[패스트캠퍼스 수강 후기] 데이터전처리 100% 환급 챌린지 23회차 미션 Programming/Python2020. 11. 24. 14:09
[파이썬을 활용한 데이터 전처리 Level UP- 23 회차 미션 시작]
* 복습
- 지도학습할 때의 Grid 서치 및 parameterGrid 에 대해서 배울 수 있었다. 지도 학습에 대해서는 추후에 좀 더 공부가 필요할 것 같다.
[03. Part 3) Ch 15. 이럴땐 이걸 쓰고, 저럴땐 저걸 쓰고 - 지도 학습 모델 & 파라미터 선택 - 04. 복잡도 파라미터 튜닝 방법]

* 복잡도 파라미터 튜닝 개요
- 복잡도 파라미터란 복잡도에 영향을 주는 파라미터로, 이 값에 따라 과적합 정도가 결정되므로 매우 신중하게 튜닝해야 한다.
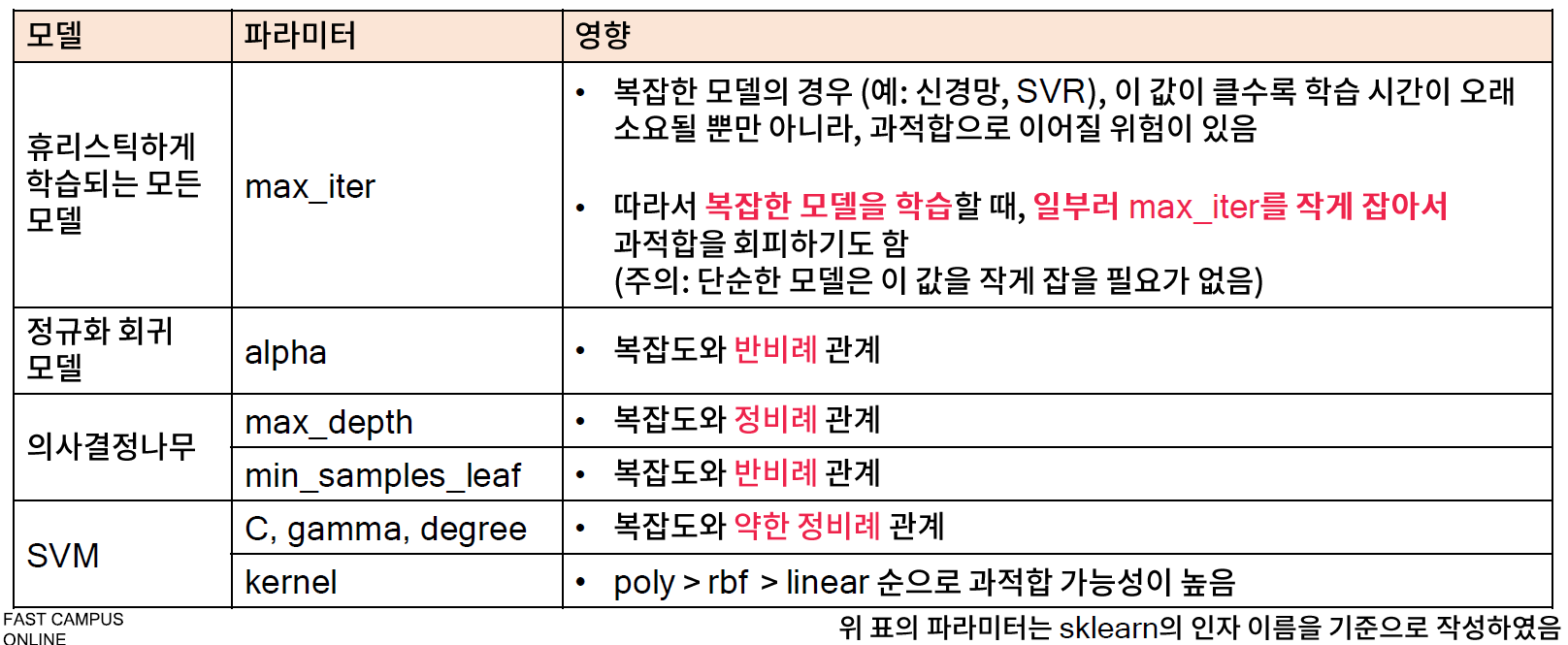
// 약하다는 의미는 복잡도에 영향을 줄수도 있고 안 줄 수도 있다는 있다는 의미이다.

* 학습시 우연성이 개입되는 모델의 복잡도 파라미터 튜닝
// 학습할 때마다 다른 값을 가지는 모델
- 경사하강법 등의 방법으로 학습되는 모델 (예 : 회귀모델, 신경망 등)은 초기 값에 의한 영향이 매우 크다.
- 따라서 복잡도 파라미터 변화에 따른 성능 변화의 패턴을 확인하기 어려운 경우가 많으므로, seed 를 고정한 뒤 튜닝을 수행해야 한다.
// 좋은 seed 를 알 수가 없다. seed 를 고정한 뒤 여러가지 서치를 해봐야 한다.
// seed 도 하나의 축으로 들어간다고 볼 수 있다.
* 복잡도 파라미터 튜닝
- seed 가 고정되어 있거나, 학습시 우연 요소가 개입되지 않는 모델의 경우에는 복잡도 파라미터에 따른 성능 변화 패턴 확인이 상대적으로 쉽다.
- 복잡도 파라미터가 둘 이상인 경우에는 서로 영향을 주기 때문에 반드시 두 파라미터를 같이 조정해야 한다.
- 파라미터 그리드 크기를 줄이기 위해, 몇 가지 파라미터 값을 테스트한 후 범위를 설정하는 것이 바람직하다.

* 실습

// 크로스 를 쓰면 좋겠지만 학습 데이터와 평가 데이터를 구분을 했다.
// 샘플 156 개, 특징 60 개 이 된다면 단순한 모델이 필요하다는 것이다.
// 일반적으로 단순한 모델이 좋을 가능성이 크다는 이야기이다.
// Case 1. 복잡도 파라미터가 한 개이면서, 단순하고, 우연성이 어느정도 있는 모델 (Logistic Regression)
// 테스트 함수 생성하고 파라미터 그리드를 통해서 튜닝을 해본다.
// Case 2. 복잡도 파라미터가 두 개이면서, 단순하고, 우연성이 거의 없는 모델 (Decision Tree)
// max depth 가 크고 (복잡도 증가) min_samples_leaf 가 큰 경우 (복잡도 감소) 좋은 성능이 나온다.

// Case 3. 복잡도 파라미터가 하나이면서, 우연성이 있는 모델 (신경망)
// (5, 5) f1 - score 가 0 이 나왔다는 것은 초기값의 영향으로 보인다.
// (10, ) 가 best score 가 나왔지만.. 좀 더 많은 판단을 위해서 확인 해봐야 한다. -> 벗어나는지 등을 결정해야 한다.
[04. Part 4) Ch 16. 흩어진 데이터 다 모여라 - 데이터 파편화 문제 - 01. 유형 (1) 파일 자체가 나뉘어 저장된 경우]

* 개요
- 지도학습 모델을 학습하려면 아래와 같이 반드시 하나의 통합된 데이터 집합이 필요하다.

- 많은 경우에 데이터가 두 개 이상으로 나뉘어져 있어, 이들을 반드시 통합하는 전처리를 수행해야 한다.
* 문제 정의 및 해결방안
- 센서, 로그, 거래 데이터 등과 같이 크기가 매우 큰 데이터는 시간과 ID 등에 따라 분할되어 저장된다.
- pandas.concat 함수를 사용하면 손쉽게 해결할 수 있다.

- 통합해야 하는 데이터가 많은 경우에는 빈 데이터 프레임을 생성한 뒤, 이 데이터 프레임과 반복문을 사용하여 불러온 데이터를 concat 함수를 이용하면 효율적으로 통합할 수 있다.
* 관련 문법 : pandas.concat
- 둘 이상의 데이터 프레임을 이어 붙이는 데 사용하는 함수
- 주요입력
. objs : DataFrame 을 요소로 하는 리스트 (입력 예시 : [df1, df2]) 로 입력 순서대로 병합이 된다.
. ignore_index : True 면 기존 인덱스를 무시하고 새로운 인덱스를 부여하며, False 면 기존 인덱스를 사용한다.

. axis : 0 이면 행 단위로 병합을 수행하며, 1 이면 열 단위로 병합을 수행한다.
* Tip. Axis 키워드
- axis 키워드는 numpy 및 pandas 의 많은 함수에 사용되는 키워드로, 연산 등을 수행할 때 축의 방향을 결정하는 역할을 한다.
- axis 가 0 이면 행을, 1 이면 열을 나타내지만 이렇게만 기억하면 논리적으로 이상한 점이 존재한다.
. (예시 1) sum(axis=0) : 열 기준 합
. (예시 2) concat([df1, df2][, axis = 0) : 행 단위 병합

- aixs 키워드는 그 함수의 결과 구조가 벡터 형태 (1차원) 인지, 행렬 형태 (2차원) 인지에 따라, 그 역할이 조금씩 다르다.

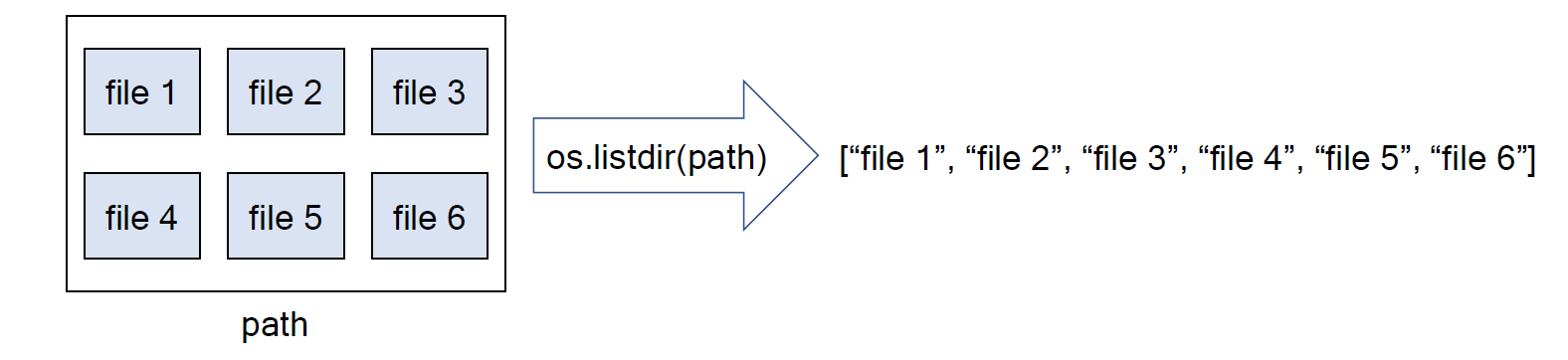
* 관련 문법 : os.listdir
- 주요 입력
. path : 입력된 경로 (path) 상에 있는 모든 파일명을 리스트 형태로 반환
* 실습
- 5월 데이터는 평가 데이터로 쓸거고, 5월 이전 데이터는 학습데이터로 쓸것이기 때문에 이렇게 작업한다.
// 이 함수에 대해서는 chatper 4에서도 공부를 했어지만 다시 한번 Dcoumentation 을 참고해 본다.
// pandas.concat Documentation
pandas.pydata.org/pandas-docs/stable/reference/api/pandas.concat.html
pandas.concat(objs: Union[Iterable[‘DataFrame’], Mapping[Label, ‘DataFrame’]], axis='0', join: str = "'outer'", ignore_index: bool = 'False', keys='None', levels='None', names='None', verify_integrity: bool = 'False', sort: bool = 'False', copy: bool = 'True') → ’DataFrame’
pandas.concat(objs: Union[Iterable[FrameOrSeries], Mapping[Label, FrameOrSeries]], axis='0', join: str = "'outer'", ignore_index: bool = 'False', keys='None', levels='None', names='None', verify_integrity: bool = 'False', sort: bool = 'False', copy: bool = 'True') → FrameOrSeriesUnionConcatenate pandas objects along a particular axis with optional set logic along the other axes.
Can also add a layer of hierarchical indexing on the concatenation axis, which may be useful if the labels are the same (or overlapping) on the passed axis number.
Parameters
objsa sequence or mapping of Series or DataFrame objects
If a mapping is passed, the sorted keys will be used as the keys argument, unless it is passed, in which case the values will be selected (see below). Any None objects will be dropped silently unless they are all None in which case a ValueError will be raised.
axis{0/’index’, 1/’columns’}, default 0
The axis to concatenate along.
join{‘inner’, ‘outer’}, default ‘outer’
How to handle indexes on other axis (or axes).
ignore_indexbool, default False
If True, do not use the index values along the concatenation axis. The resulting axis will be labeled 0, …, n - 1. This is useful if you are concatenating objects where the concatenation axis does not have meaningful indexing information. Note the index values on the other axes are still respected in the join.
keyssequence, default None
If multiple levels passed, should contain tuples. Construct hierarchical index using the passed keys as the outermost level.
levelslist of sequences, default None
Specific levels (unique values) to use for constructing a MultiIndex. Otherwise they will be inferred from the keys.
nameslist, default None
Names for the levels in the resulting hierarchical index.
verify_integritybool, default False
Check whether the new concatenated axis contains duplicates. This can be very expensive relative to the actual data concatenation.
sortbool, default False
Sort non-concatenation axis if it is not already aligned when join is ‘outer’. This has no effect when join='inner', which already preserves the order of the non-concatenation axis.
New in version 0.23.0.
Changed in version 1.0.0: Changed to not sort by default.
copybool, default True
If False, do not copy data unnecessarily.
Returns
object, type of objs
When concatenating all Series along the index (axis=0), a Series is returned. When objs contains at least one DataFrame, a DataFrame is returned. When concatenating along the columns (axis=1), a DataFrame is returned.
[04. Part 4) Ch 16. 흩어진 데이터 다 모여라 - 데이터 파편화 문제 - 02. 유형 (2) 명시적인 키 변수가 있는 경우]

* 문제 정의 및 해결 방안
- 효율적인 데이터 베이스 관리를 위해, 잘 정제된 데이터일지라도 데이터가 키 변수를 기준으로 나뉘어 저장되는 경우가 매우 흔함
- SQL 에서는 JOIN 을 이용하여 해결하며, python 에서는 merge 를 이용하여 해결한다.

- 일반적인 경우는 해결이 어렵지 않지만, 다양한 케이스가 존재할 수 있으므로 반드시 핵심을 기억해야 한다.
(1) 어느 컬럼이 키 변수 역할을 할 수 있는지 확인하고, 키 변수를 통일해야 한다.
(2) 레코드의 단위를 명확히 해야 한다.
* 관련문법 : pandas.merge
- 키 변수를 기준으루 두개의 데이터 프레임을 병합(join)하는 함수
- 주요입력
. left : 통합 대상 데이터 프레임 1
. right : 통합 대상 데이터 프레임 2
. on : 통합 기준 key 변수 및 변수 리스트 (입력을 하지 않으면, 이름이 같은 변수를 key 로 식별함)
. left_on : 데이터 프레임 1의 key 변수 및 변수 리스트
. right_on : 데이터 프레임 2의 key 변수 및 변수 리스트
. left_index : 데이터 프레임 1의 인덱스를 key 변수로 사용할 지 여부
. right_index : 데이터 프레임 2의 인덱스를 key 변수로 사용할 지 여부
* 실습
- on 을 안써도 되긴 하지만, 가능하면 작성해주는 것이 더 좋다.
// 이 함수도 다시
// pandas.merge Documentation
pandas.pydata.org/pandas-docs/stable/reference/api/pandas.DataFrame.merge.html
DataFrame.merge(right, how='inner', on=None, left_on=None, right_on=None, left_index=False, right_index=False, sort=False, suffixes='_x', '_y', copy=True, indicator=False, validate=None)[source]Merge DataFrame or named Series objects with a database-style join.
The join is done on columns or indexes. If joining columns on columns, the DataFrame indexes will be ignored. Otherwise if joining indexes on indexes or indexes on a column or columns, the index will be passed on.
Parameters
rightDataFrame or named Series
Object to merge with.
how{‘left’, ‘right’, ‘outer’, ‘inner’}, default ‘inner’
Type of merge to be performed.
-
left: use only keys from left frame, similar to a SQL left outer join; preserve key order.
-
right: use only keys from right frame, similar to a SQL right outer join; preserve key order.
-
outer: use union of keys from both frames, similar to a SQL full outer join; sort keys lexicographically.
-
inner: use intersection of keys from both frames, similar to a SQL inner join; preserve the order of the left keys.
onlabel or list
Column or index level names to join on. These must be found in both DataFrames. If on is None and not merging on indexes then this defaults to the intersection of the columns in both DataFrames.
left_onlabel or list, or array-like
Column or index level names to join on in the left DataFrame. Can also be an array or list of arrays of the length of the left DataFrame. These arrays are treated as if they are columns.
right_onlabel or list, or array-like
Column or index level names to join on in the right DataFrame. Can also be an array or list of arrays of the length of the right DataFrame. These arrays are treated as if they are columns.
left_indexbool, default False
Use the index from the left DataFrame as the join key(s). If it is a MultiIndex, the number of keys in the other DataFrame (either the index or a number of columns) must match the number of levels.
right_indexbool, default False
Use the index from the right DataFrame as the join key. Same caveats as left_index.
sortbool, default False
Sort the join keys lexicographically in the result DataFrame. If False, the order of the join keys depends on the join type (how keyword).
suffixeslist-like, default is (“_x”, “_y”)
A length-2 sequence where each element is optionally a string indicating the suffix to add to overlapping column names in left and right respectively. Pass a value of None instead of a string to indicate that the column name from left or right should be left as-is, with no suffix. At least one of the values must not be None.
copybool, default True
If False, avoid copy if possible.
indicatorbool or str, default False
If True, adds a column to the output DataFrame called “_merge” with information on the source of each row. The column can be given a different name by providing a string argument. The column will have a Categorical type with the value of “left_only” for observations whose merge key only appears in the left DataFrame, “right_only” for observations whose merge key only appears in the right DataFrame, and “both” if the observation’s merge key is found in both DataFrames.
validatestr, optional
If specified, checks if merge is of specified type.
-
“one_to_one” or “1:1”: check if merge keys are unique in both left and right datasets.
-
“one_to_many” or “1:m”: check if merge keys are unique in left dataset.
-
“many_to_one” or “m:1”: check if merge keys are unique in right dataset.
-
“many_to_many” or “m:m”: allowed, but does not result in checks.
Returns
DataFrame
A DataFrame of the two merged objects.
[파이썬을 활용한 데이터 전처리 Level UP-Comment]
- 복잡도 파라미터 튜닝에서는 다양한 파라미터에 대해서 어떤식을 튜닝을 해야 되는지.. 단순하다고 나쁜 것도 아니고 복잡하다고 좋은 것도 아니라.. 그 상황에 맞는 경험치!!^^!!
- 데이터 합치 파트는 Chapter 4 에 나와 있는 함수들을 다시 한번 되돌아 볼 수 있는 기회였다.
파이썬을 활용한 데이터 전처리 Level UP 올인원 패키지 Online. | 패스트캠퍼스
데이터 분석에 필요한 기초 전처리부터, 데이터의 품질 및 머신러닝 성능 향상을 위한 고급 스킬까지 완전 정복하는 데이터 전처리 트레이닝 온라인 강의입니다.
www.fastcampus.co.kr
'Programming > Python' 카테고리의 다른 글
| [패스트캠퍼스 수강 후기] 데이터전처리 100% 환급 챌린지 25회차 미션 (0) | 2020.11.26 |
|---|---|
| [패스트캠퍼스 수강 후기] 데이터전처리 100% 환급 챌린지 24회차 미션 (0) | 2020.11.25 |
| [패스트캠퍼스 수강 후기] 데이터전처리 100% 환급 챌린지 22회차 미션 (0) | 2020.11.23 |
| [패스트캠퍼스 수강 후기] 데이터전처리 100% 환급 챌린지 21회차 미션 (2) | 2020.11.22 |
| [패스트캠퍼스 수강 후기] 데이터전처리 100% 환급 챌린지 20회차 미션 (0) | 2020.11.21 |


