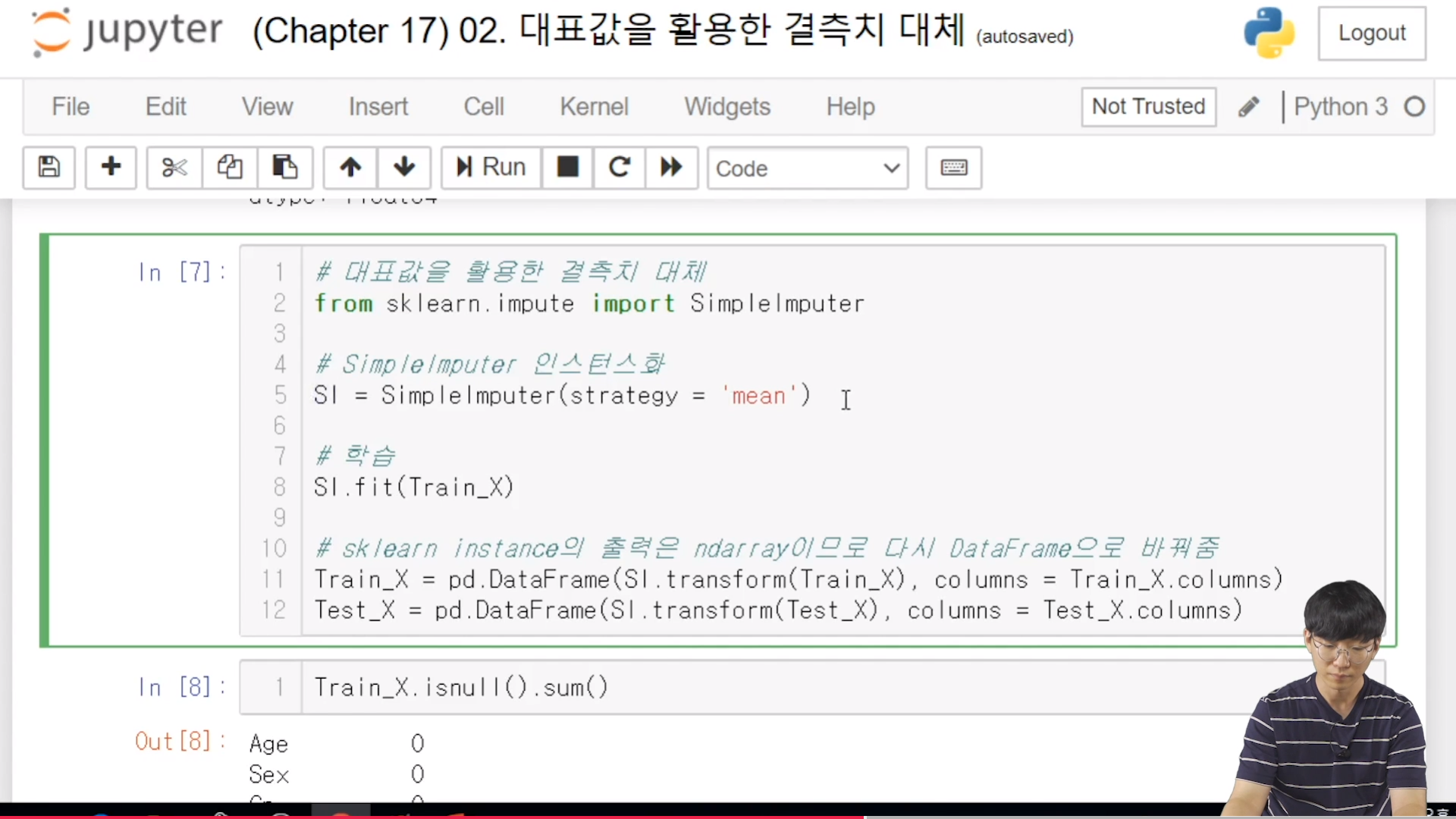
New in version 0.20:SimpleImputerreplaces the previoussklearn.preprocessing.Imputerestimator which is now removed.
Parameters
missing_valuesnumber, string, np.nan (default) or None
The placeholder for the missing values. All occurrences ofmissing_valueswill be imputed. For pandas’ dataframes with nullable integer dtypes with missing values,missing_valuesshould be set tonp.nan, sincepd.NAwill be converted tonp.nan.
strategystring, default=’mean’
The imputation strategy.
If “mean”, then replace missing values using the mean along each column. Can only be used with numeric data.
If “median”, then replace missing values using the median along each column. Can only be used with numeric data.
If “most_frequent”, then replace missing using the most frequent value along each column. Can be used with strings or numeric data.
If “constant”, then replace missing values with fill_value. Can be used with strings or numeric data.
New in version 0.20:strategy=”constant” for fixed value imputation.
fill_valuestring or numerical value, default=None
When strategy == “constant”, fill_value is used to replace all occurrences of missing_values. If left to the default, fill_value will be 0 when imputing numerical data and “missing_value” for strings or object data types.
verboseinteger, default=0
Controls the verbosity of the imputer.
copyboolean, default=True
If True, a copy of X will be created. If False, imputation will be done in-place whenever possible. Note that, in the following cases, a new copy will always be made, even ifcopy=False:
If X is not an array of floating values;
If X is encoded as a CSR matrix;
If add_indicator=True.
add_indicatorboolean, default=False
If True, aMissingIndicatortransform will stack onto output of the imputer’s transform. This allows a predictive estimator to account for missingness despite imputation. If a feature has no missing values at fit/train time, the feature won’t appear on the missing indicator even if there are missing values at transform/test time.
Attributes
statistics_array of shape (n_features,)
The imputation fill value for each feature. Computing statistics can result innp.nanvalues. Duringtransform, features corresponding tonp.nanstatistics will be discarded.
Value to use to fill holes (e.g. 0), alternately a dict/Series/DataFrame of values specifying which value to use for each index (for a Series) or column (for a DataFrame). Values not in the dict/Series/DataFrame will not be filled. This value cannot be a list.
Method to use for filling holes in reindexed Series pad / ffill: propagate last valid observation forward to next valid backfill / bfill: use next valid observation to fill gap.
axis{0 or ‘index’, 1 or ‘columns’}
Axis along which to fill missing values.
inplacebool, default False
If True, fill in-place. Note: this will modify any other views on this object (e.g., a no-copy slice for a column in a DataFrame).
limitint, default None
If method is specified, this is the maximum number of consecutive NaN values to forward/backward fill. In other words, if there is a gap with more than this number of consecutive NaNs, it will only be partially filled. If method is not specified, this is the maximum number of entries along the entire axis where NaNs will be filled. Must be greater than 0 if not None.
downcastdict, default is None
A dict of item->dtype of what to downcast if possible, or the string ‘infer’ which will try to downcast to an appropriate equal type (e.g. float64 to int64 if possible).
Returns
DataFrame or None
Object with missing values filled or None ifinplace=True.
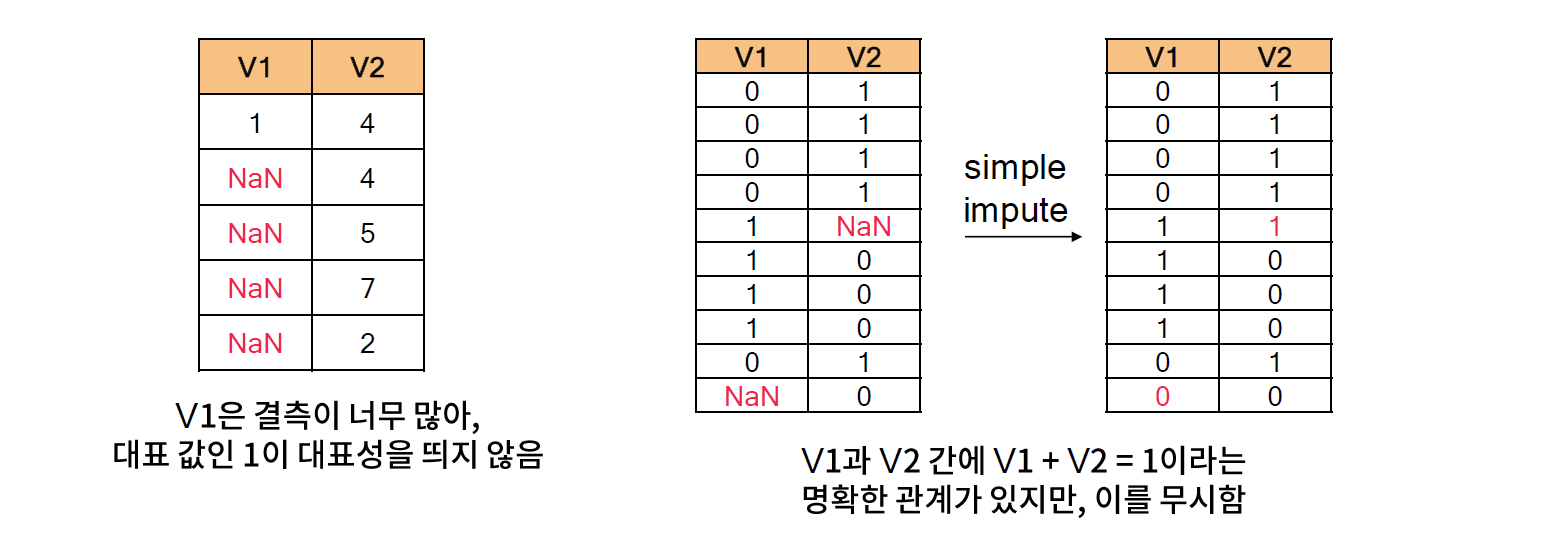
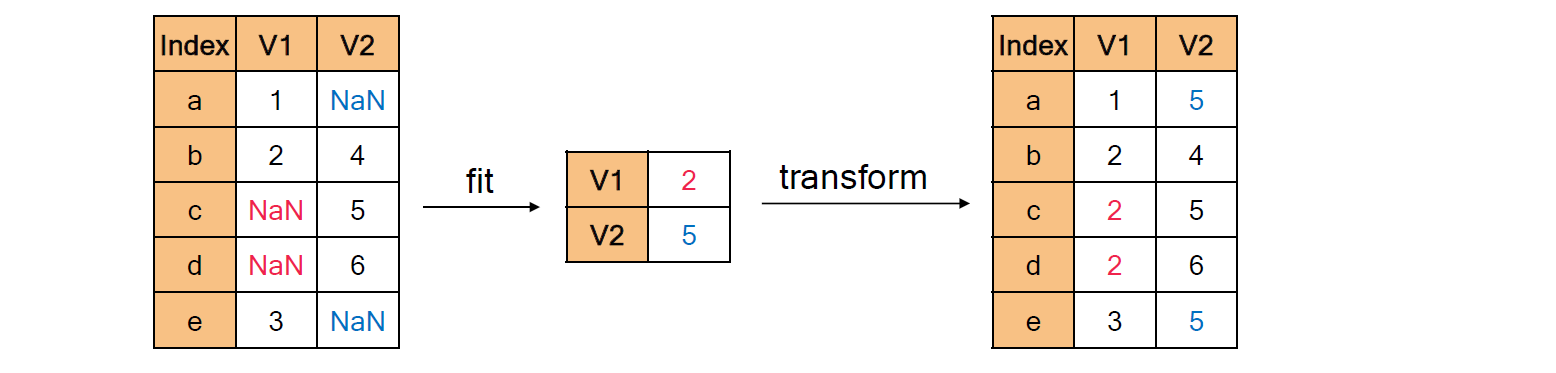
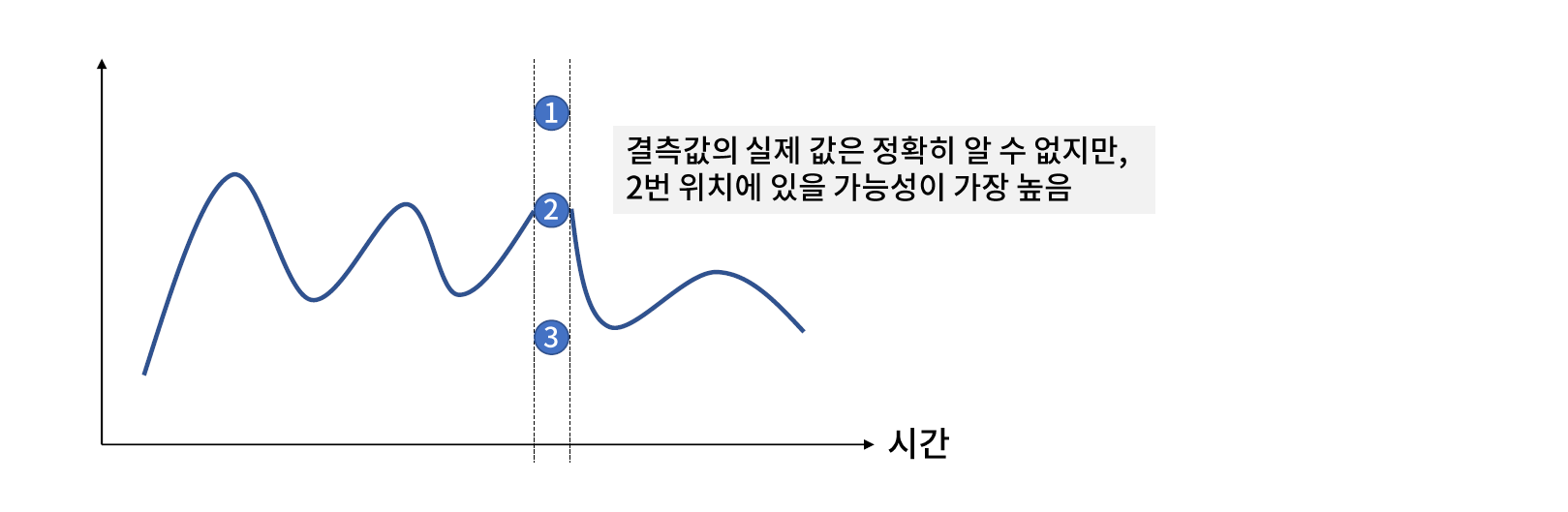
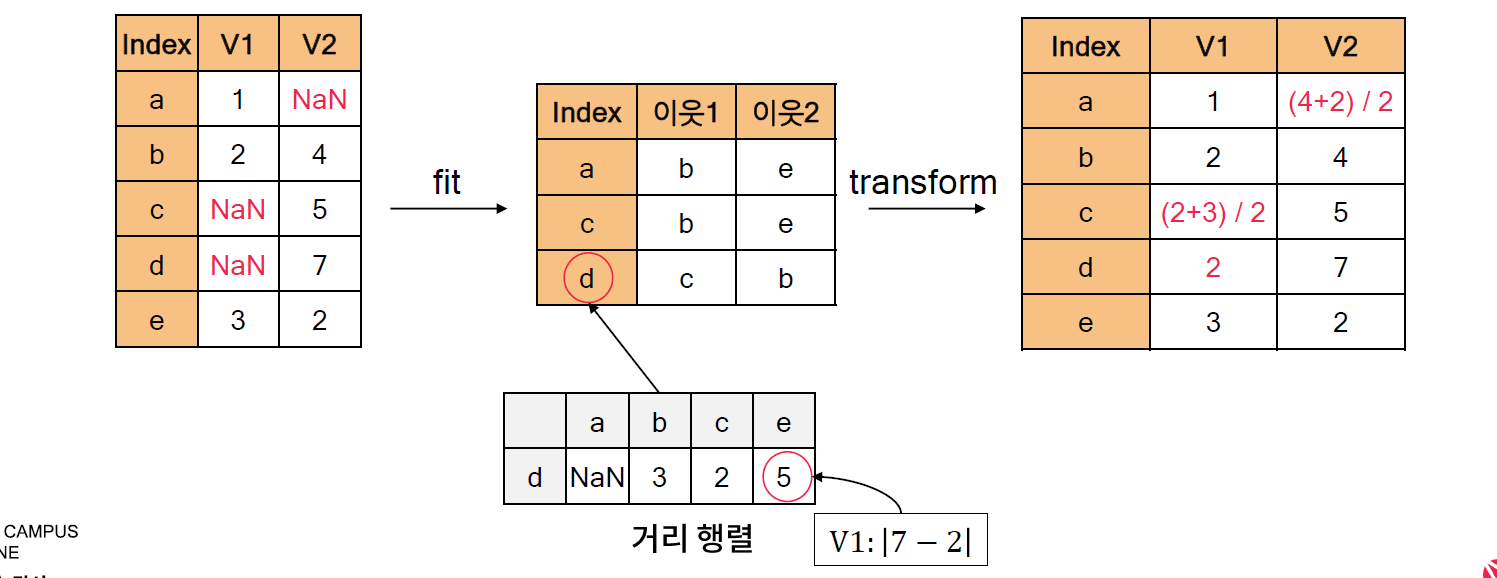
[04. Part 4) Ch 17. 왜 여기엔 값이 없을까 결측치 문제 - 03. 해결 방법 (4) 결측치 예측 모델 활용]
* 결측치 예측 모델 정의
- 결측이 발생하지 않은 컬럼을 바탕으로 결측치를 예측하는 모델을 학습하고 활용하는 방법
- (예시) V2 열에 포함된 결측 값을 추정
* 결측치 예측 모델 활용
- 결측치 예측 모델은 어느 상황에서도 무난하게 활용할 수 있으나, 사용 조건 및 단점을 반드시 숙지해야 한다.
- 사용 조건 및 단점
. 조건 1. 결측이 소수 컬럼에 쏠리면 안 된다.
. 조건 2. 특징 간에 관계가 존재해야 한다.
. 단점 : 다른 결측치 처리 방법에 비해 시간이 오래 소요된다.
* 관련문법 : sklearn.impute.KNNImputer
- 결측이 아닌 값만 사용하여 이웃을 구한 뒤, 이웃들의 값의 대표값으로 결측을 대체하는 결측치 예측 모델
- 주요 입력
. n_neighbors : 이웃 수 (주의 : 너무 적으면 결측 대체가 정상적으로 이뤄지지 않을 수 있으므로, 5 정도가 적절)
* 실습
// n_neighbors = 5 는 크게 잡는것 보다 적당한 수치로 잡아서 인스턴스화 작업을 한다.
class sklearn.impute.KNNImputer(*, missing_values=nan, n_neighbors=5, weights='uniform', metric='nan_euclidean', copy=True, add_indicator=False)
Imputation for completing missing values using k-Nearest Neighbors.
Each sample’s missing values are imputed using the mean value fromn_neighborsnearest neighbors found in the training set. Two samples are close if the features that neither is missing are close.
missing_valuesnumber, string, np.nan or None, default=`np.nan`
The placeholder for the missing values. All occurrences ofmissing_valueswill be imputed. For pandas’ dataframes with nullable integer dtypes with missing values,missing_valuesshould be set tonp.nan, sincepd.NAwill be converted tonp.nan.
n_neighborsint, default=5
Number of neighboring samples to use for imputation.
weights{‘uniform’, ‘distance’} or callable, default=’uniform’
Weight function used in prediction. Possible values:
‘uniform’ : uniform weights. All points in each neighborhood are weighted equally.
‘distance’ : weight points by the inverse of their distance. in this case, closer neighbors of a query point will have a greater influence than neighbors which are further away.
callable : a user-defined function which accepts an array of distances, and returns an array of the same shape containing the weights.
metric{‘nan_euclidean’} or callable, default=’nan_euclidean’
Distance metric for searching neighbors. Possible values:
‘nan_euclidean’
callable : a user-defined function which conforms to the definition of_pairwise_callable(X,Y,metric,**kwds). The function accepts two arrays, X and Y, and amissing_valueskeyword inkwdsand returns a scalar distance value.
copybool, default=True
If True, a copy of X will be created. If False, imputation will be done in-place whenever possible.
add_indicatorbool, default=False
If True, aMissingIndicatortransform will stack onto the output of the imputer’s transform. This allows a predictive estimator to account for missingness despite imputation. If a feature has no missing values at fit/train time, the feature won’t appear on the missing indicator even if there are missing values at transform/test time.
Group DataFrame using a mapper or by a Series of columns.
A groupby operation involves some combination of splitting the object, applying a function, and combining the results. This can be used to group large amounts of data and compute operations on these groups.
Parameters
bymapping, function, label, or list of labels
Used to determine the groups for the groupby. Ifbyis a function, it’s called on each value of the object’s index. If a dict or Series is passed, the Series or dict VALUES will be used to determine the groups (the Series’ values are first aligned; see.align()method). If an ndarray is passed, the values are used as-is determine the groups. A label or list of labels may be passed to group by the columns inself. Notice that a tuple is interpreted as a (single) key.
axis{0 or ‘index’, 1 or ‘columns’}, default 0
Split along rows (0) or columns (1).
levelint, level name, or sequence of such, default None
If the axis is a MultiIndex (hierarchical), group by a particular level or levels.
as_indexbool, default True
For aggregated output, return object with group labels as the index. Only relevant for DataFrame input. as_index=False is effectively “SQL-style” grouped output.
sortbool, default True
Sort group keys. Get better performance by turning this off. Note this does not influence the order of observations within each group. Groupby preserves the order of rows within each group.
group_keysbool, default True
When calling apply, add group keys to index to identify pieces.
squeezebool, default False
Reduce the dimensionality of the return type if possible, otherwise return a consistent type.
Deprecated since version 1.1.0.
observedbool, default False
This only applies if any of the groupers are Categoricals. If True: only show observed values for categorical groupers. If False: show all values for categorical groupers.
New in version 0.23.0.
dropnabool, default True
If True, and if group keys contain NA values, NA values together with row/column will be dropped. If False, NA values will also be treated as the key in groups
New in version 1.1.0.
Returns
DataFrameGroupBy
Returns a groupby object that contains information about the groups.
[04. Part 4) Ch 17. 왜 여기엔 값이 없을까 결측치 문제 - 01. 문제 정의]
* 문제 정의
- 데이터에 결측치가 있어, 모델 학습 자체가 되지 않는 문제
- 결측치는 크게 NaN 과 None 으로 구분된다.
. NaN : 값이 있어야 하는데 없는 결측으로, 대체, 추정, 예측 등으로 처리
. None : 값이 없는게 값인 결측 (e.g., 직업 - 백수) 으로 새로운 값으로 정의하는 방식으로 처리
- 결측치 처리 방법 자체는 매우 간단하나, 상황에 따른 처리 방법 선택이 매우 중요
* 용어 정의
- 결측 레코드 : 결측치를 포함하는 레코드
- 결측치 비율 : 결측 레코드 수 / 전체 레코드 개수
[04. Part 4) Ch 17. 왜 여기엔 값이 없을까 결측치 문제 - 02. 해결 방법 (1) 삭제]
* 행 단위 결측 삭제
- 행 단위 결측 삭제는 결측 레코드를 삭제하는 매우 간단한 방법이지만, 두 가지 조건을 만족하는 경우에만 수행할 수 있다.
* 열 단위 결측 삭제
- 열 다누이 결측 삭제는 결측 레코드를 포함하는 열을 삭제하는 매우 간단한 방법이지만, 두 가지 조건을 만족하는 경우에만 사용 가능하다.
. 소수 변수에 결측이 많이 포함되어 있다.
. 해당 변수들이 크게 중요하지 않음 (by 도메인 지식)
* 관련 문법 : Series / DataFrame.isnull
- 값이 결측이면 True 를, 그렇지 않으면 False 를 반환 (notnull 함수와 반대로 작동)
- sum 함수와 같이 사용하여 결측치 분포를 확인하는데 주로 사용
* 관련문법 : DataFrame.dropna
- 결측치가 포함된 행이나 열을 제거하는데 사용
- 주요 입력
. axis : 1 이면 결측이 포함된 열을 삭제하며, 0 이면 결측이 포함된 행을 삭제
. how : 'any'면 결측이 하나라도 포함되면 삭제하며, 'all'이면 모든 갑싱 결측인 경우만 삭제 (주로 any 로 설정)
Return a boolean same-sized object indicating if the values are NA. NA values, such as None ornumpy.NaN, gets mapped to True values. Everything else gets mapped to False values. Characters such as empty strings''ornumpy.infare not considered NA values (unless you setpandas.options.mode.use_inf_as_na=True).
ReturnsDataFrame
Mask of bool values for each element in DataFrame that indicates whether an element is not an NA value.
Return a boolean same-sized object indicating if the values are NA. NA values, such as None ornumpy.NaN, gets mapped to True values. Everything else gets mapped to False values. Characters such as empty strings''ornumpy.infare not considered NA values (unless you setpandas.options.mode.use_inf_as_na=True).
ReturnsSeries
Mask of bool values for each element in Series that indicates whether an element is not an NA value.
Convert Series to {label -> value} dict or dict-like object.
Parameters
intoclass, default dict
The collections.abc.Mapping subclass to use as the return object. Can be the actual class or an empty instance of the mapping type you want. If you want a collections.defaultdict, you must pass it initialized.
Values of the Series are replaced with other values dynamically. This differs from updating with.locor.iloc, which require you to specify a location to update with some value.
Parameters
to_replacestr, regex, list, dict, Series, int, float, or None
How to find the values that will be replaced.
numeric, str or regex:
numeric: numeric values equal toto_replacewill be replaced withvalue
str: string exactly matchingto_replacewill be replaced withvalue
regex: regexs matchingto_replacewill be replaced withvalue
list of str, regex, or numeric:
First, ifto_replaceandvalueare both lists, theymustbe the same length.
Second, ifregex=Truethen all of the strings inbothlists will be interpreted as regexs otherwise they will match directly. This doesn’t matter much forvaluesince there are only a few possible substitution regexes you can use.
str, regex and numeric rules apply as above.
dict:
Dicts can be used to specify different replacement values for different existing values. For example,{'a':'b','y':'z'}replaces the value ‘a’ with ‘b’ and ‘y’ with ‘z’. To use a dict in this way thevalueparameter should beNone.
For a DataFrame a dict can specify that different values should be replaced in different columns. For example,{'a':1,'b':'z'}looks for the value 1 in column ‘a’ and the value ‘z’ in column ‘b’ and replaces these values with whatever is specified invalue. Thevalueparameter should not beNonein this case. You can treat this as a special case of passing two lists except that you are specifying the column to search in.
For a DataFrame nested dictionaries, e.g.,{'a':{'b':np.nan}}, are read as follows: look in column ‘a’ for the value ‘b’ and replace it with NaN. Thevalueparameter should beNoneto use a nested dict in this way. You can nest regular expressions as well. Note that column names (the top-level dictionary keys in a nested dictionary)cannotbe regular expressions.
None:
This means that theregexargument must be a string, compiled regular expression, or list, dict, ndarray or Series of such elements. Ifvalueis alsoNonethen thismustbe a nested dictionary or Series.
See the examples section for examples of each of these.
valuescalar, dict, list, str, regex, default None
Value to replace any values matchingto_replacewith. For a DataFrame a dict of values can be used to specify which value to use for each column (columns not in the dict will not be filled). Regular expressions, strings and lists or dicts of such objects are also allowed.
inplacebool, default False
If True, in place. Note: this will modify any other views on this object (e.g. a column from a DataFrame). Returns the caller if this is True.
limitint, default None
Maximum size gap to forward or backward fill.
regexbool or same types asto_replace, default False
Whether to interpretto_replaceand/orvalueas regular expressions. If this isTruethento_replacemustbe a string. Alternatively, this could be a regular expression or a list, dict, or array of regular expressions in which caseto_replacemust beNone.
method{‘pad’, ‘ffill’, ‘bfill’,None}
The method to use when for replacement, whento_replaceis a scalar, list or tuple andvalueisNone.
Changed in version 0.23.0:Added to DataFrame.
Returns
Series
Object after replacement.
Raises
AssertionError
Ifregexis not aboolandto_replaceis notNone.
TypeError
Ifto_replaceis not a scalar, array-like,dict, orNone
Ifto_replaceis adictandvalueis not alist,dict,ndarray, orSeries
Ifto_replaceisNoneandregexis not compilable into a regular expression or is a list, dict, ndarray, or Series.
When replacing multipleboolordatetime64objects and the arguments toto_replacedoes not match the type of the value being replaced
ValueError
If alistor anndarrayis passed toto_replaceandvaluebut they are not the same length.
Concatenate pandas objects along a particular axis with optional set logic along the other axes.
Can also add a layer of hierarchical indexing on the concatenation axis, which may be useful if the labels are the same (or overlapping) on the passed axis number.
Parameters
objsa sequence or mapping of Series or DataFrame objects
If a mapping is passed, the sorted keys will be used as thekeysargument, unless it is passed, in which case the values will be selected (see below). Any None objects will be dropped silently unless they are all None in which case a ValueError will be raised.
axis{0/’index’, 1/’columns’}, default 0
The axis to concatenate along.
join{‘inner’, ‘outer’}, default ‘outer’
How to handle indexes on other axis (or axes).
ignore_indexbool, default False
If True, do not use the index values along the concatenation axis. The resulting axis will be labeled 0, …, n - 1. This is useful if you are concatenating objects where the concatenation axis does not have meaningful indexing information. Note the index values on the other axes are still respected in the join.
keyssequence, default None
If multiple levels passed, should contain tuples. Construct hierarchical index using the passed keys as the outermost level.
levelslist of sequences, default None
Specific levels (unique values) to use for constructing a MultiIndex. Otherwise they will be inferred from the keys.
nameslist, default None
Names for the levels in the resulting hierarchical index.
verify_integritybool, default False
Check whether the new concatenated axis contains duplicates. This can be very expensive relative to the actual data concatenation.
sortbool, default False
Sort non-concatenation axis if it is not already aligned whenjoinis ‘outer’. This has no effect whenjoin='inner', which already preserves the order of the non-concatenation axis.
New in version 0.23.0.
Changed in version 1.0.0:Changed to not sort by default.
copybool, default True
If False, do not copy data unnecessarily.
Returns
object, type of objs
When concatenating allSeriesalong the index (axis=0), aSeriesis returned. Whenobjscontains at least oneDataFrame, aDataFrameis returned. When concatenating along the columns (axis=1), aDataFrameis returned.
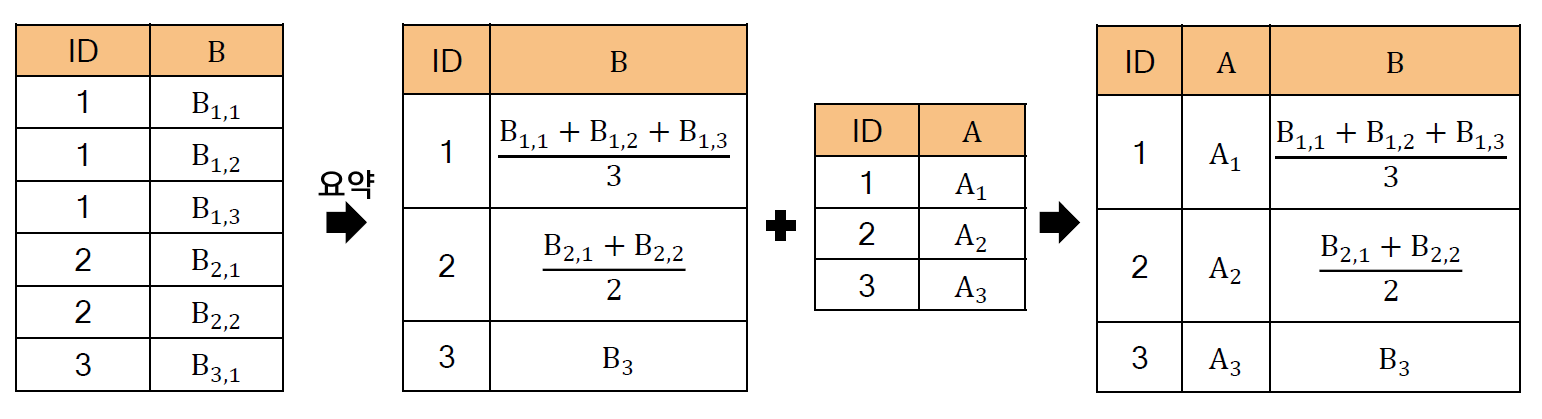
[04. Part 4) Ch 16. 흩어진 데이터 다 모여라 - 데이터 파편화 문제 - 02. 유형 (2) 명시적인 키 변수가 있는 경우]
* 문제 정의 및 해결 방안
- 효율적인 데이터 베이스 관리를 위해, 잘 정제된 데이터일지라도 데이터가 키 변수를 기준으로 나뉘어 저장되는 경우가 매우 흔함
- SQL 에서는 JOIN 을 이용하여 해결하며, python 에서는 merge 를 이용하여 해결한다.
- 일반적인 경우는 해결이 어렵지 않지만, 다양한 케이스가 존재할 수 있으므로 반드시 핵심을 기억해야 한다.
(1) 어느 컬럼이 키 변수 역할을 할 수 있는지 확인하고, 키 변수를 통일해야 한다.
(2) 레코드의 단위를 명확히 해야 한다.
* 관련문법 : pandas.merge
- 키 변수를 기준으루 두개의 데이터 프레임을 병합(join)하는 함수
- 주요입력
. left : 통합 대상 데이터 프레임 1
. right : 통합 대상 데이터 프레임 2
. on : 통합 기준 key 변수 및 변수 리스트 (입력을 하지 않으면, 이름이 같은 변수를 key 로 식별함) . left_on : 데이터 프레임 1의 key 변수 및 변수 리스트 . right_on : 데이터 프레임 2의 key 변수 및 변수 리스트 . left_index : 데이터 프레임 1의 인덱스를 key 변수로 사용할 지 여부 . right_index : 데이터 프레임 2의 인덱스를 key 변수로 사용할 지 여부
Merge DataFrame or named Series objects with a database-style join.
The join is done on columns or indexes. If joining columns on columns, the DataFrame indexeswill be ignored. Otherwise if joining indexes on indexes or indexes on a column or columns, the index will be passed on.
left: use only keys from left frame, similar to a SQL left outer join; preserve key order.
right: use only keys from right frame, similar to a SQL right outer join; preserve key order.
outer: use union of keys from both frames, similar to a SQL full outer join; sort keys lexicographically.
inner: use intersection of keys from both frames, similar to a SQL inner join; preserve the order of the left keys.
onlabel or list
Column or index level names to join on. These must be found in both DataFrames. Ifonis None and not merging on indexes then this defaults to the intersection of the columns in both DataFrames.
left_onlabel or list, or array-like
Column or index level names to join on in the left DataFrame. Can also be an array or list of arrays of the length of the left DataFrame. These arrays are treated as if they are columns.
right_onlabel or list, or array-like
Column or index level names to join on in the right DataFrame. Can also be an array or list of arrays of the length of the right DataFrame. These arrays are treated as if they are columns.
left_indexbool, default False
Use the index from the left DataFrame as the join key(s). If it is a MultiIndex, the number of keys in the other DataFrame (either the index or a number of columns) must match the number of levels.
right_indexbool, default False
Use the index from the right DataFrame as the join key. Same caveats as left_index.
sortbool, default False
Sort the join keys lexicographically in the result DataFrame. If False, the order of the join keys depends on the join type (how keyword).
suffixeslist-like, default is (“_x”, “_y”)
A length-2 sequence where each element is optionally a string indicating the suffix to add to overlapping column names inleftandrightrespectively. Pass a value ofNoneinstead of a string to indicate that the column name fromleftorrightshould be left as-is, with no suffix. At least one of the values must not be None.
copybool, default True
If False, avoid copy if possible.
indicatorbool or str, default False
If True, adds a column to the output DataFrame called “_merge” with information on the source of each row. The column can be given a different name by providing a string argument. The column will have a Categorical type with the value of “left_only” for observations whose merge key only appears in the left DataFrame, “right_only” for observations whose merge key only appears in the right DataFrame, and “both” if the observation’s merge key is found in both DataFrames.
validatestr, optional
If specified, checks if merge is of specified type.
“one_to_one” or “1:1”: check if merge keys are unique in both left and right datasets.
“one_to_many” or “1:m”: check if merge keys are unique in left dataset.
“many_to_one” or “m:1”: check if merge keys are unique in right dataset.
“many_to_many” or “m:m”: allowed, but does not result in checks.
Returns
DataFrame
A DataFrame of the two merged objects.
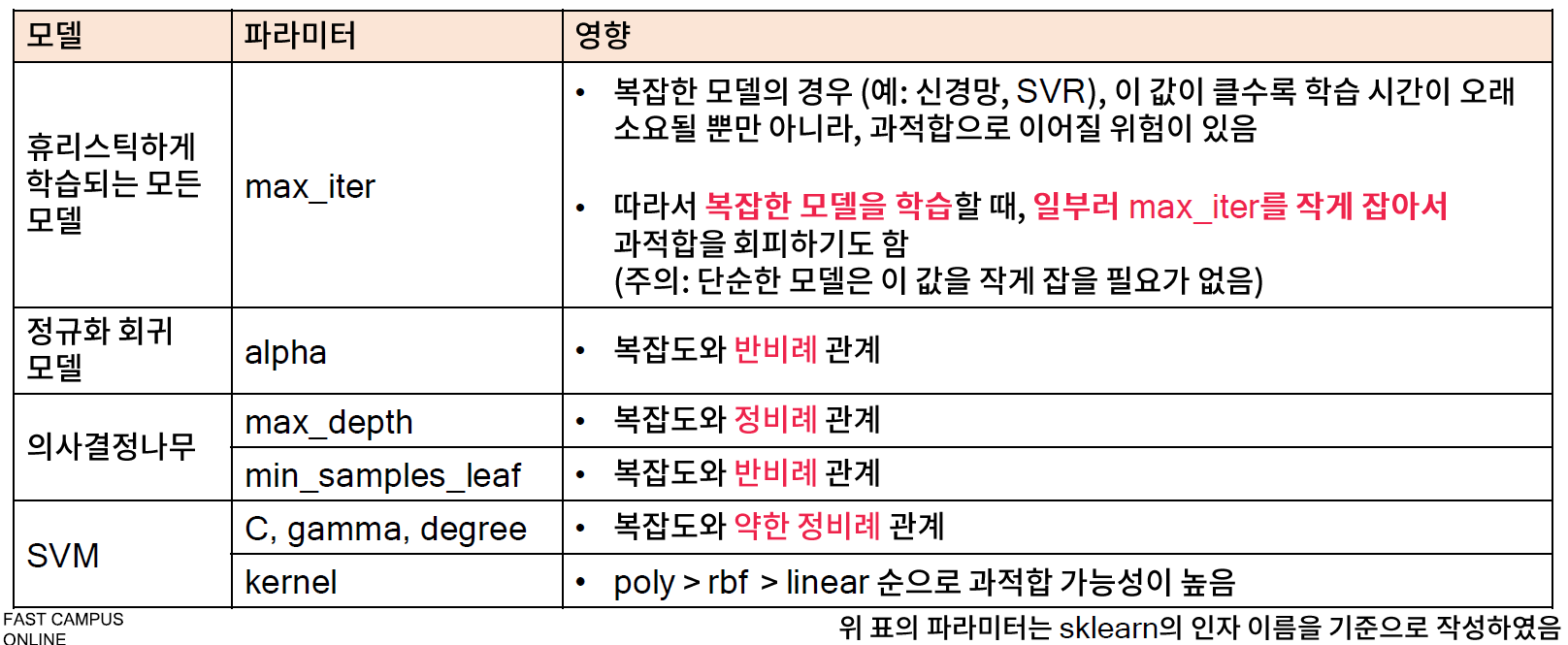
[파이썬을 활용한 데이터 전처리 Level UP-Comment] - 복잡도 파라미터 튜닝에서는 다양한 파라미터에 대해서 어떤식을 튜닝을 해야 되는지.. 단순하다고 나쁜 것도 아니고 복잡하다고 좋은 것도 아니라.. 그 상황에 맞는 경험치!!^^!!
- 데이터 합치 파트는 Chapter 4 에 나와 있는 함수들을 다시 한번 되돌아 볼 수 있는 기회였다.
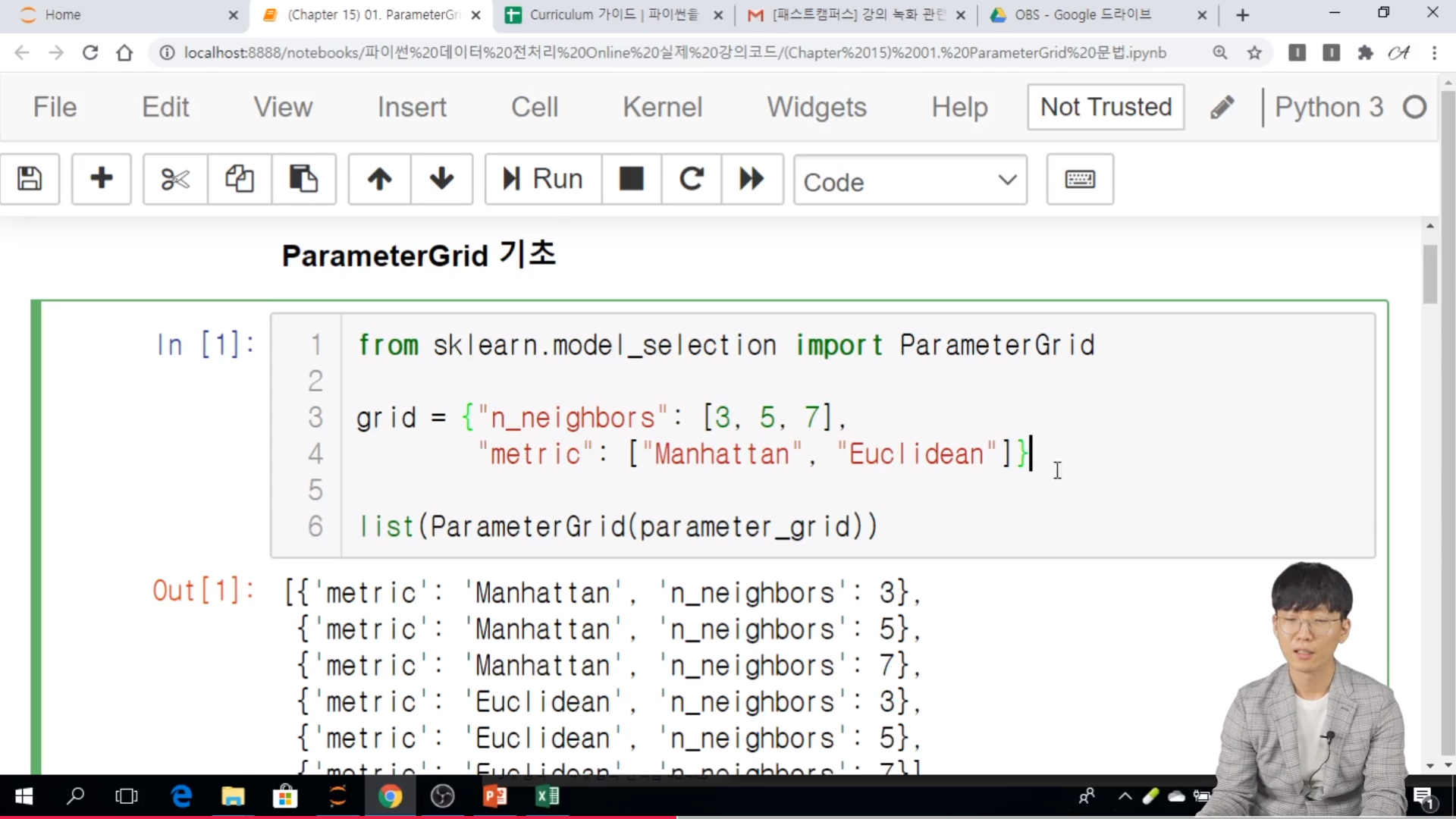
Exhaustive search over specified parameter values for an estimator.
Important members are fit, predict.
GridSearchCV implements a “fit” and a “score” method. It also implements “predict”, “predict_proba”, “decision_function”, “transform” and “inverse_transform” if they are implemented in the estimator used.
The parameters of the estimator used to apply these methods are optimized by cross-validated grid-search over a parameter grid.
This is assumed to implement the scikit-learn estimator interface. Either estimator needs to provide ascorefunction, orscoringmust be passed.
param_griddict or list of dictionaries
Dictionary with parameters names (str) as keys and lists of parameter settings to try as values, or a list of such dictionaries, in which case the grids spanned by each dictionary in the list are explored. This enables searching over any sequence of parameter settings.
scoringstr, callable, list/tuple or dict, default=None
For evaluating multiple metrics, either give a list of (unique) strings or a dict with names as keys and callables as values.
NOTE that when using custom scorers, each scorer should return a single value. Metric functions returning a list/array of values can be wrapped into multiple scorers that return one value each.
Number of jobs to run in parallel.Nonemeans 1 unless in ajoblib.parallel_backendcontext.-1means using all processors. SeeGlossaryfor more details.
Changed in version v0.20:n_jobsdefault changed from 1 to None
pre_dispatchint, or str, default=n_jobs
Controls the number of jobs that get dispatched during parallel execution. Reducing this number can be useful to avoid an explosion of memory consumption when more jobs get dispatched than CPUs can process. This parameter can be:
None, in which case all the jobs are immediately created and spawned. Use this for lightweight and fast-running jobs, to avoid delays due to on-demand spawning of the jobs
An int, giving the exact number of total jobs that are spawned
A str, giving an expression as a function of n_jobs, as in ‘2*n_jobs’
iidbool, default=False
If True, return the average score across folds, weighted by the number of samples in each test set. In this case, the data is assumed to be identically distributed across the folds, and the loss minimized is the total loss per sample, and not the mean loss across the folds.
Deprecated since version 0.22:Parameteriidis deprecated in 0.22 and will be removed in 0.24
cvint, cross-validation generator or an iterable, default=None
Determines the cross-validation splitting strategy. Possible inputs for cv are:
None, to use the default 5-fold cross validation,
integer, to specify the number of folds in a(Stratified)KFold,
An iterable yielding (train, test) splits as arrays of indices.
For integer/None inputs, if the estimator is a classifier andyis either binary or multiclass,StratifiedKFoldis used. In all other cases,KFoldis used.
ReferUser Guidefor the various cross-validation strategies that can be used here.
Changed in version 0.22:cvdefault value if None changed from 3-fold to 5-fold.
refitbool, str, or callable, default=True
Refit an estimator using the best found parameters on the whole dataset.
For multiple metric evaluation, this needs to be astrdenoting the scorer that would be used to find the best parameters for refitting the estimator at the end.
Where there are considerations other than maximum score in choosing a best estimator,refitcan be set to a function which returns the selectedbest_index_givencv_results_. In that case, thebest_estimator_andbest_params_will be set according to the returnedbest_index_while thebest_score_attribute will not be available.
The refitted estimator is made available at thebest_estimator_attribute and permits usingpredictdirectly on thisGridSearchCVinstance.
Also for multiple metric evaluation, the attributesbest_index_,best_score_andbest_params_will only be available ifrefitis set and all of them will be determined w.r.t this specific scorer.
Seescoringparameter to know more about multiple metric evaluation.
Changed in version 0.20:Support for callable added.
verboseinteger
Controls the verbosity: the higher, the more messages.
error_score‘raise’ or numeric, default=np.nan
Value to assign to the score if an error occurs in estimator fitting. If set to ‘raise’, the error is raised. If a numeric value is given, FitFailedWarning is raised. This parameter does not affect the refit step, which will always raise the error.
return_train_scorebool, default=False
IfFalse, thecv_results_attribute will not include training scores. Computing training scores is used to get insights on how different parameter settings impact the overfitting/underfitting trade-off. However computing the scores on the training set can be computationally expensive and is not strictly required to select the parameters that yield the best generalization performance.
New in version 0.19.
Changed in version 0.21:Default value was changed fromTruetoFalse
Attributes
cv_results_dict of numpy (masked) ndarrays
A dict with keys as column headers and values as columns, that can be imported into a pandasDataFrame.
The key'params'is used to store a list of parameter settings dicts for all the parameter candidates.
Themean_fit_time,std_fit_time,mean_score_timeandstd_score_timeare all in seconds.
For multi-metric evaluation, the scores for all the scorers are available in thecv_results_dict at the keys ending with that scorer’s name ('_<scorer_name>') instead of'_score'shown above. (‘split0_test_precision’, ‘mean_train_precision’ etc.)
best_estimator_estimator
Estimator that was chosen by the search, i.e. estimator which gave highest score (or smallest loss if specified) on the left out data. Not available ifrefit=False.
Seerefitparameter for more information on allowed values.
best_score_float
Mean cross-validated score of the best_estimator
For multi-metric evaluation, this is present only ifrefitis specified.
This attribute is not available ifrefitis a function.
best_params_dict
Parameter setting that gave the best results on the hold out data.
For multi-metric evaluation, this is present only ifrefitis specified.
best_index_int
The index (of thecv_results_arrays) which corresponds to the best candidate parameter setting.
The dict atsearch.cv_results_['params'][search.best_index_]gives the parameter setting for the best model, that gives the highest mean score (search.best_score_).
For multi-metric evaluation, this is present only ifrefitis specified.
scorer_function or a dict
Scorer function used on the held out data to choose the best parameters for the model.
For multi-metric evaluation, this attribute holds the validatedscoringdict which maps the scorer key to the scorer callable.
n_splits_int
The number of cross-validation splits (folds/iterations).
refit_time_float
Seconds used for refitting the best model on the whole dataset.
Parametersparam_griddict of str to sequence, or sequence of such
The parameter grid to explore, as a dictionary mapping estimator parameters to sequences of allowed values.
An empty dict signifies default parameters.
A sequence of dicts signifies a sequence of grids to search, and is useful to avoid exploring parameter combinations that make no sense or have no effect. See the examples below.
[03. Part 3) Ch 15. 이럴땐 이걸 쓰고, 저럴땐 저걸 쓰고 - 지도 학습 모델 & 파라미터 선택 - 02. 기준 (1) 변수 타입]
* 변수 타입 확인 방법
- DataGrame.dtypes
. DataFrame 에 포함된 컬럼들의 데이터 타입 ( object, int64, float64, bool 등 ) 을 반환
- DataFrame.infer_objects( ).dtypes
. DataFrame 에 포함된 컬럼들의 데이터 타입을 추론한 결과를 반환
. (예) ['1', '2'] 라는 값을 가진 컬럼은 비록 object 타입이나, int 타입이라고 추론할 수 있다.
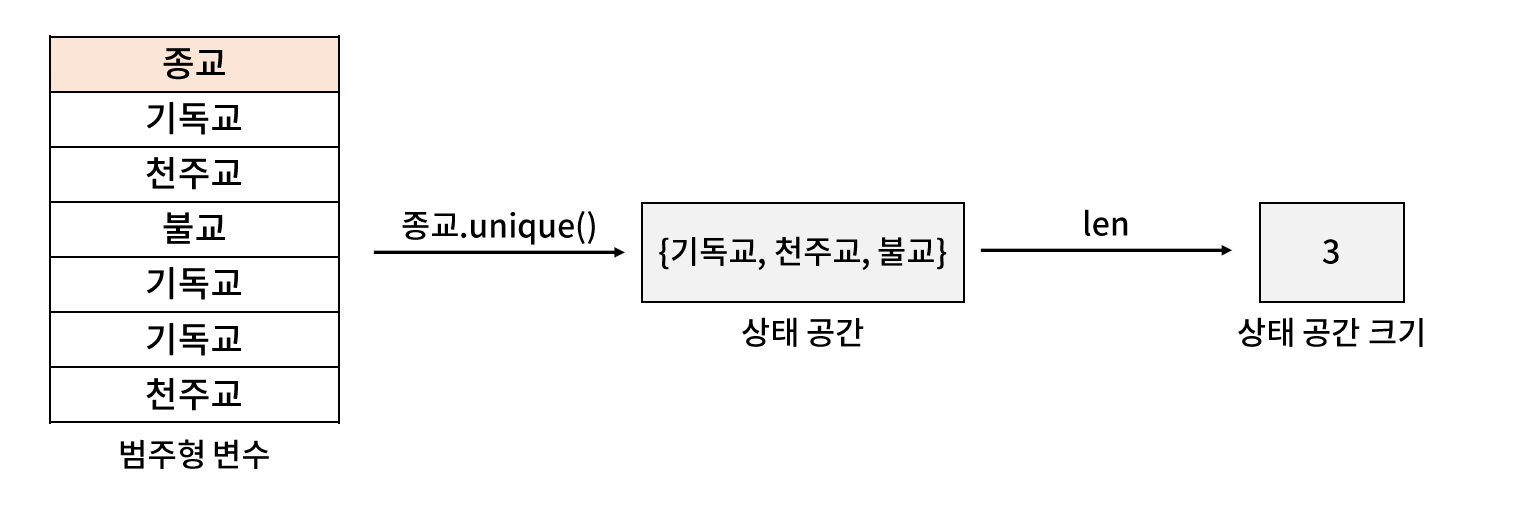
- 주의 : string type 이라고 해서 반드시 범주형이 아니며, int 혹은 float type 이라고 해서 반드시 연속형은 아니다. 반드시 상태 공간의 크기와 도메인 지식 등을 고려해야 한다.
* 변수 타입에 따른 적절한 모델
- 주의 : 모델 성능에는 변수 타입만 영향을 주는 것이 아니므로, 다른 요소도 반드시 고려해야 한다.
* 혼합형 변쉥 적절하지 않은 모델 (1) 회귀 모델
- 혼합형 변수인 경우에는 당연히 변수의 스케일 차이가 존재하는 경우가 흔하다.
- 변수의 스케일에 따라 계수 값이 크게 달라지므로, 예측 안정성이 크게 떨어진다.
. 모든 특징이 라벨에 독립적으로 영향을 준다면, 이진형 특징의 계수 절대값이 스케일이 큰 연속형 특징의 계수 절대값 보다 크게 설정된다.
. 이진형 특징 값에 따라 예측 값이 크게 변동한다.
- 스케일일ㅇ을 하더라도 이진형 특징의 분포가 변하지 않으므로, 이진형 특징의 값에 따른 영향력이 크게 줄지 않는다.
* 혼합형 변수에 적절하지 않은 모델 (2) 나이브 베이즈
- 나이브베이즈는 하나의 확률 분포를 가정하기 때문에, 혼합형 변수를 가지는 데이터에 부적절하다.
. (예시) 베르누이 분포는 연속형 값을 가지는 확률 분포 추정에 매우 부적절
- 따라서 나이브베이즈는 혼합형 변수인 경우에는 절대로 고려해서는 안 되는 모델이다.
* 혼합형 변수에 적절하지 않은 모델 (3) k - 최근접 이웃
- 스케일이 큰 변수에 의해 거리가 사실상 결정되므로, k-NN 은 혼합형 변수에 적절하지 않다.
- 단, 코사인 유사도를 사용하는 경우나, 스케일링을 적용하는 경우에는 큰 무리 없이 사용 가능하다.
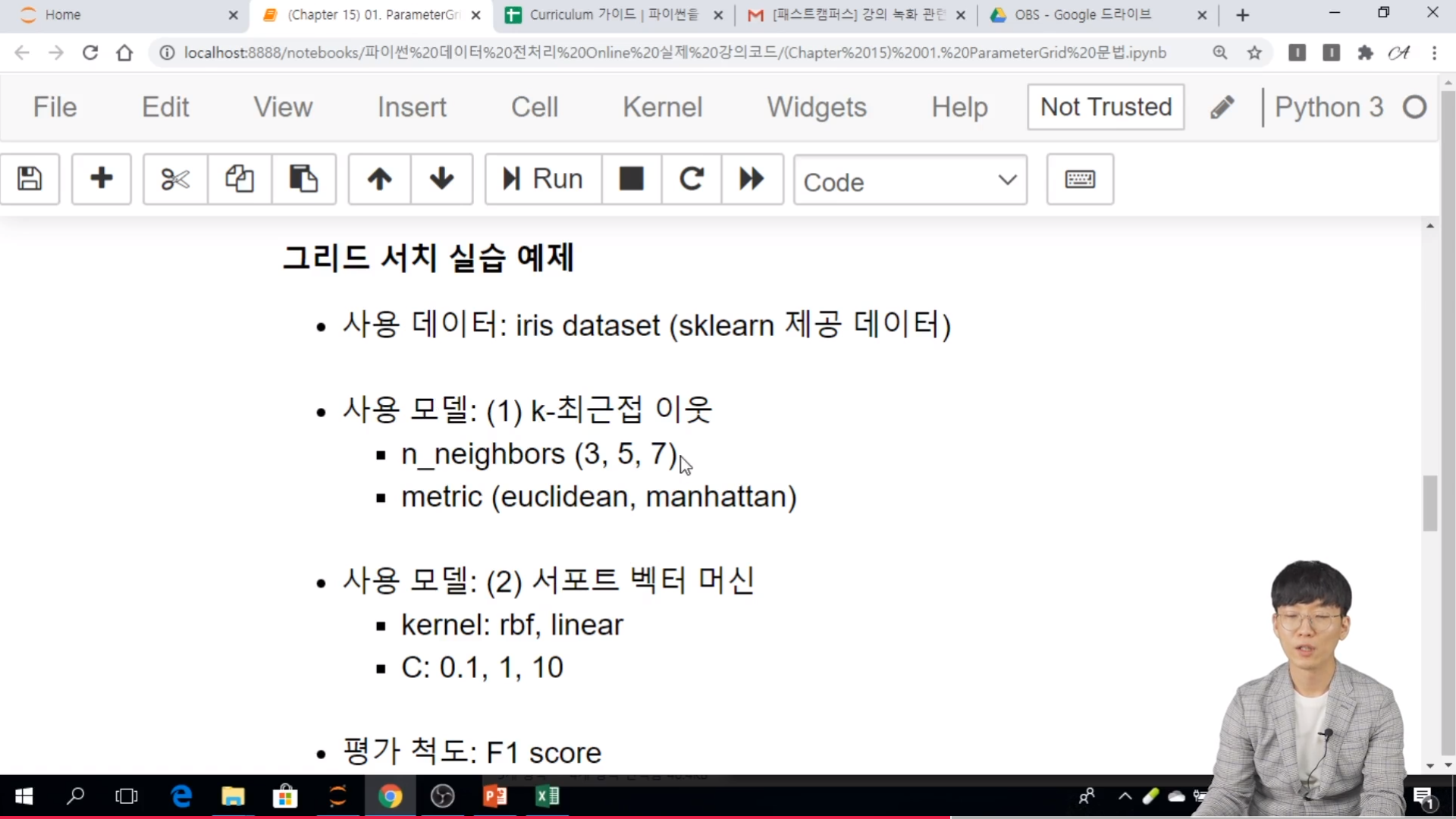
[03. Part 3) Ch 15. 이럴땐 이걸 쓰고, 저럴땐 저걸 쓰고 - 지도 학습 모델 & 파라미터 선택 - 03. 기준 (2) 데이터 크기]
* 샘플 개수와 특징 개수에 따른 과적합 (remind)
* 샘플 개수와 특징 개수에 따른 적절한 모델
* 실습
// random_state 가 있는 모델은 모두 같은 값으로 설정한다.
// 모델별 k 겹 교차 검증 기반 (k=5) 의 MAE 값으로 계산한다.
// cv 는 폴더의 갯수. k 값
// 특징이 적으면 복잡한 모델은 나오기 어렵다.
// 샘플이 매우 적고 특징이 상대적으로 많은 경우
[파이썬을 활용한 데이터 전처리 Level UP-Comment] - 지도학습할 때의 Grid 서치 및 parameterGrid 에 대해서 배울 수 있었다. 동영상 순서가 이상해서 처음엔 약간 이상했지만~^^;;
class sklearn.linear_model.LinearRegression(*, fit_intercept=True, normalize=False, copy_X=True, n_jobs=None)
Ordinary least squares Linear Regression.
LinearRegression fits a linear model with coefficients w = (w1, …, wp) to minimize the residual sum of squares between the observed targets in the dataset, and the targets predicted by the linear approximation.
Parameters
fit_interceptbool, default=True
Whether to calculate the intercept for this model. If set to False, no intercept will be used in calculations (i.e. data is expected to be centered).
normalizebool, default=False
This parameter is ignored whenfit_interceptis set to False. If True, the regressors X will be normalized before regression by subtracting the mean and dividing by the l2-norm. If you wish to standardize, please usesklearn.preprocessing.StandardScalerbefore callingfiton an estimator withnormalize=False.
copy_Xbool, default=True
If True, X will be copied; else, it may be overwritten.
n_jobsint, default=None
The number of jobs to use for the computation. This will only provide speedup for n_targets > 1 and sufficient large problems.Nonemeans 1 unless in ajoblib.parallel_backendcontext.-1means using all processors. SeeGlossaryfor more details.
Attributes
coef_array of shape (n_features, ) or (n_targets, n_features)
Estimated coefficients for the linear regression problem. If multiple targets are passed during the fit (y 2D), this is a 2D array of shape (n_targets, n_features), while if only one target is passed, this is a 1D array of length n_features.
rank_int
Rank of matrixX. Only available whenXis dense.
singular_array of shape (min(X, y),)
Singular values ofX. Only available whenXis dense.
intercept_float or array of shape (n_targets,)
Independent term in the linear model. Set to 0.0 iffit_intercept=False.
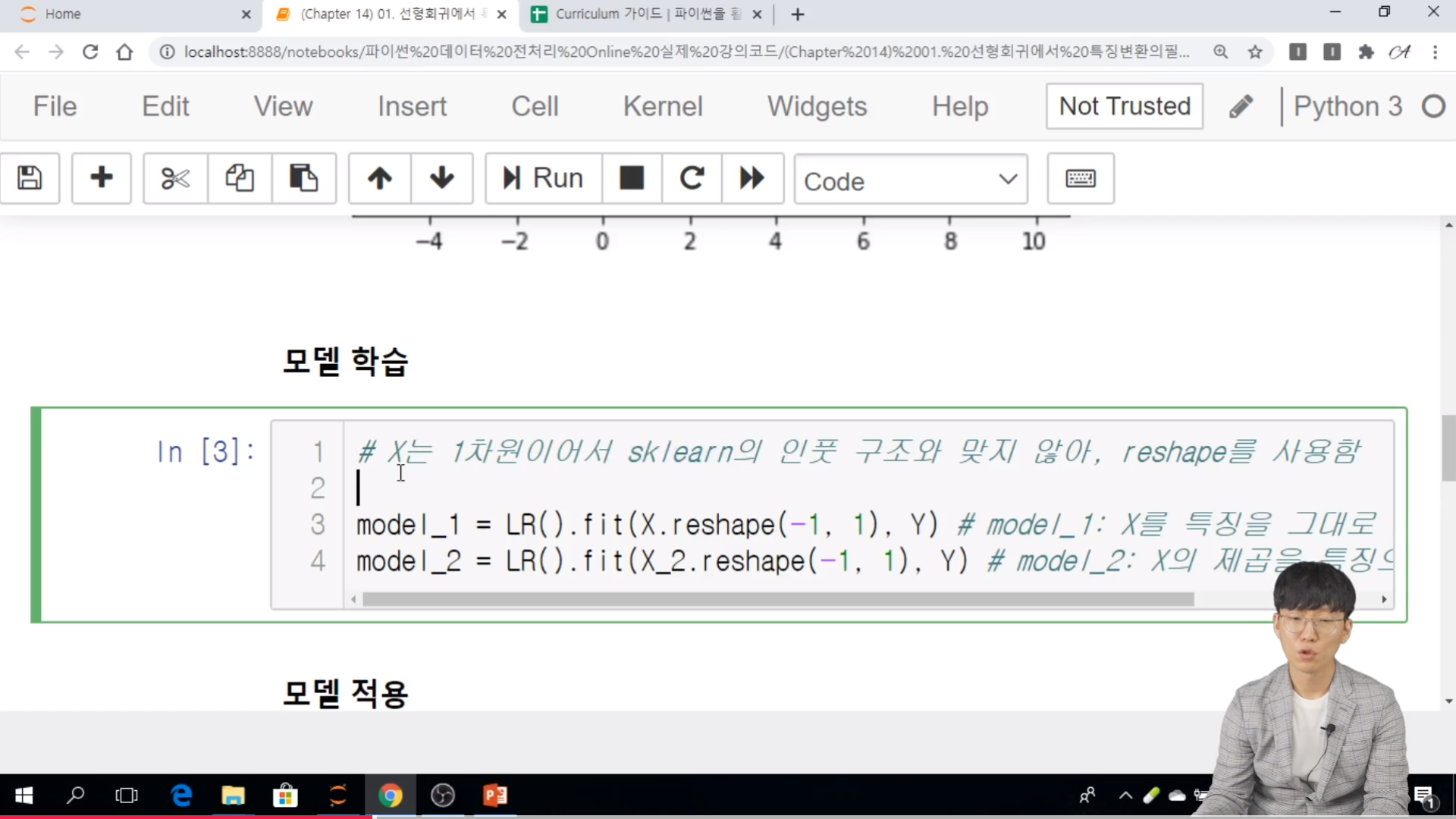
// X는 1차원이어서 sklean 의 인풋 구조와 맞지 않아, reshape를 사용한다.
// 1차원일 경우에는 X=[recod1, record2, ...]
// 학습데이터와 평가 데이터를 나눠야지 정확한 결과가 도출 될 수가 있다.
// 모델링 할 때는 스켈링이 반드시 필요하다.
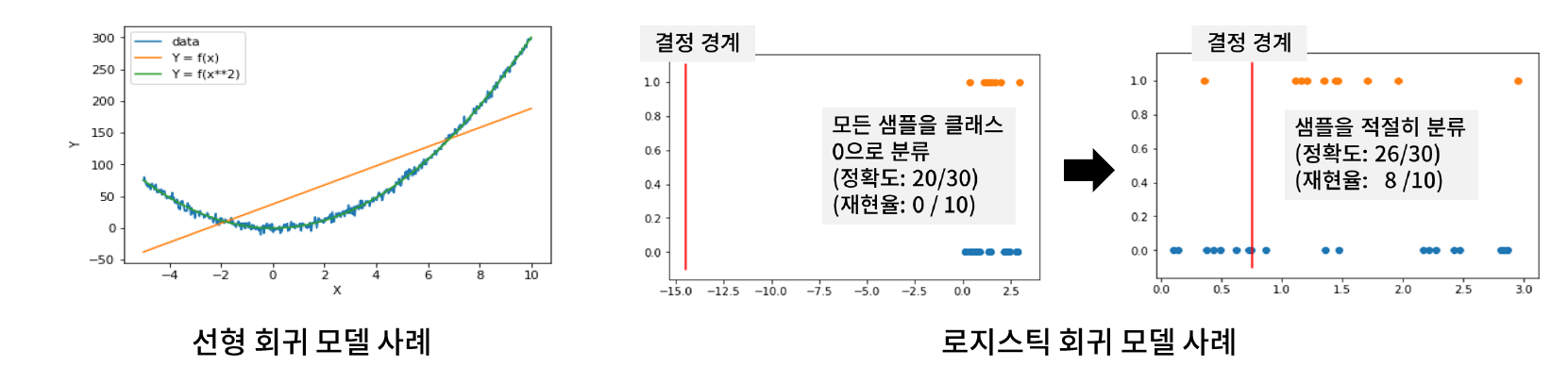
* 로지스틱 회귀 모델
// 회귀 모델이지만 분류에 쓰이는 모델이라고 보면 된다.
- 모델 구조
- 비용 함수 : 크로스 엔트로피
* 로지스틱 회귀 모델
// 결과적으로는 선형식이라고 보면 된다.
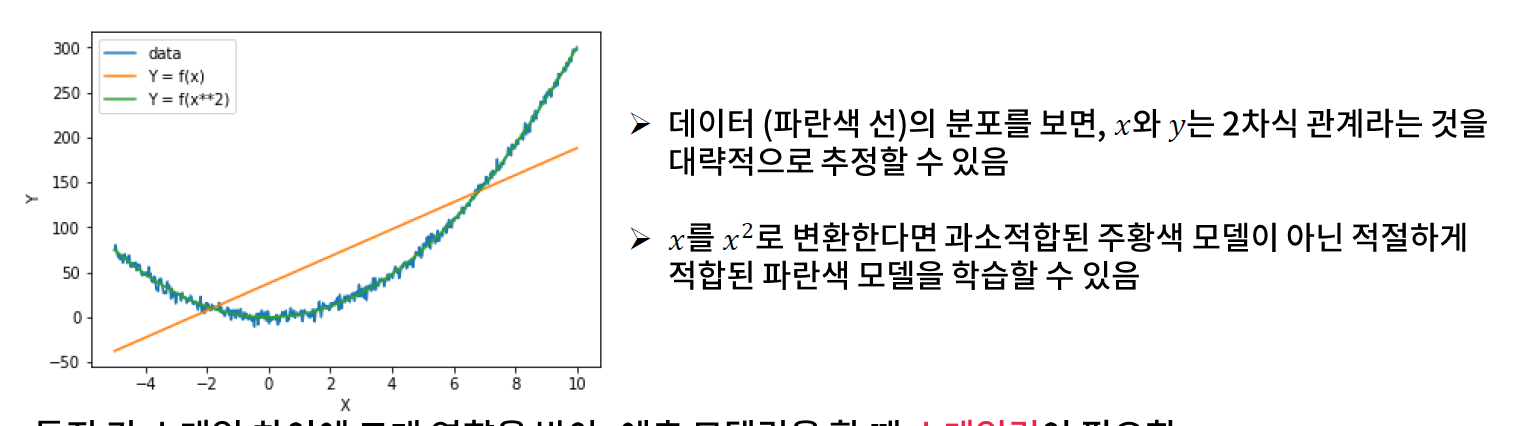
// 선형적인 것들은 아래와 같은 특징을 가진다.
- 특징의 구간별로 라벨의 분포가 달라지는 경우, 적절한 구간을 나타낼 수 있도록 특징 변환이 필요하다.
In the multiclass case, the training algorithm uses the one-vs-rest (OvR) scheme if the ‘multi_class’ option is set to ‘ovr’, and uses the cross-entropy loss if the ‘multi_class’ option is set to ‘multinomial’. (Currently the ‘multinomial’ option is supported only by the ‘lbfgs’, ‘sag’, ‘saga’ and ‘newton-cg’ solvers.)
This class implements regularized logistic regression using the ‘liblinear’ library, ‘newton-cg’, ‘sag’, ‘saga’ and ‘lbfgs’ solvers.Note that regularization is applied by default. It can handle both dense and sparse input. Use C-ordered arrays or CSR matrices containing 64-bit floats for optimal performance; any other input format will be converted (and copied).
The ‘newton-cg’, ‘sag’, and ‘lbfgs’ solvers support only L2 regularization with primal formulation, or no regularization. The ‘liblinear’ solver supports both L1 and L2 regularization, with a dual formulation only for the L2 penalty. The Elastic-Net regularization is only supported by the ‘saga’ solver.
Used to specify the norm used in the penalization. The ‘newton-cg’, ‘sag’ and ‘lbfgs’ solvers support only l2 penalties. ‘elasticnet’ is only supported by the ‘saga’ solver. If ‘none’ (not supported by the liblinear solver), no regularization is applied.
New in version 0.19:l1 penalty with SAGA solver (allowing ‘multinomial’ + L1)
dualbool, default=False
Dual or primal formulation. Dual formulation is only implemented for l2 penalty with liblinear solver. Prefer dual=False when n_samples > n_features.
tolfloat, default=1e-4
Tolerance for stopping criteria.
Cfloat, default=1.0
Inverse of regularization strength; must be a positive float. Like in support vector machines, smaller values specify stronger regularization.
fit_interceptbool, default=True
Specifies if a constant (a.k.a. bias or intercept) should be added to the decision function.
intercept_scalingfloat, default=1
Useful only when the solver ‘liblinear’ is used and self.fit_intercept is set to True. In this case, x becomes [x, self.intercept_scaling], i.e. a “synthetic” feature with constant value equal to intercept_scaling is appended to the instance vector. The intercept becomesintercept_scaling*synthetic_feature_weight.
Note! the synthetic feature weight is subject to l1/l2 regularization as all other features. To lessen the effect of regularization on synthetic feature weight (and therefore on the intercept) intercept_scaling has to be increased.
class_weightdict or ‘balanced’, default=None
Weights associated with classes in the form{class_label:weight}. If not given, all classes are supposed to have weight one.
The “balanced” mode uses the values of y to automatically adjust weights inversely proportional to class frequencies in the input data asn_samples/(n_classes*np.bincount(y)).
Note that these weights will be multiplied with sample_weight (passed through the fit method) if sample_weight is specified.
For small datasets, ‘liblinear’ is a good choice, whereas ‘sag’ and ‘saga’ are faster for large ones.
For multiclass problems, only ‘newton-cg’, ‘sag’, ‘saga’ and ‘lbfgs’ handle multinomial loss; ‘liblinear’ is limited to one-versus-rest schemes.
‘newton-cg’, ‘lbfgs’, ‘sag’ and ‘saga’ handle L2 or no penalty
‘liblinear’ and ‘saga’ also handle L1 penalty
‘saga’ also supports ‘elasticnet’ penalty
‘liblinear’ does not support settingpenalty='none'
Note that ‘sag’ and ‘saga’ fast convergence is only guaranteed on features with approximately the same scale. You can preprocess the data with a scaler from sklearn.preprocessing.
New in version 0.17:Stochastic Average Gradient descent solver.
New in version 0.19:SAGA solver.
Changed in version 0.22:The default solver changed from ‘liblinear’ to ‘lbfgs’ in 0.22.
max_iterint, default=100
Maximum number of iterations taken for the solvers to converge.
If the option chosen is ‘ovr’, then a binary problem is fit for each label. For ‘multinomial’ the loss minimised is the multinomial loss fit across the entire probability distribution,even when the data is binary. ‘multinomial’ is unavailable when solver=’liblinear’. ‘auto’ selects ‘ovr’ if the data is binary, or if solver=’liblinear’, and otherwise selects ‘multinomial’.
New in version 0.18:Stochastic Average Gradient descent solver for ‘multinomial’ case.
Changed in version 0.22:Default changed from ‘ovr’ to ‘auto’ in 0.22.
verboseint, default=0
For the liblinear and lbfgs solvers set verbose to any positive number for verbosity.
warm_startbool, default=False
When set to True, reuse the solution of the previous call to fit as initialization, otherwise, just erase the previous solution. Useless for liblinear solver. Seethe Glossary.
New in version 0.17:warm_startto supportlbfgs,newton-cg,sag,sagasolvers.
n_jobsint, default=None
Number of CPU cores used when parallelizing over classes if multi_class=’ovr’”. This parameter is ignored when thesolveris set to ‘liblinear’ regardless of whether ‘multi_class’ is specified or not.Nonemeans 1 unless in ajoblib.parallel_backendcontext.-1means using all processors. SeeGlossaryfor more details.
l1_ratiofloat, default=None
The Elastic-Net mixing parameter, with0<=l1_ratio<=1. Only used ifpenalty='elasticnet'. Settingl1_ratio=0is equivalent to usingpenalty='l2', while settingl1_ratio=1is equivalent to usingpenalty='l1'. For0<l1_ratio<1, the penalty is a combination of L1 and L2.
Attributes
classes_ndarray of shape (n_classes, )
A list of class labels known to the classifier.
coef_ndarray of shape (1, n_features) or (n_classes, n_features)
Coefficient of the features in the decision function.
coef_is of shape (1, n_features) when the given problem is binary. In particular, whenmulti_class='multinomial',coef_corresponds to outcome 1 (True) and-coef_corresponds to outcome 0 (False).
intercept_ndarray of shape (1,) or (n_classes,)
Intercept (a.k.a. bias) added to the decision function.
Iffit_interceptis set to False, the intercept is set to zero.intercept_is of shape (1,) when the given problem is binary. In particular, whenmulti_class='multinomial',intercept_corresponds to outcome 1 (True) and-intercept_corresponds to outcome 0 (False).
n_iter_ndarray of shape (n_classes,) or (1, )
Actual number of iterations for all classes. If binary or multinomial, it returns only 1 element. For liblinear solver, only the maximum number of iteration across all classes is given.
Changed in version 0.20:In SciPy <= 1.0.0 the number of lbfgs iterations may exceedmax_iter.n_iter_will now report at mostmax_iter.
[03. Part 3) Ch 14. 이건 꼭 알아야 해 - 지도 학습 모델의 핵심 개념 - 03. 주요 모델의 구조 및 특성-2]
* k- 최근접 이웃 (k-Nearest Neighbors; kNN)
- 모델 구조
* k - 최근접 이웃 (k-Nearest Neighbors ; kNN)
- 주요 파라미터와 설정 방법
. 이웃 수 (k) : 홀수로 설정하며, 특징 수 대비 샘플 수가 적은 경우에는 k를 작게 설정하는 것이 바람직하다.
// 홀수로 설정하는 이유는 동점을 방지하기 위해서이다.
// 샘플수가 작다는 것은 데이터가 밀도가 작다는 것이다.
. 거리 및 유사도 척도
.. 모든 변수가 서열형 혹은 정수인 경우 : 맨하탄 거리
.. 방향성이 중요한 경우 (예 : 상품 추천 시스템) : 코사인 유사도
.. 모든 변수가 이진형이면서 희소하지 않은 경우 : 매칭 유사도
.. 모든 변수가 이진형이면서 희소한 경우 : 자카드 유사도
.. 그 외 : 유클리디안 거리
// 희소하다는 것은 데이터 들이 0으로 이뤄져있다고 보면 된다. 텍스트 데이터가 그렇게 이뤄져 있다고 보면 된다.
- 특징 추출이 어려우나 유사도 및 거리 계산만 가능한 경우 (예: 시퀀스 데이터) 에 주로 활용
- 모든 특징이 연속형이고 샘플 수가 많지 않은 경우에 좋은 성능을 보인다고 알려져 있음
- 특징 간 스케일 차이에 크게 영향을 받아, 스케일링이 반드시 필요함 (코사인 유사도를 사용하는 경우 제외)
- 거리 및 유사도 계산에 문제가 없다면, 별다른 특징 변환이 필요하지 않다.
* 의사 결정 나무 (Decision tree)
- 모델 구조
// 설명력이 굉장히 높다는 것이 이 의사결정나무의 핵심이라고 볼 수 있다.
- 예측 과정을 잘 설명할 수 있다는 장점 덕분에 많은 프로젝트에서 활용
. A 보험사 : 고객의 이탈 여부를 예측하고, 그 원인을 파악해달라
. B 밸브사 : 밸브의 불량이 발생하는 공정 상의 원인을 파악해달라
. C 홈쇼핑사 : 방송 조건에 따라 예측한 상품 매출액 기준으로 방송 편성표를 추천해주고, 그 근거를 설명해 달라
- 선형 분류기라는 한계로 예측력이 좋은 편에 속하지는 못하나, 최근 각광 받고 있는 앙상블 모델 (예 : XGBoost, lightGBM) 의 기본 모형으로 사용된다.
// 예측력은 좋을지 몰라도 설명력이 떨어진다는 문제가 있다.
- 주요 파라미터
. max_depth : 최대 깊이로 그 크기가 클수록 모델이 복잡해진다.
. min_samples_leaf : 잎 노드에 있어야 하는 최소 샘플 수로, 그 크기가 작을 수록 모델이 복잡해진다.
* 나이브 베이즈 (Navie Bayes)
- 모델 구조
. 베이즈 정리르 사용하고 특징 간 독립을 가정하여 사후 확률을 계산
. 가능도는 조건부 분포를 가정하여 추정한다.
.. 이진형 변수 : 베르누이 분포
.. 범주형 변수 : 다항 분포
.. 연속형 변수 : 가우시안 분포
- 모델 특성
. 특징 간 독립 가정이 실제로는 굉장히 비현실적이므로, 일반적으로 높은 성능을 기대하긴 어렵다.
// 특징 간 독립 가정이 통계학적으로는 많이 쓰이지만.. 높은 성능을 기대하긴 어렵다.
. 설정한 분푸에 따라 성능 차이가 크므로, 특징의 타입이 서로 같은 경웨 사용하기 바람직하다.
. 특징이 매우 많고 그 타입이 같은 문제 (예: 이진형 텍스트 분류)에 주로 사용된다.
. 특징 간 독립 가정이 실제로는 굉장히 비현실적이므로, 일반적으로 높은 성능을 기대하긴 어렵다.
. 설정한 분포에 따라 성능 차이가 크므로, 특징의 타입이 서로 같은 경우에 사용하기 바람직하다.
. 특징이 매우 많고 그 타입이 같은 문제 (예: 이진형 텍스트 분류) 에 주로 사용된다.
* 서포트 벡터 머신 (Support Vector Machine; SVM)
- 모델 구조
- 최적화 모델
- 오차를 최소화하면서 동시에 마진을 최대화하는 분류 모델로, 커널 트릭을 활용하여 저차원 공간을 고차원 공간으로 매핑한다.
- 마진의 개념을 회귀에 활용한 모델을 서포트 벡터 회귀 (Support Vector Regression)이라 한다.
- 주요 파라미터
. kernel : 통상적으로 이진 변수가 많으면 linear 커널이, 연속 변수가 많으면 rbf 커널이 잘 맞는 다고 알려져 있다.
// 특징간 차이는 rbf, 특징간 곱 linear
. C : 오차 패널티에 대한 계수로, 이 값이 작을 수록 마진 최대화에 클수록 학습 오차 최소화에 신경을 쓰며, 보통 10n 범위에서 튜닝한다.
. r : rbf 커널의 파라미터로, 크면 클수록 데이터의 모양을 잡 잡아내지만 오차가 커질 위험이 있으며, C 가 증가하면 r도 증가하게 튜닝하는 것이 일반적이다.
- 파라미터 튜닝이 까다로운 모델이지만, 튜닝만 잘하면 좋은 성능을 보장하는 모델이다.
// 학술에 관심이 있으면 VC 정리...를 확인해보면 좋다.
* 신경망 (Neural Network)
- 모델 구조
- 초기 가중치에 크게 영향을 받는 모델로, 세밀하게 random_state 와 max_iter 값을 조정해야 하다.
// 우연에 많이 기반한다는 의미이다. 데이터가 작으면 작을 수록 그런 경향이 크다.
- 은닉 노드가 하나 추가되면 그에 따라 하나 이상의 가중치가 추가되어, 복잡도가 크게 증가할 수 있다.
- 모든 변수 타입이 연속형인 경우에 성능이 잘 나오는 것으로 알려져 있으며, 은닉 층 구조에 따른 복잡도 조절이 파라미터 튜닝에서 고려해야 할 가장 중요한 요소임
- 최근 딥러닝의 발전으로 크게 주목받는 모델이지만, 특정 주제 (예 : 시계열 예측, 이미지 분류, 객체 탐지 등) 를 제외하고는 깊은 층의 신경망은 과적합으로 인한 성능 이슈가 자주 발생한다.
* 트리 기반의 앙상블 모델
- 최근 의사 결정나무를 기본 모형으로 하는 앙상블 모형이 캐글 등에서 자주 사용되며, 좋은 성능을 보인다.
- 랜덤 포레스트 : 배깅(bagging) 방식으로 여러 트리를 학습하여 결합한 모델
- XGboost & LightGBM : 부스팅 방식으로 여러 트리를 순차적으로 학습하여 결합한 모델
- 랜덤 포레스트를 사용할 때는 트리의 개수와 나무의 최대 깊이를 조정해야 하며, XGboost 와 LightGBM 을 사용할 때는 트리의 개수, 나무의 최대 깊이, 학습률을 조정해야 한다.
. 트리의 개수 : 통상적으로 트리의 개수가 많으면 많을 수록 좋은 성능을 내지만, 어느 수준 이상에서는 거의 큰 차일ㄹ 보이지 않는다.
. 나무의 최대 깊이 : 4이하로 설정해주는 것이 과적합을 피할 수 있어, 바람직하다.
. 학습률 : 이 값은 작으면 작을 수록 과소적합 위험이 있으며, 크면 클수록 과적합 위험이 있다. 통상적으로 0.1로 설정한다.
[파이썬을 활용한 데이터 전처리 Level UP-Comment] - 모델 개발 프로세스에 대해서 배웠고, 지도학습에서는 선형회귀, 의사결정나무, 신경망 등에 대해서도 배워 볼 수 있었다.
If ‘raise’, then invalid parsing will raise an exception.
If ‘coerce’, then invalid parsing will be set as NaT.
If ‘ignore’, then invalid parsing will return the input.
dayfirstbool, default False
Specify a date parse order ifargis str or its list-likes. If True, parses dates with the day first, eg 10/11/12 is parsed as 2012-11-10. Warning: dayfirst=True is not strict, but will prefer to parse with day first (this is a known bug, based on dateutil behavior).
yearfirstbool, default False
Specify a date parse order ifargis str or its list-likes.
If True parses dates with the year first, eg 10/11/12 is parsed as 2010-11-12.
If both dayfirst and yearfirst are True, yearfirst is preceded (same as dateutil).
Warning: yearfirst=True is not strict, but will prefer to parse with year first (this is a known bug, based on dateutil behavior).
utcbool, default None
Return UTC DatetimeIndex if True (converting any tz-aware datetime.datetime objects as well).
Behaves as: - If True, require an exact format match. - If False, allow the format to match anywhere in the target string.
unitstr, default ‘ns’
The unit of the arg (D,s,ms,us,ns) denote the unit, which is an integer or float number. This will be based off the origin. Example, with unit=’ms’ and origin=’unix’ (the default), this would calculate the number of milliseconds to the unix epoch start.
infer_datetime_formatbool, default False
If True and noformatis given, attempt to infer the format of the datetime strings based on the first non-NaN element, and if it can be inferred, switch to a faster method of parsing them. In some cases this can increase the parsing speed by ~5-10x.
originscalar, default ‘unix’
Define the reference date. The numeric values would be parsed as number of units (defined byunit) since this reference date.
If ‘unix’ (or POSIX) time; origin is set to 1970-01-01.
If ‘julian’, unit must be ‘D’, and origin is set to beginning of Julian Calendar. Julian day number 0 is assigned to the day starting at noon on January 1, 4713 BC.
If Timestamp convertible, origin is set to Timestamp identified by origin.
cachebool, default True
If True, use a cache of unique, converted dates to apply the datetime conversion. May produce significant speed-up when parsing duplicate date strings, especially ones with timezone offsets. The cache is only used when there are at least 50 values. The presence of out-of-bounds values will render the cache unusable and may slow down parsing.
New in version 0.23.0.
Changed in version 0.25.0:- changed default value from False to True.
Returns
datetime
If parsing succeeded. Return type depends on input:
list-like: DatetimeIndex
Series: Series of datetime64 dtype
scalar: Timestamp
In case when it is not possible to return designated types (e.g. when any element of input is before Timestamp.min or after Timestamp.max) return will have datetime.datetime type (or corresponding array/Series).
// recency 로 날짜를 처리한다.
// 하나의 element를 처리 한다는 것이다.
// keep = last 를 통해서, 계산량을 감소 시키는 것이다.
// keep 을 last 로 두는 이유는 맨 마지막 값을 두기 위한 것이다.
// CustomerID, Invoice 데이터를 가지고 오고.. 이건 최근성 이라는 column에 넣어준다.
// 각각의 스케일이 틀리기 때문에 유클리디안 거리등을 사용하기는 어렵다.
// 고객의 주문 특성에 따라서 군집화를 수행하다.
// 군집화 모델을 인스터스화 하고 학습을 시켜준다.
// 각각의 데이터를 보고 확인해 본다.
// 주요 상품에 대해서 확인을 해본다.
// TransactionEncdoer 를 통해서 나타내본다.
// 희소한지를 알아봐야 한다.
// 여기서 모든 것을 사용하는 것은 아니고 빈도가 100회 이상 나온 품목만 사용하면 된다.
// 차원을 줄여서 확인을 해 봐야 한다.
[02. Part 2) Ch 13. 직접 해봐야 내것이 된다. - 03. 이탈 고객의 고객 여정 탐색하기]
* 문제상황
- 고객 로그 데이터를 바탕으로 이탈한 고객과 이탈하지 않은 고객이 보이는 주요 행동 패턴을 탐색하자!
(1) 이탈 고객과 비이탈 고객 분리
(2) 이탈 고객과 비이탈 고객 데이터 내 주요 행동 패턴 추출
(3) 주요 행동 패턴의 등장 비율 비교
* 실습
// sort_values 를 통해서 고객ID, 날짜로 가져오고
// 행동을 unique 상태로 확인하고
// 다른 행동이 있을 수 있기 때문에 ~ not( churn_ID 에 속하지 않는 ID 를 찾아 본다.)
// isin 함수를 통해서 확인
// 이탈이든 아니든 고객ID 의 행동에 따라서 array 형태로 나타낸다.
// 비말 패턴 탐색에서 사용했던 함수들을 가지고 와서 빈말 패턴을 찾아 본다.
[03. Part 3) Ch 14. 이건 꼭 알아야 해 - 지도 학습 모델의 핵심 개념 - 01. 지도학습 개요]
// 기초적인 내용은 생략되어 있다.~
* 지도 학습
- 컴퓨터에게 입력과 출력을 주고, 입력과 출력 간 관계를 학습하여 새로운 입력에 대해 적절한 출력을 내도록 하는 기계학습의 한 분야
- 입력을 특징(feature) 혹은 특징 벡터 (featur vector)라고 하며, 출력을 라벨 (label)이라고 함
// 특징과 라벨간의 관계를 학습하는 거라고 보면 된다.
- 라벨이 범주형 변수면 분류라고 하며, 연속형 변수면 예측 혹은 회귀라고 한다.
* 과적합
- 지도학습 모델은 학습 데이터를 분류하고 예측하는 수준으로, 학습에 사용되지 않은 데이터도 정확히 분류하고 예측하리라 기대하며, 이러한 기대가 충족되는 경우 일반화 되었다고 한다.
- 모델이 너무 족잡해서 학습 데이터에 대해서만 정확히 분류하고 예측하는 모델을 과적합되었다고 하며, 반대로 너무 단순해서 어떠한 데이터에 대해서도 부적합한 모델을 과소적합되었다고 한다.
// 적정적합은 오차가 조금씩 있고, 과적합은 오차가 전혀 없는 상태로 본다.
// 적정적합은 학습 데이터를 사용해서 학습을 했을 것이고.. 과적합은 너무 복잡하게 되어 있어서 데이터에 대해서만 과하게 적합이라고 보면 된다.
- 과적합과 과소적합에 영향을 끼치는 주요 인자로는 모델의 복잡도, 샘플 수, 차원의 크기 등이 있다.
// 샘플수는 이 모델을 지지하는 근거하는.. 수라고 보면 된다.
// 적으면 성급한 일반화가 되어 버릴 수가 있다.
* 데이터 분할
- 과적합된 모델을 좋게 평가하는 것을 방지하기 위해서, 데이터를 학습 데이터와 평가 데이터로 분할한다.
// 객관적인 결과를 위해서 평가 데이터를 모르게 해야 한다.
- 학습 데이터와 평가 데이터가 지나치게 유사하거나 특정 패턴을 갖지 않도록 분할 해야 한다.
* 파라미터와 하이퍼 파라미터
- 하이퍼 파라미터(hyper parameter)는 일종의 사용자 옵션으로, 모델 성능에 직접적으로 영향을 끼치므로 자세한 데이터 탐색 결과를 바탕으로 선택해야 한다.
// 파라미터는 신경을 많이 쓰지 않는다고 보면 된다.
// 머신러닝에서 무조건 좋다는 것은 없다고 보면 된다. 경험으로 이것이 좀 더 나아 보인다고 생각하면 된다.
* 이진 분류 모델 평가 : 혼동 행렬
- 이진 분류 : 클래스 변수의 상태 공간이 크기가 2인 분류
// 상태 공간은 값의 갯수로 보면 된다.
- 혼동 행렬 : 분류 모델을 평가하는데 사용하는 표
. Positive class : 분석의 관심 대상 (보통 1로 설정)
. Negativ class : 분석 관심 대상 외 (보통 0이나 -1로 설정)
* 이진 분류 모델 평가 : 대표적인 지표
- 각 지표의 한계 때문에, 가능한 여러 지표를 사용하여 모델을 평가해야 한다.
// 정확도 가 가장 많이 쓰이고, 공정하고
// F1 은 정확도랑 전혀 관계가 없다고 생각해야 한다.
* 다중 분류 모델 평가
- 다중 분류 : 클래스 변수의 상태 공간이 크기가 3이상인 분류
- 각 클래스를 긍정으로 간주하여 평가 지표를 계산한 뒤, 이들의 산술 평균이나 가중 평균으로 평가
// 산술 평균 marco average
// 가중 평균 weight average
* 예측 모델 평가
- 대표적인 예측 모델 평가 지표로 루트 평균 제곱 오차 (root mean squared erro ; RMSE) 와 평균 절대 오차 (mean absolute error ; MAE) 가 있으며, 두 지표 모두 값이 작을 수록 좋음
- RMSE 와 MAE를 정확히 평가하려면, 해당 분야의 도메인 지식이나 클래스 변수의 스케일을 고려해야 한다.
. 예를 들어, 코스피 지수를 예측하는 모델의 MAE 가 1010 이라면 무의미한 수준의 모델이지만, 전세계 인구 수를 예측하는 모델의 MAE 가 1010 이라면 매우 우수한 모델이다.
[파이썬을 활용한 데이터 전처리 Level UP-Comment] - 고객 데이터 활용 실습을 해보았고, 고객 이탈 여정에 대해서 간략하게 다른 주제로 살펴 볼 수 있었다. 지도 학습에 대한 주요 개념들을 배웠다.
Value to use to fill holes (e.g. 0), alternately a dict/Series/DataFrame of values specifying which value to use for each index (for a Series) or column (for a DataFrame). Values not in the dict/Series/DataFrame will not be filled. This value cannot be a list.
Method to use for filling holes in reindexed Series pad / ffill: propagate last valid observation forward to next valid backfill / bfill: use next valid observation to fill gap.
axis{0 or ‘index’, 1 or ‘columns’}
Axis along which to fill missing values.
inplacebool, default False
If True, fill in-place. Note: this will modify any other views on this object (e.g., a no-copy slice for a column in a DataFrame).
limitint, default None
If method is specified, this is the maximum number of consecutive NaN values to forward/backward fill. In other words, if there is a gap with more than this number of consecutive NaNs, it will only be partially filled. If method is not specified, this is the maximum number of entries along the entire axis where NaNs will be filled. Must be greater than 0 if not None.
downcastdict, default is None
A dict of item->dtype of what to downcast if possible, or the string ‘infer’ which will try to downcast to an appropriate equal type (e.g. float64 to int64 if possible).
Returns
DataFrame or None
Object with missing values filled or None ifinplace=True.
[02. Part 2) Ch 13. 직접 해봐야 내것이 된다. - 02 고객 세분화를 통한 마케팅 전략 수립 (문제)]
* 문제상황
- 주문 내역 데이터를 바탕으로 고객들을 주문 특성과 주문 상품에 따라 그룹화 하고 싶다!
. 주문 특성 기준 군집화
-> 환불 데이터와 주문 데이터로 분할
-> 특징 부착
-> 코사인 유사도 기반의 계층 군집화 수행
. 주문 상품 기준 군집화
-> 판매 상위 100개 상품 출현 여부를 나타내는 데이터로 변환
-> 자카드 유사도 기반의 계층 군집화 수행
* 주문 특성 기준 군집화 - 데이터 분할
- 해당 데이터에는 주문 데이터와 환불 데이터가 동시에 포함되어 있다.
- 환불 데이터는 주문 수량이 음수라는 특징이 있어, 데이터를 분할하는데 활용한다.
// 이런 특징을 이용해서 주문 데이터와 환불 데이터를 분류할 것이다.
* 주문 특성 기준 군집화 - 특징 추출
1. 군집화 데이터를 유니크한 고객 ID 컬럼만 있는 데이터프레임으로 초기화
2. 주문 / 반품 횟수 계산 및 부착 : 고객 ID 와 주문 ID 를 기준으로 중복을 제거 하는 방식으로 유니크한 (고객 ID, 주문 ID) 를 추출한 뒤, 추출한 데이터에서 고객 ID 의 수를 카운트하여 군집화 데이터에 부착
3. 주문량 계산 및 부착 : 고객 ID에 따른 주문량의 합계를 계산하여 군집화 데이터에 부착
4. 주문 금액 계산 및 부착 : 주문량과 단가를 곱하여 주문 금액을 계산한 뒤, 고객 ID에 따른 주문 금액의 합계를 계산하여 군집화 데이터에 부착
5. 최근성 계산 및 부착 : 현재 날짜에서 주문 날짜의 차이를 뺀 뒤, 고객별 해당 값의 최소 값을 군집화 데이터에 부착
* 주문 특성 기준 군집화 - 코사인 유사도 기반의 계층 군집화 수행
- 군집화 데이터에 (군집 개수 = 5, 군집간 거리 = 평균, 거리 척도 = 코사인 유사도)를 갖는 군집화 모델을 학습하여, 군집별 주요 특성을 파악
* 주문 상품 기준 군집화
- 주문 횟수가 상위 100 등안에 드는 상품들을 기준으로 고객을 상품 구매 여부로 구성된 벡터로 표현
- 이 데이터에 (군집 개수 = 5, 군집 간 거리 = 평균, 거리 척도 = 자카드 유사도)를 갖는 군집화 모델을 학습하여, 군집별 주요 특성을 파악한다.
// 희소한 데이터에 적절한 유사도 이기때문에 자카드 유사도를 사용했다.
[파이썬을 활용한 데이터 전처리 Level UP-Comment] - 홈페이지 분석을 위한 데이터 불러오기, 검정 방법, p-value 값에 대한 해석에 대해서 알아보았고, 새로운 실습 주제에 대해서 설명함.
Return the string representing a character whose Unicode code point is the integeri. For example,chr(97)returns the string'a', whilechr(8364)returns the string'€'. This is the inverse oford().
The valid range for the argument is from 0 through 1,114,111 (0x10FFFF in base 16).ValueErrorwill be raised ifiis outside that range.
@classmethod
Transform a method into a class method.
A class method receives the class as implicit first argument, just like an instance method receives the instance. To declare a class method, use this idiom:
class C:
@classmethod
def f(cls, arg1, arg2, ...): ...
A class method can be called either on the class (such asC.f()) or on an instance (such asC().f()). The instance is ignored except for its class. If a class method is called for a derived class, the derived class object is passed as the implied first argument.
Class methods are different than C++ or Java static methods. If you want those, seestaticmethod()in this section. For more information on class methods, seeThe standard type hierarchy.
Changed in version 3.9:Class methods can now wrap otherdescriptorssuch asproperty().
// 패턴 찾기
// 문자열로 변환 (하나의 리스트만 대상으로 하기에, 이렇게 하는 것이 더 수월)
// join 으로 각 alphabet 을 붙여줌.
// find_maximum_frequent_sequence_item 함수
// 각각의 신뢰도와 지지도를 확인해 볼 수 있다.
[02. Part 2) Ch 12.어디서 많이 봤던 패턴이다 싶을 때 - 빈발 패턴 탐색 - 04. 머신러닝에서의 빈발 패턴 탐색]
* 추천 시스템
- "상품 A 를 구매하면 상품 B 도 구매할 것이다" 라는 유의한 연관 규칙이 있다면, 상품 A 를 구매하고 상품 B 를 구매하지 않은 고객에게 상품 B 를 추천해주는 방법에 활용
// 가장 대표적인 것
- (예시) 아마존의 도서 추천
* 시계열 및 시퀀스 데이터에서의 특징 추출
- 시계열 및 시퀀스 분류 과제에서 특징을 추출하는데도 활용
// 원도우 크기를 정렬해줘야 한다.
// 지도 학습 또는 비지도 학습에 활용할 수 있다는 점이 있다.
[02. Part 2) Ch 13. 직접 해봐야 내것이 된다. - 01. A-B 테스트 - 홈페이지 화면을 어떻게 구성할 것인가 - (문제)]
* A/B 테스트란?
- 임의로 나눈 둘 이상의 집단에 서로 다른 컨텐츠를 제시한 뒤, 통계적 가설 검정을 이용하여 어느 컨텐츠에 대한 반응이 더 효과적인지를 파악하는 방법
웹 사이트에서의 A/B 테스트 예제. 한 웹 사이트에서 한 개의 버튼 요소의 디자인만 다른 두 가지 버전을 무작위로 방문자에게 제공해, 두 디자인의 상대적인 효용성을 측정할 수 있다.
마케팅과 웹 분석에서,A/B 테스트(버킷 테스트또는분할-실행 테스트)는 두 개의 변형 A와 B를 사용하는 종합 대조 실험(controlled experiment)이다.[1]통계영역에서 사용되는 것과 같은 통계적 가설 검정또는 "2-표본 가설 검정"의 한 형태다. 웹 디자인(특히사용자 경험 디자인)과 같은 온라인 영역에서, A/B 테스트의 목표는 관심 분야에 대한 결과를 늘리거나 극대화하는 웹 페이지에 대한 변경 사항이 무엇인지를 규명하는 것이다(예를 들어, 배너 광고의클릭률(click-through rate)). 공식적으로 현재 웹 페이지에 null 가설과 연관이 있다. A/B 테스트는 변수 A에 비해 대상이 변수 B에 대해 보이는 응답을 테스트하고, 두 변수 중 어떤 것이 더 효과적인지를 판단함으로써 단일 변수에 대한 두 가지 버전을 비교하는 방법이다.[2]
이름에서 알 수 있듯이, 두 버전(A와 B)이 비교되는데 사용자의 행동에 영향을 미칠 수 있는 하나의 변형을 제외하면 동일하다. 버전 A는 현재 사용되는 버전(control)이라고 하는 반면, 버전 B의 일부 사항은 수정된다(treatment). 예를 들어, 전자상거래 웹사이트에서 구매 깔때기은 일반적으로 A/B 테스트하기 좋은 대상으로, 하락률에 있어 수익 한계선에 대한 개선이 판매에 있어 상당한 이익을 나타낼 수 있기 때문이다. 항상 그런 것은 아니지만, 때때로 텍스트, 레이아웃, 이미지 그리고 색상과 같은 요소들을 테스트함으로써 현저한 향상을 볼 수 있다.[3]
다변량 테스트 또는 다항 테스트가 A/B 테스트와 유사하지만, 동시에 두 개 이상의 버전을 테스트하거나 좀 더 많은 컨트롤들을 테스트할 수 있다. 두 개 이상의 버전 또는 동시에 더 많이 사용을 제어한다. 단순한 A/B 테스트는 설문 데이터, 오프라인 데이터 그리고 다른 좀 더 복잡한 현상과 같이, 실측, 유사 실험 또는 기타 비 실험 상황에서는 유효하지 않다.
A/B 테스트는 그 접근 방식이 다양한 연구 관례에서 일반적으로 사용되는, 피험자간 설계와 유사하긴 하지만, 특정 틈새 영역에서 철학과 사업 전략의 변화로 마케팅되었다.[4][5][6] 웹 개발 철학으로서의 A/B 테스트는 해당 영역을 증거 기반의 실천으로의 폭넓은 움직임으로 이끈다. 대부분의 마케팅 자동화 도구가 현재 일반적으로 A/B 테스트를 지속적으로 실행할 수 있는 기능과 함께 제공되고 있기 때문에, A/B 테스트가 거의 모든 영역에서 지속적으로 수행될 수 있는 것으로 간주되는 것이 A/B 테스트의 이점이다. 이로써 현재의 리소스를 사용해 웹 사이트와 다른 도구를 업데이트해 트렌드 변화를 유지할 수 있다.
// 버튼이 어떻게 배치되었을 때 클릭을 많이 하는지에 대해서
* 문제상황
- 온라인 쇼핑몰 페이지 구성에 따른 다양한 실험 결과를 바탕으로 전환율이 최대가 되는 구성을 하고 싶다!
// 전환율은 어떤 상품을 구매율
- 관련 데이터 : AB 테스트 폴더 내 모든 데이터
* Step 1. 현황 파악
- 관련 데이터 : 일별현황데이터.csv
- 분석 내용
(1) 구매자수, 방문자수, 총 판매 금액에 대한 기술 통계
(2) 일자별 방문자수 추이 파악
(3) 일자별 구매자수 추이 파악
(4) 일자별 총 판매 금액 추이 파악
* Step 2. 상품 배치와 상품 구매 금액에 따른 관계 분석
- 관련 데이터
. 상품배치_A.csv
. 상품배치_B.csv
. 상품배치_C.csv
- 분석 내용
(1) 일원분산분석을 이용한 상품 배치에 따른 상품 구매 금액 평균 차이 분석 (상품 구매 금액 0원 미포함)
(2) 일원분산분석을 이용한 상품 배치에 따른 상품 구매 금액 평균 차이 분석 (상품 구매 금액 0원 포함)
(3) 카이제곱 검정을 이용한 구매 여부와 상품 배치 간 독립성 파악
// 서로 독립적인지를 확인해 볼 것이다.
* Step 3. 사이트맵 구성에 따른 체류 시간 차이 분석
- 관련 데이터
. 사이트맵_A.csv
. 사이트맵_B.csv
. 사이트맵_C.csv
- 분석 내용
(1) 사이트맵별 체류시간 평균 계산
(2) 일원분산분석을 이용한 사이트맵에 따른 체류 시간 평균 차이 분석 (박스 플롯 포함)
* Step 4. 할인 쿠폰의 효과 분석
- 관련 데이터 : 할인쿠폰 발행효과.csv
- 분석내용
(1) 발행후와 전의 구매 횟수 차이에 대한 기술 통계
(2) 발행전, 발행후의 구매 횟수에 대한 박스폴롯 시각화
(3) 쌍체 표본 t - 검정을 이용한 차이 유의성 검정
// 유의하지 않다면 굳이 할인쿠폰을 발행할 필요가 없는 것이다.
* Step 5. 체류 시간과 구매 금액 간 관계 분석
- 관련 데이터 : 체류시간_구매금액.csv
- 분석 내용
(1) 구매 금액과 체류 시간의 산점도 시각화
(2) 구매 금액과 체류 시간 간 상관관계 분석
* Step 6. 구매 버튼 배치에 따른 구매율 차이 분석
- 관련 데이터 : 구매버튼_버튼타입_통계.xlsx
- 분석내용
(1) 결측 대체
(2) pivot table을 이용한 교차 테이블 생성
(3) 카이제곱검정을 이용한 독립성 검정
[파이썬을 활용한 데이터 전처리 Level UP-Comment] - 시계열 데이터와 빈발 패턴, 그리고 머신러닝에서의 활용에 대해서 어떻게 활용할 것인가에 대해서 배웠다. 그리고, 새로운 프로젝트를 통해서 어떻게 이것을 분석하고 검정하는지에 대한 문제에 대해 알아보았다.
Dynamic programming is a terrific approach that can be applied to a class of problems for obtaining an efficient and optimal solution.
Insimple words, the concept behind dynamic programming is to break the problems into sub-problems and save the result for the future so that we will not have to compute that same problem again. Further optimization of sub-problems which optimizes the overall solution is known as optimal substructure property.
Two ways in which dynamic programming can be applied:
Top-Down:
In this method, the problem is broken down and if the problem is solved already then saved value is returned, otherwise, the value of the function is memoized i.e. it will be calculated for the first time; for every other time, the stored value will be called back.Memoizationis a great way for computationally expensive programs. Don’t confuse memoization with memorize.
// memoization..으로 접근
Memoize != memorize
Bottom-Up:
This is an effective way of avoiding recursion by decreasing the time complexity that recursion builds up (i.e. memory cost because of recalculation of the same values). Here, the solutions to small problems are calculated which builds up the solution to the overall problem. (You will have more clarity on this with the examples explained later in the article).
Understanding Dynamic Programming With Examples
Let’s start with a basic example of the Fibonacci series.
Fibonacci seriesis a sequence of numbers in such a way that each number is the sum of the two preceding ones, starting from 0 and 1.
F(n) = F(n-1) + F(n-2)
Recursive method:
def r_fibo(n):
if n <= 1:
return n
else:
return(r_fibo(n-1) + r_fibo(n-2))
Here, the program will call itself, again and again, to calculate further values. The calculation of the time complexity of the recursion based approach is around O(2^N). The space complexity of this approach is O(N) as recursion can go max to N.
In this method values like F(2) are computed twice and calls for F(1) and F(0) are made multiple times. Imagine the number of repetitions if you have to calculate it F(100). This method isineffective for large values.
Top-Down Method
def fibo(n, memo):
if memo[n] != null:
return memo[n]
if n <= 1:
return n
else:
res = fibo(n-1) + fibo(n+1)
memo[n] = res
return res
Here, the computation time is reduced significantly as the outputs produced after each recursion are stored in a list which can be reused later. This method is much more efficient than the previous one.
Bottom down
def fib(n):
if n<=1:
return n
list_ = [0]*(n+1)
list_[0] = 0
list_[1] = 1
for i in range(2, n+1):
list_[i] = list_[i-1] + list[i-2]
return list_[n]
This code doesn’t use recursion at all. Here, we create an empty list of length (n+1) and set the base case of F(0) and F(1) at index positions 0 and 1. This list is created to store the corresponding calculated values using a for loop for index values 2 up to n.
Unlike in the recursive method, the time complexity of this code is linear and takes much less time to compute the solution, as the loop runs from 2 to n, i.e., it runs inO(n). This approach is themost efficient wayto write a program.
There are following two different ways to store the values so that the values of a sub-problem can be reused. Here, will discuss two patterns of solving DP problem:
Tabulation:Bottom Up
Memoization:Top Down
Before getting to the definitions of the above two terms consider the below statements:
Version 1: I will study the theory of Dynamic Programming from GeeksforGeeks, then I will practice some problems on classic DP and hence I will master Dynamic Programming.
Version 2: To Master Dynamic Programming, I would have to practice Dynamic problems and to practice problems – Firstly, I would have to study some theory of Dynamic Programming from GeeksforGeeks
Both the above versions say the same thing, just the difference lies in the way of conveying the message and that’s exactly what Bottom Up and Top Down DP do. Version 1 can be related to as Bottom Up DP and Version-2 can be related as Top Down Dp.
Tabulation Method – Bottom Up Dynamic Programming
As the name itself suggests starting from the bottom and cumulating answers to the top. Let’s discuss in terms of state transition.
Let’s describe a state for our DP problem to be dp[x] with dp[0] as base state and dp[n] as our destination state. So, we need to find the value of destination state i.e dp[n]. If we start our transition from our base state i.e dp[0] and follow our state transition relation to reach our destination state dp[n], we call it Bottom Up approach as it is quite clear that we started our transition from the bottom base state and reached the top most desired state.
Now, Why do we call it tabulation method?
To know this let’s first write some code to calculate the factorial of a number using bottom up approach. Once, again as our general procedure to solve a DP we first define a state. In this case, we define a state as dp[x], where dp[x] is to find the factorial of x.
Now, it is quite obvious that dp[x+1] = dp[x] * (x+1)
// Tabulated version to find factorial x. int dp[MAXN]; // base case int dp[0] = 1; for (int i = 1; i< =n; i++) { dp[i] = dp[i-1] * i; }
The above code clearly follows the bottom-up approach as it starts its transition from the bottom-most base case dp[0] and reaches its destination state dp[n]. Here, we may notice that the dp table is being populated sequentially and we are directly accessing the calculated states from the table itself and hence, we call it tabulation method.
Memoization Method – Top Down Dynamic Programming
Once, again let’s describe it in terms of state transition. If we need to find the value for some state say dp[n] and instead of starting from the base state that i.e dp[0] we ask our answer from the states that can reach the destination state dp[n] following the state transition relation, then it is the top-down fashion of DP.
Here, we start our journey from the top most destination state and compute its answer by taking in count the values of states that can reach the destination state, till we reach the bottom most base state.
Once again, let’s write the code for the factorial problem in the top-down fashion
// Memoized version to find factorial x. // To speed up we store the values // of calculated states // initialized to -1 int dp[MAXN] // return fact x! int solve(int x) { if (x==0) return 1; if (dp[x]!=-1) return dp[x]; return (dp[x] = x * solve(x-1)); }
As we can see we are storing the most recent cache up to a limit so that if next time we got a call from the same state we simply return it from the memory. So, this is why we call it memoization as we are storing the most recent state values.
In this case the memory layout is linear that’s why it may seem that the memory is being filled in a sequential manner like the tabulation method, but you may consider any other top down DP having 2D memory layout likeMin Cost Path, here the memory is not filled in a sequential manner.
This article is contributed byNitish Kumar. If you like GeeksforGeeks and would like to contribute, you can also write an article using or mail your article to contribute@geeksforgeeks.org. See your article appearing on the GeeksforGeeks main page and help other Geeks.
* 순서를 고려한 연관규칙 탐사 (예시 : L = 2, 최소 지지도 = 2)
* 순서를 고려한 연관규칙 탐사 (예시 : L = 2, 최소 지지도 = 3)
[02. Part 2) 어디서 많이 봤던 패턴이다 싶을 때 - 빈발 패턴 탐색 - 02-2. 빈발 시퀀스 탐색 (실습)]
// 만약에 순서가 없으면 순서를 만들면 된다.
// 순서가 중요한 데이터이기 때문에 고객ID, 순서를 정리를 해줘야 한다.
// unique () 찾아보기
// itertools.product() 함수에 대해서 알아보기
// pattern에 포함된 모든 아이템 집합이 recor에 포함된 아이템 집합에 속하지 않는지 체크
Roughly equivalent to nested for-loops in a generator expression. For example,product(A,B)returns the same as((x,y)forxinAforyinB).
The nested loops cycle like an odometer with the rightmost element advancing on every iteration. This pattern creates a lexicographic ordering so that if the input’s iterables are sorted, the product tuples are emitted in sorted order.
To compute the product of an iterable with itself, specify the number of repetitions with the optionalrepeatkeyword argument. For example,product(A,repeat=4)means the same asproduct(A,A,A,A).
This function is roughly equivalent to the following code, except that the actual implementation does not build up intermediate results in memory:
def product(*args, repeat=1):
# product('ABCD', 'xy') --> Ax Ay Bx By Cx Cy Dx Dy
# product(range(2), repeat=3) --> 000 001 010 011 100 101 110 111
pools = [tuple(pool) for pool in args] * repeat
result = [[]]
for pool in pools:
result = [x+[y] for x in result for y in pool]
for prod in result:
yield tuple(prod)
Beforeproduct()runs, it completely consumes the input iterables, keeping pools of values in memory to generate the products. Accordingly, it only useful with finite inputs.
[파이썬을 활용한 데이터 전처리 Level UP-Comment] - 빈발 개념에 대해서 배웠으나 약간의 개념 정리가 필요한 것 같다. 어떤 sequence 를 이뤄서 나타내는 조건들에 대해서 분석을 해보고, 어똔 조건에서 어떠한 결과물을 내놓는 것에 대해서는 좀 더 연구가 필요하지 않나 싶다.
‘k-means++’ : selects initial cluster centers for k-mean clustering in a smart way to speed up convergence. See section Notes in k_init for more details.
‘random’: choosen_clustersobservations (rows) at random from data for the initial centroids.
If an ndarray is passed, it should be of shape (n_clusters, n_features) and gives the initial centers.
If a callable is passed, it should take arguments X, n_clusters and a random state and return an initialization.
n_initint, default=10
Number of time the k-means algorithm will be run with different centroid seeds. The final results will be the best output of n_init consecutive runs in terms of inertia.
max_iterint, default=300
Maximum number of iterations of the k-means algorithm for a single run.
tolfloat, default=1e-4
Relative tolerance with regards to Frobenius norm of the difference in the cluster centers of two consecutive iterations to declare convergence.
Determines random number generation for centroid initialization. Use an int to make the randomness deterministic. SeeGlossary.
copy_xbool, default=True
When pre-computing distances it is more numerically accurate to center the data first. If copy_x is True (default), then the original data is not modified. If False, the original data is modified, and put back before the function returns, but small numerical differences may be introduced by subtracting and then adding the data mean. Note that if the original data is not C-contiguous, a copy will be made even if copy_x is False. If the original data is sparse, but not in CSR format, a copy will be made even if copy_x is False.
n_jobsint, default=None
The number of OpenMP threads to use for the computation. Parallelism is sample-wise on the main cython loop which assigns each sample to its closest center.
Noneor-1means using all processors.
Deprecated since version 0.23:n_jobswas deprecated in version 0.23 and will be removed in 0.25.
K-means algorithm to use. The classical EM-style algorithm is “full”. The “elkan” variation is more efficient on data with well-defined clusters, by using the triangle inequality. However it’s more memory intensive due to the allocation of an extra array of shape (n_samples, n_clusters).
For now “auto” (kept for backward compatibiliy) chooses “elkan” but it might change in the future for a better heuristic.
Changed in version 0.18:Added Elkan algorithm
Attributes
cluster_centers_ndarray of shape (n_clusters, n_features)
Coordinates of cluster centers. If the algorithm stops before fully converging (seetolandmax_iter), these will not be consistent withlabels_.
labels_ndarray of shape (n_samples,)
Labels of each point
inertia_float
Sum of squared distances of samples to their closest cluster center.
n_iter_int
Number of iterations run.
* 실습
// 결과가 아니라, 모델이라고 생각하면 된다.
[02. Part 2) 어디서 많이 봤던 패턴이다 싶을 때 - 빈발 패턴 탐색 - 01-1. 연관 규칙 탐색(이론)]
* 연관규칙이란?
- "A가 발생하면 B도 발생하더라"라는 형태의 규칙으로, 트랜잭션 데이터를 탐색하는데 사용
. A : 부모 아이템 집합 (antecedent)
. B : 자식 아이템 집합 (consequent)
. A 와 B 는 모두 공집합이 아닌 집합이며, A n B = 공집합 을 만족함 (즉, 공통되는 요소가 없다.)
- 규칙 예시
* 연관규칙 탐색이란?
- 트랜잭션 데이터에서 의미있는 연관규칙을 효율적으로 탐색하는 작업
// 연관규칙으로 만들 수 있는 경우의 수가 굉장히 많은데 그걸 효율적으로 탐색하는 작업이 필요하다.
* 연관규칙 탐색의 활용 사례 : 월마트
- 월마트에서는 엄청나게 많은 영수증 데이터에 대해 연관규칙 탐색을 적용하여, 매출을 향상시킨다.
* 연관규칙의 평가 척도
- 지지도 (supprot) : 아이템 집합이 전체 트랜잭션 데이터에서 발생한 비율
- 신뢰도 (confidence) : 부모 아이템 집합이 등장한 트랜잭션 데이터에서 자식 아이템 집합이 발생한 비율
- 지지도와 신뢰도가 높은 연관규칙을 좋은 규칙이라고 판단
* 연관규칙의 평가 척도 계산 예시
// 5 는 거래 ID 의 모든 수를 이야기 하고, 4 는 빵을 샀을 경우
* 아이템집합 격자
- 아이템 집합과 그 관계를 한 눈에 보여주기 위한 그래프
* 지지도에 대한 Apriori 원리 : 개요
- S (A -> B) 가 최소 지지도 (min supprot) 이상이면, 이 규칙을 빈발하다고 한다.
- 아이템 집합의 지지도가 최소 지지도 이상이면, 이 집합을 빈발하다고 한다.
- 지지도에 대한 Apriori 원리 : 어떤 아이템 집합이 빈발하면, 이 아이템의 부분 집합도 빈발한다.
* 지지도에 대한 Apriori 원리 : 작용
* 지지도에 대한 Apriori 원리 : 후보 규칙 생성
- Apriori 원리를 사용하여 모든 최대 빈발 아이템 집합을 찾은 후, 후보 규칙을 모두 생성한다.
. 최대 빈발 아이템 집합 : 최소 지지도 이상이면서, 이 집합의 모든 모집합이 빈발하지 않는 집합
pandas DataFrame the encoded format. Also supports DataFrames with sparse data; for more info, please see (https://pandas.pydata.org/pandas-docs/stable/ user_guide/sparse.html#sparse-data-structures)
Please note that the old pandas SparseDataFrame format is no longer supported in mlxtend >= 0.17.2.
The allowed values are either 0/1 or True/False. For example,
Apple Bananas Beer Chicken Milk Rice 0TrueFalseTrueTrueFalseTrue1TrueFalseTrueFalseFalseTrue2TrueFalseTrueFalseFalseFalse3TrueTrueFalseFalseFalseFalse4FalseFalseTrueTrueTrueTrue5FalseFalseTrueFalseTrueTrue6FalseFalseTrueFalseTrueFalse7TrueTrueFalseFalseFalseFalse
min_support: float (default: 0.5)
A float between 0 and 1 for minumum support of the itemsets returned. The support is computed as the fractiontransactions_where_item(s)_occur / total_transactions.
use_colnames: bool (default: False)
IfTrue, uses the DataFrames' column names in the returned DataFrame instead of column indices.
max_len: int (default: None)
Maximum length of the itemsets generated. IfNone(default) all possible itemsets lengths (under the apriori condition) are evaluated.
verbose: int (default: 0)
Shows the number of iterations if >= 1 andlow_memoryisTrue. If
=1 andlow_memoryisFalse, shows the number of combinations.
low_memory: bool (default: False)
IfTrue, uses an iterator to search for combinations abovemin_support. Note that whilelow_memory=Trueshould only be used for large dataset if memory resources are limited, because this implementation is approx. 3-6x slower than the default.
Returns
pandas DataFrame with columns ['support', 'itemsets'] of all itemsets that are >=min_supportand < thanmax_len(ifmax_lenis not None). Each itemset in the 'itemsets' column is of typefrozenset, which is a Python built-in type that behaves similarly to sets except that it is immutable (For more info, see https://docs.python.org/3.6/library/stdtypes.html#frozenset).
Generates a DataFrame of association rules including the metrics 'score', 'confidence', and 'lift'
Parameters
df: pandas DataFrame
pandas DataFrame of frequent itemsets with columns ['support', 'itemsets']
metric: string (default: 'confidence')
Metric to evaluate if a rule is of interest.Automatically set to 'support' ifsupport_only=True.Otherwise, supported metrics are 'support', 'confidence', 'lift',
'leverage', and 'conviction' These metrics are computed as follows:
Minimal threshold for the evaluation metric, via themetricparameter, to decide whether a candidate rule is of interest.
support_only: bool (default: False)
Only computes the rule support and fills the other metric columns with NaNs. This is useful if:
a) the input DataFrame is incomplete, e.g., does not contain support values for all rule antecedents and consequents
b) you simply want to speed up the computation because you don't need the other metrics.
Returns
pandas DataFrame with columns "antecedents" and "consequents" that store itemsets, plus the scoring metric columns: "antecedent support", "consequent support", "support", "confidence", "lift", "leverage", "conviction" of all rules for which metric(rule) >= min_threshold. Each entry in the "antecedents" and "consequents" columns are of typefrozenset, which is a Python built-in type that behaves similarly to sets except that it is immutable (For more info, see https://docs.python.org/3.6/library/stdtypes.html#frozenset).
The NumPy one-hot encoded boolean array of the input transactions, where the columns represent the unique items found in the input array in alphabetic order
The method works on simple estimators as well as on nested objects (such as pipelines). The latter have parameters of the form<component>__<parameter>so that it's possible to update each component of a nested object.
Returns
self
transform(X, sparse=False)
Transform transactions into a one-hot encoded NumPy array.
Parameters
X: list of lists
A python list of lists, where the outer list stores the n transactions and the inner list stores the items in each transaction.
if sparse=False (default). Compressed Sparse Row matrix otherwise The one-hot encoded boolean array of the input transactions, where the columns represent the unique items found in the input array in alphabetic order. Exact representation depends on the sparse argument
Convert categorical variable into dummy/indicator variables.
Parameters
dataarray-like, Series, or DataFrame
Data of which to get dummy indicators.
prefixstr, list of str, or dict of str, default None
String to append DataFrame column names. Pass a list with length equal to the number of columns when calling get_dummies on a DataFrame. Alternatively,prefixcan be a dictionary mapping column names to prefixes.
prefix_sepstr, default ‘_’
If appending prefix, separator/delimiter to use. Or pass a list or dictionary as withprefix.
dummy_nabool, default False
Add a column to indicate NaNs, if False NaNs are ignored.
columnslist-like, default None
Column names in the DataFrame to be encoded. Ifcolumnsis None then all the columns withobjectorcategorydtype will be converted.
sparsebool, default False
Whether the dummy-encoded columns should be backed by aSparseArray(True) or a regular NumPy array (False).
drop_firstbool, default False
Whether to get k-1 dummies out of k categorical levels by removing the first level.
dtypedtype, default np.uint8
Data type for new columns. Only a single dtype is allowed.
New in version 0.23.0.
Returns
DataFrame
Dummy-coded data.
* 다양한 거리 / 유사도 척도 : (1) 유킬리디안 거리
- 가장 흔하게 사용되는 거리 척도로 빛이 가는 거리로 정의된다.
// 벡터간 거리로 보면 된다.
// 특별한 제약이 있지는 않다. 가장 무난하게 쓸 수 있는 거리이다.
* 다양한 거리 / 유사도 척도 : (2) 맨하탄 거리
- 정수형 데이터 (예: 리커트 척도)에 적합한 거리 척도로, 수직 / 수평으로만 이동한 거리의 합으로 정의된다.
// 빌딩숲에서 거리를 가는 것과 비슷하다고 해서 맨해튼 거리이다.
// 설문조사(리커트 척도)를 위한 것에 주로 쓰인다고 보면 된다.
* 다양한 거리 / 유사도 척도 : (3) 코사인 유사도
- 스케일을 고려하지 않고 방향 유사도를 측정하는 상황(예: 상품 추천 시스템)에 주로 사용
// 핵심은 방향이 중요하다. 스케일은 전혀 중요하지 않다.
* 다양한 거리 /유사도 척도 : (4) 매칭 유사도
- 이진형 데이터에 적합한 유사도 척도로 전체 특징 중 일치하는 비율을 고려한다.
* 다양한 거리 / 유사도 척도 : (5) 자카드 유사도
- 이진형 데이터에 적합한 유사도 척도로 둘 중 하나라도 1을 가지는 특징 중 일치하는 비율을 고려한다.
- 희소한 이진형 데이터에 적합한 유사도 척도임
// 희소하다는 것은 대부분 0을 가진다고 보면 된다. 텍스트, 상품 데이터가 대부분 0으로 보면 된다.
// 스포츠카를 가지고 있는 사람끼리는 유사하다. .. 우연히 같은 것을 배제하기 위한 척도라고 보면 된다.
[02. Part 2) 탐색적 데이터 분석 Chapter 11. 비슷한 애들 모여라 - 군집화 - 02. 계층적 군집화 (이론)]
* 기본 개념
- 개별 샘플을 군집으로 간주하여, 거리가 가장 가까운 두 군집을 순차적으로 묶는 방식으로 큰 군집을 생성
// 최종적으로 하나의 군집으로 묶일때까지 묶다가 그중 하나를 선택해서 보는 것이다.
// 이전에 배웠던 것은 샘플간의 거리를 배웠다고 보면 된다.
* 군집 간 거리 : 최단 연결법
// 튀어나온 거리에 대해서 굉장히 민감하다고 볼 수 있다.
// 원래는 4 * 3 = 12 개의 계산량이 들어간다고 보면 된다.
* 군집 간 거리 : 최장 연결법
* 군집간 거리 : 평균 연결법
// 좀 더 직관적인 연결 방법
* 군집 간 거리 : 중심 연결법
// 다른 연결법과 달리 굉장히 많이 쓰이는 연결법이다.
* 군집 간 거리 : 와드 연결법
* 덴드로그램
- 계층 군집화 과정을 트리 형태로 보여주는 그래프
* 덴드로그램의 현실
- 덴드로그램은 샘플 수가 많은 경우에는 해석이 불가능할 정도로 복잡해진다는 문제가 있다.
// 100개 미만은 군집화가 필요 없을 것인데.. 샘플수가 7천개나되는 데이터가 위와 같다.
* 계층 군집화의 장단점
- 장점 (1) 덴드로그램을 이용한 군집화 과정 확인 가능
// 실제로는 데이터가 크면 그것도 쉽지가 않다는 의미이다.
- 장점 (2) 거리 / 유사도 행렬만 있으면 군집화 가능
- 장점 (3) 다양한 거리 척도 활용 가능
- 장점 (4) 수행할 때마다 같은 결과를 냄 (임의성 존재 x)
- 단점 (1) 상대적으로 많은 계산량 O(n^3)
// 데이터가 크면 그만큼 시간이 오래 걸린다.
- 단점 (2) 군집 개수 설정에 대한 제약 존재
* sklearn.cluster.AgglomerativeClustering
- 주요 입력
. n_clusters : 군집 개수
. affinity : 거리 척도 {"Euclidean", "manhattan", "cosine", "precomputed"}
.. linkage 가 ward 로 입력되면 "Euclidean"만 사용 가능함
// 그 이유는 각 군집마다 중심점을 필요로 하기 때문에 euclidean 은 중심을 표현하기 때문에 그런 것이다.
.. "precomputed" 는 거리 혹은 유사도 행렬을 입력으로 하는 경우에 설정하는 값
// 데이터를 바탕으로 거리를 계산하는 것이 아니다.
// 생각보다 많이 쓰는 키워드 설정이다.
. linkage : 군집 간 거리 { "ward", "complete", "average", "single"}
.. complete: 최장 연결법
.. average : 평균 연결법
.. single : 최단 연결법
- 주요 메서드
. fix(x) : 데이터 x에 대한 군집화 모델 학습
. fit_predict(x): 데이터 x 에 대한 군집화 모델 학습 및 라벨 반환
- 주요 속성
. labels_: fitting한 데이터에 있는 샘플들이 속한 군집 정보 (ndarray)
The number of clusters to find. It must beNoneifdistance_thresholdis notNone.
affinitystr or callable, default=’euclidean’
Metric used to compute the linkage. Can be “euclidean”, “l1”, “l2”, “manhattan”, “cosine”, or “precomputed”. If linkage is “ward”, only “euclidean” is accepted. If “precomputed”, a distance matrix (instead of a similarity matrix) is needed as input for the fit method.
memorystr or object with the joblib.Memory interface, default=None
Used to cache the output of the computation of the tree. By default, no caching is done. If a string is given, it is the path to the caching directory.
connectivityarray-like or callable, default=None
Connectivity matrix. Defines for each sample the neighboring samples following a given structure of the data. This can be a connectivity matrix itself or a callable that transforms the data into a connectivity matrix, such as derived from kneighbors_graph. Default is None, i.e, the hierarchical clustering algorithm is unstructured.
compute_full_tree‘auto’ or bool, default=’auto’
Stop early the construction of the tree at n_clusters. This is useful to decrease computation time if the number of clusters is not small compared to the number of samples. This option is useful only when specifying a connectivity matrix. Note also that when varying the number of clusters and using caching, it may be advantageous to compute the full tree. It must beTrueifdistance_thresholdis notNone. By defaultcompute_full_treeis “auto”, which is equivalent toTruewhendistance_thresholdis notNoneor thatn_clustersis inferior to the maximum between 100 or0.02*n_samples. Otherwise, “auto” is equivalent toFalse.
Which linkage criterion to use. The linkage criterion determines which distance to use between sets of observation. The algorithm will merge the pairs of cluster that minimize this criterion.
ward minimizes the variance of the clusters being merged.
average uses the average of the distances of each observation of the two sets.
complete or maximum linkage uses the maximum distances between all observations of the two sets.
single uses the minimum of the distances between all observations of the two sets.
New in version 0.20:Added the ‘single’ option
distance_thresholdfloat, default=None
The linkage distance threshold above which, clusters will not be merged. If notNone,n_clustersmust beNoneandcompute_full_treemust beTrue.
New in version 0.21.
Attributes
n_clusters_int
The number of clusters found by the algorithm. Ifdistance_threshold=None, it will be equal to the givenn_clusters.
labels_ndarray of shape (n_samples)
cluster labels for each point
n_leaves_int
Number of leaves in the hierarchical tree.
n_connected_components_int
The estimated number of connected components in the graph.
New in version 0.21:n_connected_components_was added to replacen_components_.
children_array-like of shape (n_samples-1, 2)
The children of each non-leaf node. Values less thann_samplescorrespond to leaves of the tree which are the original samples. A nodeigreater than or equal ton_samplesis a non-leaf node and has childrenchildren_[i-n_samples]. Alternatively at the i-th iteration, children[i][0] and children[i][1] are merged to form noden_samples+i
[파이썬을 활용한 데이터 전처리 Level UP-Comment] - 머신러닝에 대해서는 추후에 머신러닝 프로젝트에서 다룰 것이라서 간단하게 코멘트만 하고 넘어 갔는데.. 군집화 범주형에 대해서 처리를 할때 필요한 것이긴 하지만.. 어렵다. ㅠ.ㅠ.. 역시 이론만 들어서는 너무 어렵군.
The one-way ANOVA tests the null hypothesis that two or more groups have the same population mean. The test is applied to samples from two or more groups, possibly with differing sizes.
Parameters
sample1, sample2, …array_like
The sample measurements for each group. There must be at least two arguments. If the arrays are multidimensional, then all the dimensions of the array must be the same except for axis.
axisint, optional
Axis of the input arrays along which the test is applied. Default is 0.
Returns
statisticfloat
The computed F statistic of the test.
pvaluefloat
The associated p-value from the F distribution.
WarnsF_onewayConstantInputWarning
Raised if each of the input arrays is constant array. In this case the F statistic is either infinite or isn’t defined, so np.inf or np.nan is returned.
F_onewayBadInputSizesWarning
Raised if the length of any input array is 0, or if all the input arrays have length 1. np.nan is returned for the F statistic and the p-value in these cases.
Pearson correlation coefficient and p-value for testing non-correlation.
The Pearson correlation coefficient [1] measures the linear relationship between two datasets. The calculation of the p-value relies on the assumption that each dataset is normally distributed. (See Kowalski [3] for a discussion of the effects of non-normality of the input on the distribution of the correlation coefficient.) Like other correlation coefficients, this one varies between -1 and +1 with 0 implying no correlation. Correlations of -1 or +1 imply an exact linear relationship. Positive correlations imply that as x increases, so does y. Negative correlations imply that as x increases, y decreases.
The p-value roughly indicates the probability of an uncorrelated system producing datasets that have a Pearson correlation at least as extreme as the one computed from these datasets.
Parameters
x(N,) array_like
Input array.
y(N,) array_like
Input array.
Returns
rfloat
Pearson’s correlation coefficient.
p-valuefloat
Two-tailed p-value.
Warns
PearsonRConstantInputWarning
Raised if an input is a constant array. The correlation coefficient is not defined in this case, so np.nan is returned.
PearsonRNearConstantInputWarning
Raised if an input is “nearly” constant. The array x is considered nearly constant if norm(x - mean(x)) < 1e-13 * abs(mean(x)). Numerical errors in the calculation x - mean(x) in this case might result in an inaccurate calculation of r.
Compute pairwise correlation of columns, excluding NA/null values.
Parameters
method{‘pearson’, ‘kendall’, ‘spearman’} or callable
Method of correlation:
pearson : standard correlation coefficient
kendall : Kendall Tau correlation coefficient
spearman : Spearman rank correlation
callable: callable with input two 1d ndarrays
and returning a float. Note that the returned matrix from corr will have 1 along the diagonals and will be symmetric regardless of the callable’s behavior.
New in version 0.24.0.
min_periodsint, optional
Minimum number of observations required per pair of columns to have a valid result. Currently only available for Pearson and Spearman correlation.
Returns
DataFrame
Correlation matrix.
* 실습
// 처음은 양의 값.. 같이 증가 한다는 의미이다.
[02. Part 2) 탐색적 데이터 분석 Chapter 10. 둘 사이에는 무슨 관계가 있을까 - 가설 검정과 변수 간 관계 분석 - 04. 카이제곱검정]
* 카이제곱 검정 개요
- 목적 : 두 점부형 변수가 서로 독립적인지 검정
- 영 가설과 대립 가설
- 시각화 방법 : 교차 테이블
* 교차 테이블과 기대값
- 교차 테이블(contingency table) 은 두 변수가 취할 수 있는 값의 조합의 출현 빈도를 나타낸다.
- 예시 : 성별에 따른 강의 만족도 (카테고리 수 = 2 x 3 = 6)
// 빨간색은 기대값.
* 카이제곱 통계량
- 카이제곱 검정에 사용하는 카이제곱 통계량은 기대값과 실제값의 차이를 바탕으로 정의된다.
- 기대값과 실제값의 차이가 클수록 통계량이 커지며, 통계량이 커질수록 영 가설이 기각될 가능성이 높아진다. (즉, p-value 가 감소)
Compute a simple cross tabulation of two (or more) factors. By default computes a frequency table of the factors unless an array of values and an aggregation function are passed.
Parameters
indexarray-like, Series, or list of arrays/Series
Values to group by in the rows.
columnsarray-like, Series, or list of arrays/Series
Values to group by in the columns.
valuesarray-like, optional
Array of values to aggregate according to the factors. Requires aggfunc be specified.
rownamessequence, default None
If passed, must match number of row arrays passed.
colnamessequence, default None
If passed, must match number of column arrays passed.
aggfuncfunction, optional
If specified, requires values be specified as well.
marginsbool, default False
Add row/column margins (subtotals).
margins_namestr, default ‘All’
Name of the row/column that will contain the totals when margins is True.
dropnabool, default True
Do not include columns whose entries are all NaN.
normalizebool, {‘all’, ‘index’, ‘columns’}, or {0,1}, default False
Normalize by dividing all values by the sum of values.
If passed ‘all’ orTrue, will normalize over all values.
If passed ‘index’ will normalize over each row.
If passed ‘columns’ will normalize over each column.
If margins isTrue, will also normalize margin values.
Chi-square test of independence of variables in a contingency table.
This function computes the chi-square statistic and p-value for the hypothesis test of independence of the observed frequencies in the contingency table [1] observed. The expected frequencies are computed based on the marginal sums under the assumption of independence; see scipy.stats.contingency.expected_freq. The number of degrees of freedom is (expressed using numpy functions and attributes):
The contingency table. The table contains the observed frequencies (i.e. number of occurrences) in each category. In the two-dimensional case, the table is often described as an “R x C table”.
correctionbool, optional
If True, and the degrees of freedom is 1, apply Yates’ correction for continuity. The effect of the correction is to adjust each observed value by 0.5 towards the corresponding expected value.
lambda_float or str, optional.
By default, the statistic computed in this test is Pearson’s chi-squared statistic [2]. lambda_ allows a statistic from the Cressie-Read power divergence family [3] to be used instead. See power_divergence for details.
Returns
chi2float
The test statistic.
pfloat
The p-value of the test
dofint
Degrees of freedom
expectedndarray, same shape as observed
The expected frequencies, based on the marginal sums of the table.
* 실습
// pvalue 0.0018 로 두 변수 간 독립이 아님을 확인할 수 있다. 서로 종속적이다라고 확인할 수 있다.
[파이썬을 활용한 데이터 전처리 Level UP-Comment] - 일원분석.. 상관분석과 카이제곱 검정에서 대해서 알아봤다. 어렵다. 이론적인 배경 설명위주로 해서 그런지 넘 어렵게 느껴진다. ㅠ.ㅠ
Performs the (one sample or two samples) Kolmogorov-Smirnov test for goodness of fit.
The one-sample test performs a test of the distribution F(x) of an observed random variable against a given distribution G(x). Under the null hypothesis, the two distributions are identical, F(x)=G(x). The alternative hypothesis can be either ‘two-sided’ (default), ‘less’ or ‘greater’. The KS test is only valid for continuous distributions. The two-sample test tests whether the two independent samples are drawn from the same continuous distribution.
Parameters
rvsstr, array_like, or callable
If an array, it should be a 1-D array of observations of random variables. If a callable, it should be a function to generate random variables; it is required to have a keyword argumentsize. If a string, it should be the name of a distribution inscipy.stats, which will be used to generate random variables.
cdfstr, array_like or callable
If array_like, it should be a 1-D array of observations of random variables, and the two-sample test is performed (and rvs must be array_like) If a callable, that callable is used to calculate the cdf. If a string, it should be the name of a distribution inscipy.stats, which will be used as the cdf function.
argstuple, sequence, optional
Distribution parameters, used ifrvsorcdfare strings or callables.
Nint, optional
Sample size ifrvsis string or callable. Default is 20.
Calculate the T-test for the mean of ONE group of scores.
This is a two-sided test for the null hypothesis that the expected value (mean) of a sample of independent observationsais equal to the given population mean,popmean.
Parameters
aarray_like
Sample observation.
popmeanfloat or array_like
Expected value in null hypothesis. If array_like, then it must have the same shape asaexcluding the axis dimension.
axisint or None, optional
Axis along which to compute test. If None, compute over the whole arraya.
The Wilcoxon signed-rank test tests the null hypothesis that two related paired samples come from the same distribution. In particular, it tests whether the distribution of the differences x - y is symmetric about zero. It is a non-parametric version of the paired T-test.
Parameters
xarray_like
Either the first set of measurements (in which caseyis the second set of measurements), or the differences between two sets of measurements (in which caseyis not to be specified.) Must be one-dimensional.
yarray_like, optional
Either the second set of measurements (ifxis the first set of measurements), or not specified (ifxis the differences between two sets of measurements.) Must be one-dimensional.
The following options are available (default is ‘wilcox’):
‘pratt’: Includes zero-differences in the ranking process, but drops the ranks of the zeros, see[4], (more conservative).
‘wilcox’: Discards all zero-differences, the default.
‘zsplit’: Includes zero-differences in the ranking process and split the zero rank between positive and negative ones.
correctionbool, optional
If True, apply continuity correction by adjusting the Wilcoxon rank statistic by 0.5 towards the mean value when computing the z-statistic if a normal approximation is used. Default is False.
The alternative hypothesis to be tested, see Notes. Default is “two-sided”.
mode{“auto”, “exact”, “approx”}
Method to calculate the p-value, see Notes. Default is “auto”.
Returns
statisticfloat
Ifalternativeis “two-sided”, the sum of the ranks of the differences above or below zero, whichever is smaller. Otherwise the sum of the ranks of the differences above zero.
pvaluefloat
The p-value for the test depending onalternativeandmode.
* 실습
// 0.0 으로 나왔기 때문에 0.05보다 낮아서 정규성을 띈다고 볼 수 있다.
// 단일 표본 t 검정 수행
// 0.05 미만이므로 영가설은 기각되고, 통계량이 음수이므로 data 평균이 163보다 작는 것을 알 수 있다.
[02. Part 2) 탐색적 데이터 분석Chapter 10. 둘 사이에는 무슨 관계가 있을까 - 가설 검정과 변수 간 관계 분석 - 02. 독립 표본 t 검정]
* 독립 표본 t - 검정 개요
- 목적 : 서로 다른 두 그룹의 데이터 평균 비교
// 단일 표본 t-검정 보다는 더 많이 쓰인다.
- 영 가설과 대립 가설
- 가설 수립 예시 : 2020년 7월 한 달 간 지점 A의 일별 판매량과 지점 B의 일별 판매량이 아래와 같다면, 지점 A와 지점 B의 7월 판매량 간 유의미한 차이가 있는가?
The Levene test tests the null hypothesis that all input samples are from populations with equal variances. Levene’s test is an alternative to Bartlett’s testbartlettin the case where there are significant deviations from normality.
Calculate the T-test for the means oftwo independentsamples of scores.
This is a two-sided test for the null hypothesis that 2 independent samples have identical average (expected) values. This test assumes that the populations have identical variances by default.
Parameters
a, barray_like
The arrays must have the same shape, except in the dimension corresponding toaxis(the first, by default).
axisint or None, optional
Axis along which to compute test. If None, compute over the whole arrays,a, andb.
equal_varbool, optional
If True (default), perform a standard independent 2 sample test that assumes equal population variances[1]. If False, perform Welch’s t-test, which does not assume equal population variance[2].
Defines the alternative hypothesis. The following options are available (default is None):
None: computes p-value half the size of the ‘two-sided’ p-value and a different U statistic. The default behavior is not the same as using ‘less’ or ‘greater’; it only exists for backward compatibility and is deprecated.
‘two-sided’
‘less’: one-sided
‘greater’: one-sided
Use of the None option is deprecated.
Returns
statisticfloat
The Mann-Whitney U statistic, equal to min(U for x, U for y) ifalternativeis equal to None (deprecated; exists for backward compatibility), and U for y otherwise.
pvaluefloat
p-value assuming an asymptotic normal distribution. One-sided or two-sided, depending on the choice ofalternative.
* 실습
// scipy 에서는 Series 보다는 ndarray 가 더 낮기 때문에 values 를 만들어서 들고 있다.
// 만약에 NaN 값이 있다면 float 형태로 나오기 때문에 수치에서 .0 으로 나온다면 NaN 이 있다는 것을 알 고 있어야 한다.
[02. Part 2) 탐색적 데이터 분석Chapter 10. 둘 사이에는 무슨 관계가 있을까 - 가설 검정과 변수 간 관계 분석 - 03. 쌍체 표본 t 검정]
numpy.percentile(a, q, axis=None, out=None, overwrite_input=False, interpolation='linear', keepdims=False)
Compute the q-th percentile of the data along the specified axis.
Returns the q-th percentile(s) of the array elements.
Parameters
aarray_like
Input array or object that can be converted to an array.
qarray_like of float
Percentile or sequence of percentiles to compute, which must be between 0 and 100 inclusive.
axis{int, tuple of int, None}, optional
Axis or axes along which the percentiles are computed. The default is to compute the percentile(s) along a flattened version of the array.
Changed in version 1.9.0:A tuple of axes is supported
outndarray, optional
Alternative output array in which to place the result. It must have the same shape and buffer length as the expected output, but the type (of the output) will be cast if necessary.
overwrite_inputbool, optional
If True, then allow the input arrayato be modified by intermediate calculations, to save memory. In this case, the contents of the inputaafter this function completes is undefined.
This optional parameter specifies the interpolation method to use when the desired percentile lies between two data pointsi<j:
‘linear’:i+(j-i)*fraction, wherefractionis the fractional part of the index surrounded byiandj.
‘lower’:i.
‘higher’:j.
‘nearest’:iorj, whichever is nearest.
‘midpoint’:(i+j)/2.
New in version 1.9.0.
keepdimsbool, optional
If this is set to True, the axes which are reduced are left in the result as dimensions with size one. With this option, the result will broadcast correctly against the original arraya.
New in version 1.9.0.
Returns
percentilescalar or ndarray
Ifqis a single percentile andaxis=None, then the result is a scalar. If multiple percentiles are given, first axis of the result corresponds to the percentiles. The other axes are the axes that remain after the reduction ofa. If the input contains integers or floats smaller thanfloat64, the output data-type isfloat64. Otherwise, the output data-type is the same as that of the input. Ifoutis specified, that array is returned instead.
numpy.quantile(a, q, axis=None, out=None, overwrite_input=False, interpolation='linear', keepdims=False)
Compute the q-th quantile of the data along the specified axis.
New in version 1.15.0.
Parameters
aarray_like
Input array or object that can be converted to an array.
qarray_like of float
Quantile or sequence of quantiles to compute, which must be between 0 and 1 inclusive.
axis{int, tuple of int, None}, optional
Axis or axes along which the quantiles are computed. The default is to compute the quantile(s) along a flattened version of the array.
outndarray, optional
Alternative output array in which to place the result. It must have the same shape and buffer length as the expected output, but the type (of the output) will be cast if necessary.
overwrite_inputbool, optional
If True, then allow the input arrayato be modified by intermediate calculations, to save memory. In this case, the contents of the inputaafter this function completes is undefined.
This optional parameter specifies the interpolation method to use when the desired quantile lies between two data pointsi<j:
linear:i+(j-i)*fraction, wherefractionis the fractional part of the index surrounded byiandj.
lower:i.
higher:j.
nearest:iorj, whichever is nearest.
midpoint:(i+j)/2.
keepdimsbool, optional
If this is set to True, the axes which are reduced are left in the result as dimensions with size one. With this option, the result will broadcast correctly against the original arraya.
Returns
quantilescalar or ndarray
Ifqis a single quantile andaxis=None, then the result is a scalar. If multiple quantiles are given, first axis of the result corresponds to the quantiles. The other axes are the axes that remain after the reduction ofa. If the input contains integers or floats smaller thanfloat64, the output data-type isfloat64. Otherwise, the output data-type is the same as that of the input. Ifoutis specified, that array is returned instead.
Input array or object that can be converted to an array.
axis{int, sequence of int, None}, optional
Axis or axes along which the medians are computed. The default is to compute the median along a flattened version of the array. A sequence of axes is supported since version 1.9.0.
outndarray, optional
Alternative output array in which to place the result. It must have the same shape and buffer length as the expected output, but the type (of the output) will be cast if necessary.
overwrite_inputbool, optional
If True, then allow use of memory of input arrayafor calculations. The input array will be modified by the call tomedian. This will save memory when you do not need to preserve the contents of the input array. Treat the input as undefined, but it will probably be fully or partially sorted. Default is False. Ifoverwrite_inputisTrueandais not already anndarray, an error will be raised.
keepdimsbool, optional
If this is set to True, the axes which are reduced are left in the result as dimensions with size one. With this option, the result will broadcast correctly against the originalarr.
New in version 1.9.0.
Returns
medianndarray
A new array holding the result. If the input contains integers or floats smaller thanfloat64, then the output data-type isnp.float64. Otherwise, the data-type of the output is the same as that of the input. Ifoutis specified, that array is returned instead.
* 실습
// 10% 값
* 왜도
- 왜도 (skewness) : 분포의 비대칭도를 나타내는 통계량
- 왜도가 음수면 오른쪾으로 치우친 것을 의미하며, 양수면 왼쪽으로 치우침을 의미한다.
// 0 일때는 정규분포형태라고 볼 수 있다.
- 일반적으로 왜도의 절대값이 1.5 이상이면 치우쳤다고 본다.
* 첨도
- 첨도 (kurtosis) : 데이터의 분포가 얼마나 뾰족한지를 의미한다. 즉, 첨도가 높을수록 이 변수가 좁은 범위에 많은 값들이 몰려있다고 할 수 있다.
For normally distributed data, the skewness should be about zero. For unimodal continuous distributions, a skewness value greater than zero means that there is more weight in the right tail of the distribution. The functionskewtestcan be used to determine if the skewness value is close enough to zero, statistically speaking.
Parameters
andarray
Input array.
axisint or None, optional
Axis along which skewness is calculated. Default is 0. If None, compute over the whole arraya.
biasbool, optional
If False, then the calculations are corrected for statistical bias.
Compute the kurtosis (Fisher or Pearson) of a dataset.
Kurtosis is the fourth central moment divided by the square of the variance. If Fisher’s definition is used, then 3.0 is subtracted from the result to give 0.0 for a normal distribution.
If bias is False then the kurtosis is calculated using k statistics to eliminate bias coming from biased moment estimators
Usekurtosistestto see if result is close enough to normal.
Parameters
aarray
Data for which the kurtosis is calculated.
axisint or None, optional
Axis along which the kurtosis is calculated. Default is 0. If None, compute over the whole arraya.
fisherbool, optional
If True, Fisher’s definition is used (normal ==> 0.0). If False, Pearson’s definition is used (normal ==> 3.0).
biasbool, optional
If False, then the calculations are corrected for statistical bias.
Defines how to handle when input contains nan. ‘propagate’ returns nan, ‘raise’ throws an error, ‘omit’ performs the calculations ignoring nan values. Default is ‘propagate’.
Returns
kurtosisarray
The kurtosis of values along an axis. If all values are equal, return -3 for Fisher’s definition and 0 for Pearson’s definition.
Return unbiased kurtosis over requested axis using Fisher’s definition of kurtosis (kurtosis of normal == 0.0). Normalized by N-1
Parameters: axis:{index (0)}
skipna: boolean, default True
level: int or level name, default None
numeric_only: boolean, default None
Returns: kurt:scalar or Series (if level specified)
* 실습
[02. Part 2) 탐색적 데이터 분석Chapter 09. 변수가 어떻게 생겼나 - 기초 통계 분석 - 05. 머신러닝에서의 기초 통계 분석]
* 변수 분포 문제 확인
- 머신러닝에서 각 변수를 이해하고, 특별한 분포 문제가 없는지 확인하기 위해 기초 통계 분석을 수행한다.
// 평균과 범위로 특징과 스케일링을 알 수 있다. 다시 말해서, 스케일의 편차를 줄인다고 보면 된다.
// 사분위는 이상치 제거를 볼 수가 있다.
// 왜도 같으면.. 1.5보다 크거나 작거나로 치우치는지를 확인해 볼수가 있다... 치우치거나 몰려 있게 되면 정규화를 통해 정의 할 수 있다.
[02. Part 2) 탐색적 데이터 분석Chapter 10. 둘 사이에는 무슨 관계가 있을까 - 가설 검정과 변수 간 관계 분석 - 01. 영가설과 대립가설, p-value]
* 통계적 가설 검정 개요
- 갖고 있는 샘플을 가지고 모집단의 특성에 대한 가설에 대한 통계적 유의성을 검정하는 일련의 과정
. 수집한 데이터는 매우 특별한 경우를 제외하고는 전부 샘플이며, 모집단은 정확히 알 수 없는 경우가 더 많다.
// 모집단을 정확히 알 수는 없다. 예를 들어 대한민국 남성의 모든 키를 알 수는 없고, 단지 수집한 자료를 가지고 활용할 것이다.
// 보통은 모집단을 알 수 없는 경우가 대부분이다.
. 통계적 유의성 : 어떤 실험 결과 (데이터)가 확률적으로 봐서 단순한 우연이 아니라고 판단될 정도로 의미가 있다.
- 통계적 가설 검정 과정은 다음과 같이 5단계로 구성된다.
* 영 가설과 대립 가설
- 영 가설 (null hypothesis)와 대립 가설(alternative hypothesis)로 구분하여, 가설을 수립해야 한다.
// 영 가설 -> 귀무가설
// 대립 가설 -> 우리가 알고 싶은 대상에 대한 가설
// 영 가설 -> 범죄자는 무죄이다.
// 대립 가설에서는 죄를 찾기 위해서 증거를 수집한다는 예로 들어서 생각해 볼 수 있다.
// 대립 가설 (H 알파..A 가 아니라)
// 양측 검정 -> 키가 크거나 작아도 되므로, 양측 검정
// 단측 검정 -> 성인 남성의 키가 크다라는 검을 검정한다는 의미로 생각하면 된다.
* 오류의 구분
- 가설 검정에서 발생하는 오류는 참을 거짓이라 하는 제 1종 오류 (type 1 Error)와 거짓을 참이라 하는 제 2종 오류로 구분된다.
// 샘플을 가지고 검증하기 때문에 오류가 반드시 난다고 생각하면 된다.
* 유의 확률, p-value
- 유의 확률 p-value : 영 가설이 맞다고 가정할 때 얻은 결과와 다른 결과가 관측될 확률로, 그 값이 작을수록 영 가설을 기각할 근거가 된다.
// 유의 확률, 영 가설, p-value 만 알아도 통계측에서는 90%이상 이해했다고 보면 된다.
- 보통, p-value 가 0.05 혹은 0.01 미만이면 영 가설을 기각한다.
// 영 가설을 기각한다고 해서 반드시 대립 가설이 참인것은 아니다. 새로운 검증을 해봐야 한다.
* 유의 확률, p-value (예시1)
- 영 가설 : 대한민국 성인 남성의 키는 160 cm 일 것이다.
- 대립 가설 : 대한민국 성인 남성의 키는 160 cm 이상일 것이다.
- 관측한 대한민국 성인 남성의 키의 평균은 175 cm, 표준편차는 1cm 이다.
* 유의 확률, p-value (예시2)
- 영 가설 : 대란민국 성인 남성의 키는 여성의 키와 같을 것이다.
- 대립 가설 : 대한민국 성인 남성의 키는 여성의 키보다 작다.
[파이썬을 활용한 데이터 전처리 Level UP-Comment] - 영가설, 대립가설, p-value 에 대해서 배웠다. p-value
- p-value
The p-value is about the strength of a hypothesis. We build hypothesis based on some statistical model and compare the model's validity using p-value. One way to get the p-value is by using T-test.
This is a two-sided test for the null hypothesis that the expected value (mean) of a sample of independent observations ‘a’ is equal to the given population mean,popmean. Let us consider the following example.
Compute the arithmetic mean along the specified axis.
Returns the average of the array elements. The average is taken over the flattened array by default, otherwise over the specified axis.float64intermediate and return values are used for integer inputs.
Parameters
a array_like
Array containing numbers whose mean is desired. Ifais not an array, a conversion is attempted.
axis None or int or tuple of ints, optional
Axis or axes along which the means are computed. The default is to compute the mean of the flattened array.
New in version 1.7.0.
If this is a tuple of ints, a mean is performed over multiple axes, instead of a single axis or all the axes as before.
dtype data-type, optional
Type to use in computing the mean. For integer inputs, the default isfloat64; for floating point inputs, it is the same as the input dtype.
out ndarray, optional
Alternate output array in which to place the result. The default isNone; if provided, it must have the same shape as the expected output, but the type will be cast if necessary. Seeufuncs-output-typefor more details.
keepdims bool, optional
If this is set to True, the axes which are reduced are left in the result as dimensions with size one. With this option, the result will broadcast correctly against the input array.
If the default value is passed, thenkeepdimswill not be passed through to themeanmethod of sub-classes ofndarray, however any non-default value will be. If the sub-class’ method does not implementkeepdimsany exceptions will be raised.
Returns
m ndarray, see dtype parameter above
Ifout=None, returns a new array containing the mean values, otherwise a reference to the output array is returned.
Calculate the harmonic mean along the specified axis.
That is: n / (1/x1 + 1/x2 + … + 1/xn)
Parameters
a array_like
Input array, masked array or object that can be converted to an array.
axis int or None, optional
Axis along which the harmonic mean is computed. Default is 0. If None, compute over the whole arraya.
dtype dtype, optional
Type of the returned array and of the accumulator in which the elements are summed. Ifdtypeis not specified, it defaults to the dtype ofa, unlessahas an integerdtypewith a precision less than that of the default platform integer. In that case, the default platform integer is used.
Return mean of array after trimming distribution from both tails.
Ifproportiontocut= 0.1, slices off ‘leftmost’ and ‘rightmost’ 10% of scores. The input is sorted before slicing. Slices off less if proportion results in a non-integer slice index (i.e., conservatively slices offproportiontocut).
Parameters
a array_like
Input array.
proportiontocut float
Fraction to cut off of both tails of the distribution.
axis int or None, optional
Axis along which the trimmed means are computed. Default is 0. If None, compute over the whole arraya.
Returns
trim_mean ndarray
Mean of trimmed array.
* 실습
// 100명의 소득 기준으로 해야하지, 1명의 값 10억원으로 갑자기 뛰면 평균 자체가 우리가 생각하는 평균에 비해서 다르게 나온다.
// trim_mean(income, 0.2) # [20% ~ 80%] 으로 하면 원래 1명을 제외한 기대값으로 나올 수가 있다.
* 최빈값
- 한 변수가 가장 많이 취한 값을 의미하며, 범주형 변수에 대해서만 적용한다.
- 파이썬을 이용한 최빈값 계산
. scipy.stats.mode(x)
. Series.value_counts().index[0] (주의 : 최빈값이 둘 이상이면 사용 불가)
// 값의 빈도에 따라서 정의 해주는 것이다.
* 실습
[02. Part 2) 탐색적 데이터 분석Chapter 09. 변수가 어떻게 생겼나 - 기초 통계 분석 - 03. 산포 통계량]
* 개요
- 산포란 데이터가 얼마나 퍼져있는지를 의미한다.
- 즉, 산포 통계량이란 데이터의 산포를 나타내는 통계량이라고 할 수 있다.
// 두 그래프 모두 확률 밀도 함수이다.
* 분산, 표준편차
- 편차 : 한 샘플이 평균으로부터 떨어진 거리, xi - u (xi : i 번째 관측치, u : 평균)
- 분산 : 편차의 제곱의 평균
-> 편차의 합은 항상 0이 되기 때문에, 제곱을 사용
-> 자유도가 0 (모분산)이면 n - 1 으로 나누지 않고, n 으로 나눔
- 표준편차 : 분산에 루트를 씌운 것
-> 분산에서 제곱의 영향을 없앤 지표
* 변동계수
- 분산과 표준 편차 모두 값의 스케일에 크게 영향을 받아, 상대적인 산포를 보여주는데 부적합하다.
Returns the variance of the array elements, a measure of the spread of a distribution. The variance is computed for the flattened array by default, otherwise over the specified axis.
Parameters
aarray_like
Array containing numbers whose variance is desired. Ifais not an array, a conversion is attempted.
axisNone or int or tuple of ints, optional
Axis or axes along which the variance is computed. The default is to compute the variance of the flattened array.
New in version 1.7.0.
If this is a tuple of ints, a variance is performed over multiple axes, instead of a single axis or all the axes as before.
dtypedata-type, optional
Type to use in computing the variance. For arrays of integer type the default isfloat64; for arrays of float types it is the same as the array type.
outndarray, optional
Alternate output array in which to place the result. It must have the same shape as the expected output, but the type is cast if necessary.
ddofint, optional
“Delta Degrees of Freedom”: the divisor used in the calculation isN-ddof, whereNrepresents the number of elements. By defaultddofis zero.
keepdimsbool, optional
If this is set to True, the axes which are reduced are left in the result as dimensions with size one. With this option, the result will broadcast correctly against the input array.
If the default value is passed, thenkeepdimswill not be passed through to thevarmethod of sub-classes ofndarray, however any non-default value will be. If the sub-class’ method does not implementkeepdimsany exceptions will be raised.
Returns
variancendarray, see dtype parameter above
Ifout=None, returns a new array containing the variance; otherwise, a reference to the output array is returned.
Compute the standard deviation along the specified axis.
Returns the standard deviation, a measure of the spread of a distribution, of the array elements. The standard deviation is computed for the flattened array by default, otherwise over the specified axis.
Parameters
aarray_like
Calculate the standard deviation of these values.
axisNone or int or tuple of ints, optional
Axis or axes along which the standard deviation is computed. The default is to compute the standard deviation of the flattened array.
New in version 1.7.0.
If this is a tuple of ints, a standard deviation is performed over multiple axes, instead of a single axis or all the axes as before.
dtypedtype, optional
Type to use in computing the standard deviation. For arrays of integer type the default is float64, for arrays of float types it is the same as the array type.
outndarray, optional
Alternative output array in which to place the result. It must have the same shape as the expected output but the type (of the calculated values) will be cast if necessary.
ddofint, optional
Means Delta Degrees of Freedom. The divisor used in calculations isN-ddof, whereNrepresents the number of elements. By defaultddofis zero.
keepdimsbool, optional
If this is set to True, the axes which are reduced are left in the result as dimensions with size one. With this option, the result will broadcast correctly against the input array.
If the default value is passed, thenkeepdimswill not be passed through to thestdmethod of sub-classes ofndarray, however any non-default value will be. If the sub-class’ method does not implementkeepdimsany exceptions will be raised.
Returns
standard_deviationndarray, see dtype parameter above.
Ifoutis None, return a new array containing the standard deviation, otherwise return a reference to the output array.
class sklearn.preprocessing.StandardScaler(*, copy=True, with_mean=True, with_std=True)
Standardize features by removing the mean and scaling to unit variance
The standard score of a samplexis calculated as:
z = (x - u) / s
whereuis the mean of the training samples or zero ifwith_mean=False, andsis the standard deviation of the training samples or one ifwith_std=False.
Centering and scaling happen independently on each feature by computing the relevant statistics on the samples in the training set. Mean and standard deviation are then stored to be used on later data usingtransform.
Standardization of a dataset is a common requirement for many machine learning estimators: they might behave badly if the individual features do not more or less look like standard normally distributed data (e.g. Gaussian with 0 mean and unit variance).
For instance many elements used in the objective function of a learning algorithm (such as the RBF kernel of Support Vector Machines or the L1 and L2 regularizers of linear models) assume that all features are centered around 0 and have variance in the same order. If a feature has a variance that is orders of magnitude larger that others, it might dominate the objective function and make the estimator unable to learn from other features correctly as expected.
This scaler can also be applied to sparse CSR or CSC matrices by passingwith_mean=Falseto avoid breaking the sparsity structure of the data.
If False, try to avoid a copy and do inplace scaling instead. This is not guaranteed to always work inplace; e.g. if the data is not a NumPy array or scipy.sparse CSR matrix, a copy may still be returned.
with_meanboolean, True by default
If True, center the data before scaling. This does not work (and will raise an exception) when attempted on sparse matrices, because centering them entails building a dense matrix which in common use cases is likely to be too large to fit in memory.
with_stdboolean, True by default
If True, scale the data to unit variance (or equivalently, unit standard deviation).
Attributes
scale_ndarray or None, shape (n_features,)
Per feature relative scaling of the data. This is calculated usingnp.sqrt(var_). Equal toNonewhenwith_std=False.
New in version 0.17:scale_
mean_ndarray or None, shape (n_features,)
The mean value for each feature in the training set. Equal toNonewhenwith_mean=False.
var_ndarray or None, shape (n_features,)
The variance for each feature in the training set. Used to computescale_. Equal toNonewhenwith_std=False.
n_samples_seen_int or array, shape (n_features,)
The number of samples processed by the estimator for each feature. If there are not missing samples, then_samples_seenwill be an integer, otherwise it will be an array. Will be reset on new calls to fit, but increments acrosspartial_fitcalls.
Range of values (maximum - minimum) along an axis.
The name of the function comes from the acronym for ‘peak to peak’.
Parameters:
a:array_like
Input values.
axis:None or int or tuple of ints, optional
Axis along which to find the peaks. By default, flatten the array.axismay be negative, in which case it counts from the last to the first axis.
New in version 1.15.0.
If this is a tuple of ints, a reduction is performed on multiple axes, instead of a single axis or all the axes as before.
out:array_like
Alternative output array in which to place the result. It must have the same shape and buffer length as the expected output, but the type of the output values will be cast if necessary.
keepdims:bool, optional
If this is set to True, the axes which are reduced are left in the result as dimensions with size one. With this option, the result will broadcast correctly against the input array.
If the default value is passed, thenkeepdimswill not be passed through to theptpmethod of sub-classes ofndarray, however any non-default value will be. If the sub-class’ method does not implementkeepdimsany exceptions will be raised.
Returns:
ptp:ndarray
A new array holding the result, unlessoutwas specified, in which case a reference tooutis returned.
numpy.quantile(a, q, axis=None, out=None, overwrite_input=False, interpolation='linear', keepdims=False)
Compute the q-th quantile of the data along the specified axis.
New in version 1.15.0.
Parameters
aarray_like
Input array or object that can be converted to an array.
qarray_like of float
Quantile or sequence of quantiles to compute, which must be between 0 and 1 inclusive.
axis{int, tuple of int, None}, optional
Axis or axes along which the quantiles are computed. The default is to compute the quantile(s) along a flattened version of the array.
outndarray, optional
Alternative output array in which to place the result. It must have the same shape and buffer length as the expected output, but the type (of the output) will be cast if necessary.
overwrite_inputbool, optional
If True, then allow the input arrayato be modified by intermediate calculations, to save memory. In this case, the contents of the inputaafter this function completes is undefined.
This optional parameter specifies the interpolation method to use when the desired quantile lies between two data pointsi<j:
linear:i+(j-i)*fraction, wherefractionis the fractional part of the index surrounded byiandj.
lower:i.
higher:j.
nearest:iorj, whichever is nearest.
midpoint:(i+j)/2.
keepdimsbool, optional
If this is set to True, the axes which are reduced are left in the result as dimensions with size one. With this option, the result will broadcast correctly against the original arraya.
Returns
quantilescalar or ndarray
Ifqis a single quantile andaxis=None, then the result is a scalar. If multiple quantiles are given, first axis of the result corresponds to the quantiles. The other axes are the axes that remain after the reduction ofa. If the input contains integers or floats smaller thanfloat64, the output data-type isfloat64. Otherwise, the output data-type is the same as that of the input. Ifoutis specified, that array is returned instead.
Compute the interquartile range of the data along the specified axis.
The interquartile range (IQR) is the difference between the 75th and 25th percentile of the data. It is a measure of the dispersion similar to standard deviation or variance, but is much more robust against outliers[2].
Therngparameter allows this function to compute other percentile ranges than the actual IQR. For example, settingrng=(0,100)is equivalent tonumpy.ptp.
The IQR of an empty array isnp.nan.
New in version 0.18.0.
Parameters
xarray_like
Input array or object that can be converted to an array.
axisint or sequence of int, optional
Axis along which the range is computed. The default is to compute the IQR for the entire array.
rngTwo-element sequence containing floats in range of [0,100] optional
Percentiles over which to compute the range. Each must be between 0 and 100, inclusive. The default is the true IQR:(25, 75). The order of the elements is not important.
scalescalar or str, optional
The numerical value of scale will be divided out of the final result. The following string values are recognized:
‘raw’ : No scaling, just return the raw IQR.Deprecated!Usescale=1instead.
‘normal’ : Scale by22erf−1(12)≈1.349.
The default is 1.0. The use of scale=’raw’ is deprecated. Array-like scale is also allowed, as long as it broadcasts correctly to the output such thatout/scaleis a valid operation. The output dimensions depend on the input array,x, theaxisargument, and thekeepdimsflag.
Specifies the interpolation method to use when the percentile boundaries lie between two data pointsiandj. The following options are available (default is ‘linear’):
‘linear’:i + (j - i) * fraction, wherefractionis the fractional part of the index surrounded byiandj.
‘lower’:i.
‘higher’:j.
‘nearest’:iorjwhichever is nearest.
‘midpoint’:(i + j) / 2.
keepdimsbool, optional
If this is set toTrue, the reduced axes are left in the result as dimensions with size one. With this option, the result will broadcast correctly against the original arrayx.
Returns
iqrscalar or ndarray
Ifaxis=None, a scalar is returned. If the input contains integers or floats of smaller precision thannp.float64, then the output data-type isnp.float64. Otherwise, the output data-type is the same as that of the input.
[파이썬을 활용한 데이터 전처리 Level UP-Comment] - 분포를 사용하고, 스케일링에 대해서 배워 볼 수 있었다. 다소 학문적인 내용이 많아서 한번에 이해하기는 어려웠지만..
패치#노트코딩, 주식, 자동매매, 백테스팅, 데이터분석 등 관심 블로그
비전공자이지만 금융 및 관련 프로그래밍에 관심을 두고 열심히 공부중입니다.
우리 모두 경제적 자유를 위해 성공해봅시다!!
※ 혹시, 블로그 내용중 문제되는 내용있으시면 알려주시면 삭제/수정 토록하겠습니다.
※ 모든 내용들은 투자 권유가 아니오니 참고만 하시고, 또한 출처는 모두 표기토록 노력하겠으나 혹시 문제가 되는 글이 있다면 댓글로 남겨주세요~^^