[패스트캠퍼스 수강 후기] 데이터전처리 100% 환급 챌린지 18회차 미션 Programming/Python2020. 11. 19. 12:02
[파이썬을 활용한 데이터 전처리 Level UP- 18 회차 미션 시작]
* 복습
- 빈발 개념에 대해서 배웠으나 약간의 개념 정리가 필요한 것 같다. 어떤 sequence 를 이뤄서 나타내는 조건들에 대해서 분석을 해보고, 어똔 조건에서 어떠한 결과물을 내놓는 것에 대해서는 좀 더 연구가 필요하지 않나 싶다.
[02. Part 2) Ch 12. 어디서 많이 봤던 패턴이다 싶을 때 - 빈발 패턴 탐색 - 03. 빈발 시계열 패턴 탐색]

* 시계열 데이터란?
- 시계열 데이터란 각 요소가 (시간, 값) 형태로 구성된 데이터로, 반드시 순서 및 시간을 고려해야 한다.

* 시계열과 시퀀스 데이터의 차이
- 시계열 데이터와 시퀀스 데이터는 사용하는 인덱스와 값의 종류로 다음과 같이 구분할 수 있다.

- 다만, 엄밀히 말해서 시계열 데이터도 시퀀스 데이터에 속한다.
// 시퀀스 데이터에 속하기는 하지만 표를 참고하는 것이 더 좋다.
* 시계열 패턴의 정의
- 시계열의 패턴은 크게 모양, 변화에 의한 패턴과 값에 의한 패턴으로 구분할 수 있다.
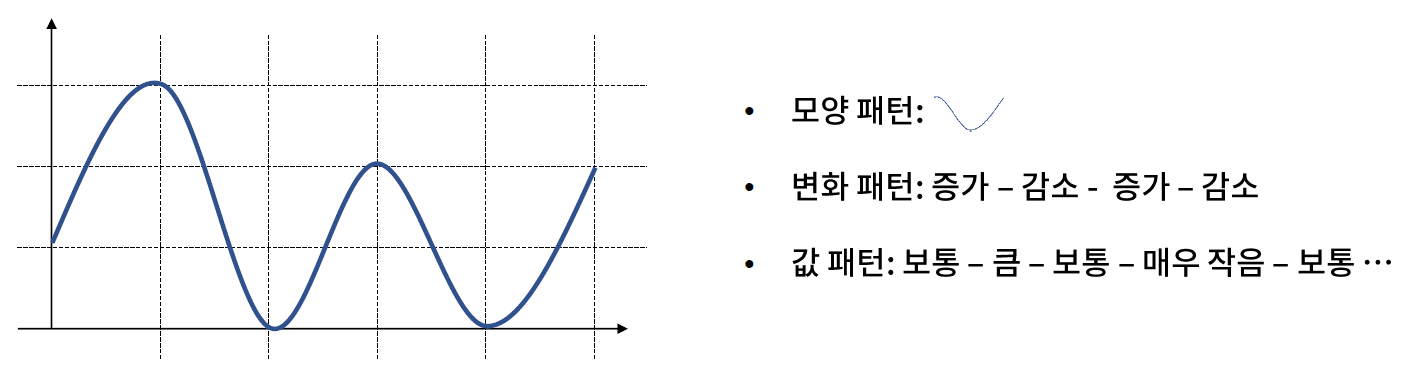
- 계절성 혹은 주기성이 있는 경우를 제외하면, 모양 패턴을 찾는 것은 거의 불가능에 가깝다.
* SAX : 시계열 -> 시퀀스
- 시계열 데이터는 연속형이라는 특징 때문에 패턴을 찾으려면 이산화가 필요하며, SAX (symbolic aggregate approximatinon) 을 사용하면 시계열 데이터를 효과적으로 이산화할 수 있다.
// 범주화 하기 위한 방법이라고 보면 된다.
- SAX 는 (1)원도우 분할, (2) 원도우별 대표값 계산, (3) 알파벳 시퀀스로 변환이라는 세 단계로 구성된다.

* 실습

// 날짜가 포함되어 있기 때문에 parse_date = True 로 두고 불러 온다.
// 인덱스가 날짜, 좀더 큰 범위로 시간이라고 보면 된다.
// 다별량 시계열은 하나의 시간에 더 많은 데이터가 붙어 있는 것이다.
// 하나만 있는 것은 단별량 시계열이라고 한다.
// 다별량 시계열의 경우가 더 분석하기 힘들다.
// segmentation 정의하기
// x : time seires sample, w : windows size, a : alphabe size
// 정상적으로 들어가는 window에 대해서만 처리 해주고...
// 행별 평균을 구한다. mean(axis =1 ) => 결과는 반드시 벡터 일 것이다.
// find_break_pints
// 구간의 범위의 기준선들을 의미한다.
// wmv : windows mean vector
// conversion_window 정의
// chr( ) 아시키 코드를 알파벳으로 바꿔주는 것이다.
// python 내장 함수 chr( )
docs.python.org/3/library/functions.html#chr
chr(i)Return the string representing a character whose Unicode code point is the integer i. For example, chr(97) returns the string 'a', while chr(8364) returns the string '€'. This is the inverse of ord().
The valid range for the argument is from 0 through 1,114,111 (0x10FFFF in base 16). ValueError will be raised if i is outside that range.
@classmethod
Transform a method into a class method.
A class method receives the class as implicit first argument, just like an instance method receives the instance. To declare a class method, use this idiom:
class C:
@classmethod
def f(cls, arg1, arg2, ...): ...The @classmethod form is a function decorator – see Function definitions for details.
A class method can be called either on the class (such as C.f()) or on an instance (such as C().f()). The instance is ignored except for its class. If a class method is called for a derived class, the derived class object is passed as the implied first argument.
Class methods are different than C++ or Java static methods. If you want those, see staticmethod() in this section. For more information on class methods, see The standard type hierarchy.
Changed in version 3.9: Class methods can now wrap other descriptors such as property().
// 패턴 찾기
// 문자열로 변환 (하나의 리스트만 대상으로 하기에, 이렇게 하는 것이 더 수월)
// join 으로 각 alphabet 을 붙여줌.
// find_maximum_frequent_sequence_item 함수

// 각각의 신뢰도와 지지도를 확인해 볼 수 있다.
[02. Part 2) Ch 12. 어디서 많이 봤던 패턴이다 싶을 때 - 빈발 패턴 탐색 - 04. 머신러닝에서의 빈발 패턴 탐색]

* 추천 시스템
- "상품 A 를 구매하면 상품 B 도 구매할 것이다" 라는 유의한 연관 규칙이 있다면, 상품 A 를 구매하고 상품 B 를 구매하지 않은 고객에게 상품 B 를 추천해주는 방법에 활용
// 가장 대표적인 것
- (예시) 아마존의 도서 추천
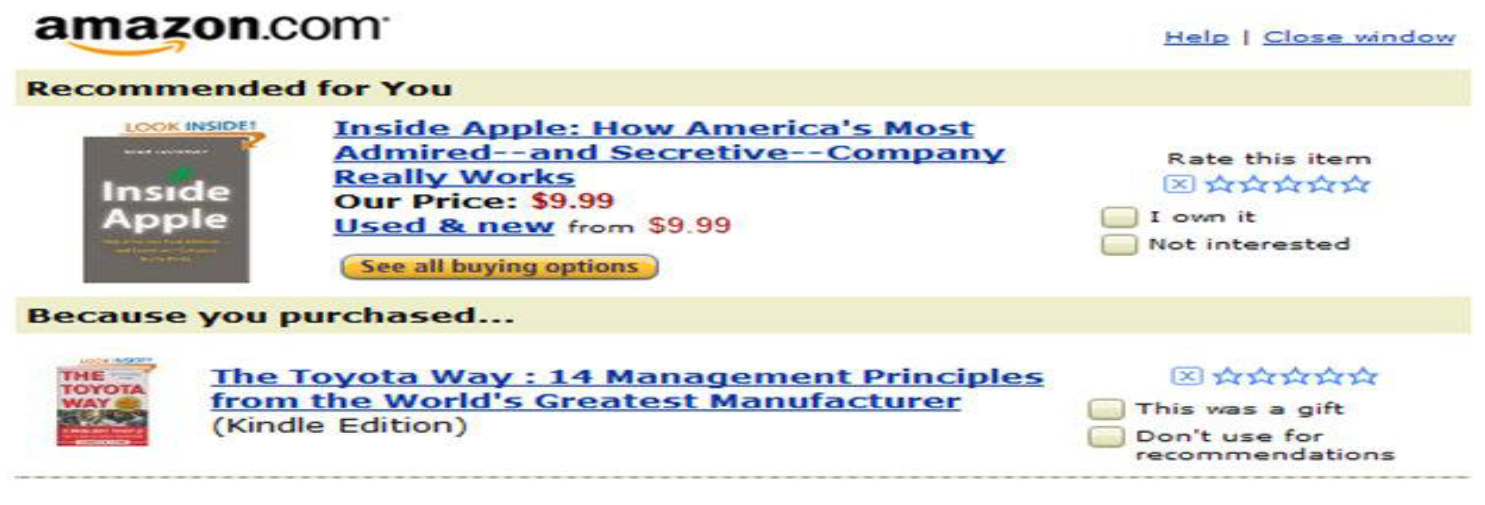
* 시계열 및 시퀀스 데이터에서의 특징 추출
- 시계열 및 시퀀스 분류 과제에서 특징을 추출하는데도 활용

// 원도우 크기를 정렬해줘야 한다.
// 지도 학습 또는 비지도 학습에 활용할 수 있다는 점이 있다.
[02. Part 2) Ch 13. 직접 해봐야 내것이 된다. - 01. A-B 테스트 - 홈페이지 화면을 어떻게 구성할 것인가 - (문제)]

* A/B 테스트란?
- 임의로 나눈 둘 이상의 집단에 서로 다른 컨텐츠를 제시한 뒤, 통계적 가설 검정을 이용하여 어느 컨텐츠에 대한 반응이 더 효과적인지를 파악하는 방법

ko.wikipedia.org/wiki/A/B_%ED%85%8C%EC%8A%A4%ED%8A%B8
A/B 테스트 - 위키백과, 우리 모두의 백과사전
위키백과, 우리 모두의 백과사전. 웹 사이트에서의 A/B 테스트 예제. 한 웹 사이트에서 한 개의 버튼 요소의 디자인만 다른 두 가지 버전을 무작위로 방문자에게 제공해, 두 디자인의 상대적인 효
ko.wikipedia.org
A/B 테스트
웹 사이트에서의 A/B 테스트 예제. 한 웹 사이트에서 한 개의 버튼 요소의 디자인만 다른 두 가지 버전을 무작위로 방문자에게 제공해, 두 디자인의 상대적인 효용성을 측정할 수 있다.
마케팅과 웹 분석에서, A/B 테스트(버킷 테스트 또는 분할-실행 테스트)는 두 개의 변형 A와 B를 사용하는 종합 대조 실험(controlled experiment)이다.[1] 통계 영역에서 사용되는 것과 같은 통계적 가설 검정 또는 "2-표본 가설 검정"의 한 형태다. 웹 디자인 (특히 사용자 경험 디자인)과 같은 온라인 영역에서, A/B 테스트의 목표는 관심 분야에 대한 결과를 늘리거나 극대화하는 웹 페이지에 대한 변경 사항이 무엇인지를 규명하는 것이다(예를 들어, 배너 광고의 클릭률(click-through rate)). 공식적으로 현재 웹 페이지에 null 가설과 연관이 있다. A/B 테스트는 변수 A에 비해 대상이 변수 B에 대해 보이는 응답을 테스트하고, 두 변수 중 어떤 것이 더 효과적인지를 판단함으로써 단일 변수에 대한 두 가지 버전을 비교하는 방법이다.[2]
이름에서 알 수 있듯이, 두 버전(A와 B)이 비교되는데 사용자의 행동에 영향을 미칠 수 있는 하나의 변형을 제외하면 동일하다. 버전 A는 현재 사용되는 버전(control)이라고 하는 반면, 버전 B의 일부 사항은 수정된다(treatment). 예를 들어, 전자상거래 웹사이트에서 구매 깔때기은 일반적으로 A/B 테스트하기 좋은 대상으로, 하락률에 있어 수익 한계선에 대한 개선이 판매에 있어 상당한 이익을 나타낼 수 있기 때문이다. 항상 그런 것은 아니지만, 때때로 텍스트, 레이아웃, 이미지 그리고 색상과 같은 요소들을 테스트함으로써 현저한 향상을 볼 수 있다.[3]
다변량 테스트 또는 다항 테스트가 A/B 테스트와 유사하지만, 동시에 두 개 이상의 버전을 테스트하거나 좀 더 많은 컨트롤들을 테스트할 수 있다. 두 개 이상의 버전 또는 동시에 더 많이 사용을 제어한다. 단순한 A/B 테스트는 설문 데이터, 오프라인 데이터 그리고 다른 좀 더 복잡한 현상과 같이, 실측, 유사 실험 또는 기타 비 실험 상황에서는 유효하지 않다.
A/B 테스트는 그 접근 방식이 다양한 연구 관례에서 일반적으로 사용되는, 피험자간 설계와 유사하긴 하지만, 특정 틈새 영역에서 철학과 사업 전략의 변화로 마케팅되었다.[4][5][6] 웹 개발 철학으로서의 A/B 테스트는 해당 영역을 증거 기반의 실천으로의 폭넓은 움직임으로 이끈다. 대부분의 마케팅 자동화 도구가 현재 일반적으로 A/B 테스트를 지속적으로 실행할 수 있는 기능과 함께 제공되고 있기 때문에, A/B 테스트가 거의 모든 영역에서 지속적으로 수행될 수 있는 것으로 간주되는 것이 A/B 테스트의 이점이다. 이로써 현재의 리소스를 사용해 웹 사이트와 다른 도구를 업데이트해 트렌드 변화를 유지할 수 있다.
// 버튼이 어떻게 배치되었을 때 클릭을 많이 하는지에 대해서
* 문제상황
- 온라인 쇼핑몰 페이지 구성에 따른 다양한 실험 결과를 바탕으로 전환율이 최대가 되는 구성을 하고 싶다!
// 전환율은 어떤 상품을 구매율

- 관련 데이터 : AB 테스트 폴더 내 모든 데이터
* Step 1. 현황 파악
- 관련 데이터 : 일별현황데이터.csv
- 분석 내용
(1) 구매자수, 방문자수, 총 판매 금액에 대한 기술 통계
(2) 일자별 방문자수 추이 파악
(3) 일자별 구매자수 추이 파악
(4) 일자별 총 판매 금액 추이 파악
* Step 2. 상품 배치와 상품 구매 금액에 따른 관계 분석
- 관련 데이터
. 상품배치_A.csv
. 상품배치_B.csv
. 상품배치_C.csv
- 분석 내용
(1) 일원분산분석을 이용한 상품 배치에 따른 상품 구매 금액 평균 차이 분석 (상품 구매 금액 0원 미포함)
(2) 일원분산분석을 이용한 상품 배치에 따른 상품 구매 금액 평균 차이 분석 (상품 구매 금액 0원 포함)
(3) 카이제곱 검정을 이용한 구매 여부와 상품 배치 간 독립성 파악
// 서로 독립적인지를 확인해 볼 것이다.
* Step 3. 사이트맵 구성에 따른 체류 시간 차이 분석
- 관련 데이터
. 사이트맵_A.csv
. 사이트맵_B.csv
. 사이트맵_C.csv
- 분석 내용
(1) 사이트맵별 체류시간 평균 계산
(2) 일원분산분석을 이용한 사이트맵에 따른 체류 시간 평균 차이 분석 (박스 플롯 포함)
* Step 4. 할인 쿠폰의 효과 분석
- 관련 데이터 : 할인쿠폰 발행효과.csv
- 분석내용
(1) 발행후와 전의 구매 횟수 차이에 대한 기술 통계
(2) 발행전, 발행후의 구매 횟수에 대한 박스폴롯 시각화
(3) 쌍체 표본 t - 검정을 이용한 차이 유의성 검정
// 유의하지 않다면 굳이 할인쿠폰을 발행할 필요가 없는 것이다.
* Step 5. 체류 시간과 구매 금액 간 관계 분석
- 관련 데이터 : 체류시간_구매금액.csv
- 분석 내용
(1) 구매 금액과 체류 시간의 산점도 시각화
(2) 구매 금액과 체류 시간 간 상관관계 분석
* Step 6. 구매 버튼 배치에 따른 구매율 차이 분석
- 관련 데이터 : 구매버튼_버튼타입_통계.xlsx
- 분석내용
(1) 결측 대체
(2) pivot table을 이용한 교차 테이블 생성
(3) 카이제곱검정을 이용한 독립성 검정
[파이썬을 활용한 데이터 전처리 Level UP-Comment]
- 시계열 데이터와 빈발 패턴, 그리고 머신러닝에서의 활용에 대해서 어떻게 활용할 것인가에 대해서 배웠다. 그리고, 새로운 프로젝트를 통해서 어떻게 이것을 분석하고 검정하는지에 대한 문제에 대해 알아보았다.
다음에는 실습을 통해서 어떤식으로 해결해 나갈지를 알 수 있을 것이다.
파이썬을 활용한 데이터 전처리 Level UP 올인원 패키지 Online. | 패스트캠퍼스
데이터 분석에 필요한 기초 전처리부터, 데이터의 품질 및 머신러닝 성능 향상을 위한 고급 스킬까지 완전 정복하는 데이터 전처리 트레이닝 온라인 강의입니다.
www.fastcampus.co.kr
'Programming > Python' 카테고리의 다른 글
| [패스트캠퍼스 수강 후기] 데이터전처리 100% 환급 챌린지 20회차 미션 (0) | 2020.11.21 |
|---|---|
| [패스트캠퍼스 수강 후기] 데이터전처리 100% 환급 챌린지 19회차 미션 (0) | 2020.11.20 |
| [패스트캠퍼스 수강 후기] 데이터전처리 100% 환급 챌린지 17회차 미션 (0) | 2020.11.18 |
| [패스트캠퍼스 수강 후기] 데이터전처리 100% 환급 챌린지 16회차 미션 (0) | 2020.11.17 |
| [패스트캠퍼스 수강 후기] 데이터전처리 100% 환급 챌린지 15회차 미션 (0) | 2020.11.16 |


