[패스트캠퍼스 수강 후기] 데이터전처리 100% 환급 챌린지 25회차 미션 Programming/Python2020. 11. 26. 20:42
[파이썬을 활용한 데이터 전처리 Level UP- 24 회차 미션 시작]
* 복습
- merge, concat, apply, argsort, haversine 작업을 했었음.
[04. Part 4) Ch 16. 흩어진 데이터 다 모여라 - 데이터 파편화 문제 - 05. 유형 (5) 데이터 요약이 포함되는 경우]

* 문제 정의 및 해결 방안
- 보통 1 : N 병합인 경우에 사용되며, 거래 데이터 및 로그 데이터와 병합하는 경우에 주로 사용된다.
- 중복 레코드를 포하하는 데이터를 요약한 후 병합 하는 방식으로 문제를 해결한다.
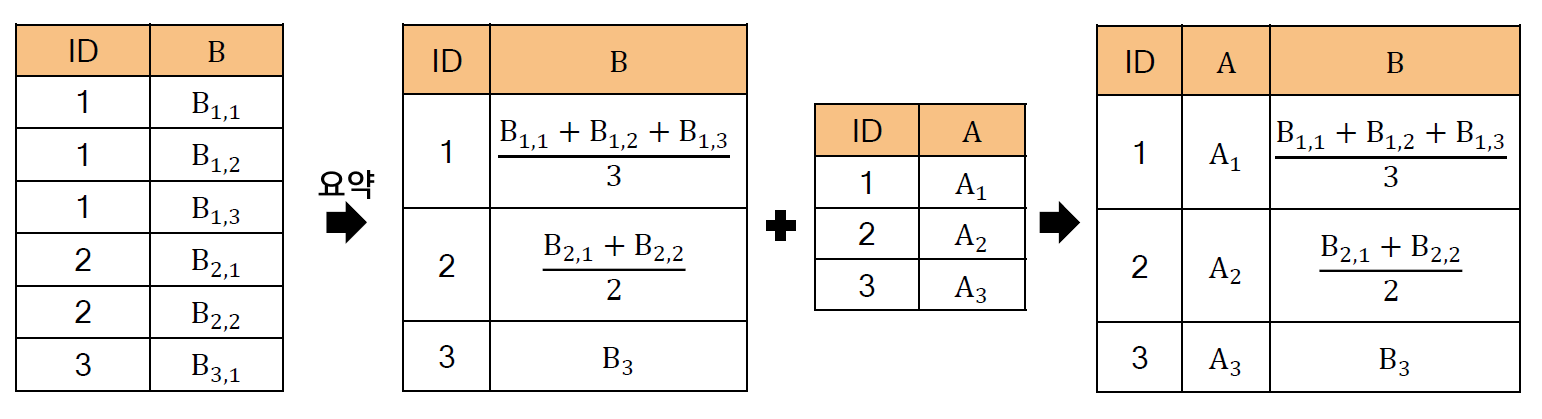
// 보통은 부모 데이터를 기준으로 요약을 하는 것이다.
* 관련문법 : DataFrame.groupby( )
- 조건부 통계량 (조건에 따른 대상의 통계량)을 계산하기 위한 함수로 머신러닝 프로세스 뿐만 아니라, 통계 분석 등에서도 굉장히 자주 활용된다.
- 주요 입력
. by : 조건 변수 (컬럼명 혹은 컬럼명 리스트로 입력)
. as_index : 조건 변수를 index 로 설정할 것인지 여부
- 활용 예시
. df.groupby(['성별'])['신장'].mean( ) # 성별 (조건)에 따른 신장 (대상)의 평균 (통계량)

* 실습

// merge 를 통해서 demo_df 에 rename 한 것을 붙이는 것이다.
// grouby 함수에 대해서는 지난번에도 다뤘던것 같은데, 다시 한번 중요하기에 다시금 Documentation 을 아래와 같이 첨부한다.
// pandas.DataFrame.groupby Documentation
pandas.pydata.org/pandas-docs/stable/reference/api/pandas.DataFrame.groupby.html
DataFrame.groupby(by=None, axis=0, level=None, as_index=True, sort=True, group_keys=True, squeeze=<object object>, observed=False, dropna=True)[source]Group DataFrame using a mapper or by a Series of columns.
A groupby operation involves some combination of splitting the object, applying a function, and combining the results. This can be used to group large amounts of data and compute operations on these groups.
Parameters
bymapping, function, label, or list of labels
Used to determine the groups for the groupby. If by is a function, it’s called on each value of the object’s index. If a dict or Series is passed, the Series or dict VALUES will be used to determine the groups (the Series’ values are first aligned; see .align() method). If an ndarray is passed, the values are used as-is determine the groups. A label or list of labels may be passed to group by the columns in self. Notice that a tuple is interpreted as a (single) key.
axis{0 or ‘index’, 1 or ‘columns’}, default 0
Split along rows (0) or columns (1).
levelint, level name, or sequence of such, default None
If the axis is a MultiIndex (hierarchical), group by a particular level or levels.
as_indexbool, default True
For aggregated output, return object with group labels as the index. Only relevant for DataFrame input. as_index=False is effectively “SQL-style” grouped output.
sortbool, default True
Sort group keys. Get better performance by turning this off. Note this does not influence the order of observations within each group. Groupby preserves the order of rows within each group.
group_keysbool, default True
When calling apply, add group keys to index to identify pieces.
squeezebool, default False
Reduce the dimensionality of the return type if possible, otherwise return a consistent type.
Deprecated since version 1.1.0.
observedbool, default False
This only applies if any of the groupers are Categoricals. If True: only show observed values for categorical groupers. If False: show all values for categorical groupers.
New in version 0.23.0.
dropnabool, default True
If True, and if group keys contain NA values, NA values together with row/column will be dropped. If False, NA values will also be treated as the key in groups
New in version 1.1.0.
Returns
DataFrameGroupBy
Returns a groupby object that contains information about the groups.
[04. Part 4) Ch 17. 왜 여기엔 값이 없을까 결측치 문제 - 01. 문제 정의]

* 문제 정의
- 데이터에 결측치가 있어, 모델 학습 자체가 되지 않는 문제
- 결측치는 크게 NaN 과 None 으로 구분된다.
. NaN : 값이 있어야 하는데 없는 결측으로, 대체, 추정, 예측 등으로 처리
. None : 값이 없는게 값인 결측 (e.g., 직업 - 백수) 으로 새로운 값으로 정의하는 방식으로 처리
- 결측치 처리 방법 자체는 매우 간단하나, 상황에 따른 처리 방법 선택이 매우 중요
* 용어 정의
- 결측 레코드 : 결측치를 포함하는 레코드
- 결측치 비율 : 결측 레코드 수 / 전체 레코드 개수

[04. Part 4) Ch 17. 왜 여기엔 값이 없을까 결측치 문제 - 02. 해결 방법 (1) 삭제]

* 행 단위 결측 삭제
- 행 단위 결측 삭제는 결측 레코드를 삭제하는 매우 간단한 방법이지만, 두 가지 조건을 만족하는 경우에만 수행할 수 있다.

* 열 단위 결측 삭제
- 열 다누이 결측 삭제는 결측 레코드를 포함하는 열을 삭제하는 매우 간단한 방법이지만, 두 가지 조건을 만족하는 경우에만 사용 가능하다.
. 소수 변수에 결측이 많이 포함되어 있다.
. 해당 변수들이 크게 중요하지 않음 (by 도메인 지식)
* 관련 문법 : Series / DataFrame.isnull
- 값이 결측이면 True 를, 그렇지 않으면 False 를 반환 (notnull 함수와 반대로 작동)
- sum 함수와 같이 사용하여 결측치 분포를 확인하는데 주로 사용

* 관련문법 : DataFrame.dropna
- 결측치가 포함된 행이나 열을 제거하는데 사용
- 주요 입력
. axis : 1 이면 결측이 포함된 열을 삭제하며, 0 이면 결측이 포함된 행을 삭제
. how : 'any'면 결측이 하나라도 포함되면 삭제하며, 'all'이면 모든 갑싱 결측인 경우만 삭제 (주로 any 로 설정)
* 실습

// 학습데이터 기준으로 나눠야 한다.
// unique 한 값들을 습관적으로 찍어보는 것이 중요하다.
// pandas.DataFrame.isnull Documentation
pandas.pydata.org/pandas-docs/stable/reference/api/pandas.DataFrame.isnull.html
DataFrame.isnull()Detect missing values.
Return a boolean same-sized object indicating if the values are NA. NA values, such as None or numpy.NaN, gets mapped to True values. Everything else gets mapped to False values. Characters such as empty strings '' or numpy.inf are not considered NA values (unless you set pandas.options.mode.use_inf_as_na = True).
ReturnsDataFrame
Mask of bool values for each element in DataFrame that indicates whether an element is not an NA value.
// pandas.Series.isnull Documentation
pandas.pydata.org/pandas-docs/stable/reference/api/pandas.Series.isnull.html
Series.isnull()Detect missing values.
Return a boolean same-sized object indicating if the values are NA. NA values, such as None or numpy.NaN, gets mapped to True values. Everything else gets mapped to False values. Characters such as empty strings '' or numpy.inf are not considered NA values (unless you set pandas.options.mode.use_inf_as_na = True).
ReturnsSeries
Mask of bool values for each element in Series that indicates whether an element is not an NA value.
// pandas.DataFrame.dropna Documentation
pandas.pydata.org/pandas-docs/stable/reference/api/pandas.DataFrame.dropna.html
DataFrame.dropna(axis=0, how='any', thresh=None, subset=None, inplace=False)[source]Remove missing values.
See the User Guide for more on which values are considered missing, and how to work with missing data.
Parameters
axis{0 or ‘index’, 1 or ‘columns’}, default 0
Determine if rows or columns which contain missing values are removed.
-
0, or ‘index’ : Drop rows which contain missing values.
-
1, or ‘columns’ : Drop columns which contain missing value.
Changed in version 1.0.0: Pass tuple or list to drop on multiple axes. Only a single axis is allowed.
how{‘any’, ‘all’}, default ‘any’
Determine if row or column is removed from DataFrame, when we have at least one NA or all NA.
-
‘any’ : If any NA values are present, drop that row or column.
-
‘all’ : If all values are NA, drop that row or column.
threshint, optional
Require that many non-NA values.
subsetarray-like, optional
Labels along other axis to consider, e.g. if you are dropping rows these would be a list of columns to include.
inplacebool, default False
If True, do operation inplace and return None.
Returns
DataFrame
DataFrame with NA entries dropped from it.
// 참고를 위해서 series에서는 어떤식으로 dropna 가 이뤄지는지 찾아보았다.
// pandas.Series.dropna Documentation
pandas.pydata.org/pandas-docs/stable/reference/api/pandas.Series.dropna.html#pandas.Series.dropna
Series.dropna(axis=0, inplace=False, how=None)[source]Return a new Series with missing values removed.
See the User Guide for more on which values are considered missing, and how to work with missing data.
Parameters
axis{0 or ‘index’}, default 0
There is only one axis to drop values from.
inplacebool, default False
If True, do operation inplace and return None.
howstr, optional
Not in use. Kept for compatibility.
Returns
Series
Series with NA entries dropped from it.
[파이썬을 활용한 데이터 전처리 Level UP-Comment]
- 결측치 제거 및 groupby 등의 함수에 대해서 살펴 볼 수 있었다.
파이썬을 활용한 데이터 전처리 Level UP 올인원 패키지 Online. | 패스트캠퍼스
데이터 분석에 필요한 기초 전처리부터, 데이터의 품질 및 머신러닝 성능 향상을 위한 고급 스킬까지 완전 정복하는 데이터 전처리 트레이닝 온라인 강의입니다.
www.fastcampus.co.kr
'Programming > Python' 카테고리의 다른 글
| [패스트캠퍼스 수강 후기] 데이터전처리 100% 환급 챌린지 27회차 미션 (0) | 2020.11.28 |
|---|---|
| [패스트캠퍼스 수강 후기] 데이터전처리 100% 환급 챌린지 26회차 미션 (0) | 2020.11.27 |
| [패스트캠퍼스 수강 후기] 데이터전처리 100% 환급 챌린지 24회차 미션 (0) | 2020.11.25 |
| [패스트캠퍼스 수강 후기] 데이터전처리 100% 환급 챌린지 23회차 미션 (0) | 2020.11.24 |
| [패스트캠퍼스 수강 후기] 데이터전처리 100% 환급 챌린지 22회차 미션 (0) | 2020.11.23 |


