[패스트캠퍼스 수강 후기] 데이터전처리 100% 환급 챌린지 16회차 미션 Programming/Python2020. 11. 17. 11:30
[파이썬을 활용한 데이터 전처리 Level UP- 16 회차 미션 시작]
* 복습
- 머신러닝에서의 상관관계 분석을 하였고, 군집화를 어떻게 해야 할 것인지에 대해서 개념 및 이론 수업에 대해서 들어보았다.
[02. Part 2) 탐색적 데이터 분석 Chapter 11. 비슷한 애들 모여라 - 군집화 - 02. 계층적 군집화 (실습)]

// set_index 는 컬럼을 인덱스화 시켜주는 것이다.

// fit 앞에것만 사용해서는 군집화가 진행되지 않는다. fit 을 통해서 학습시킨다고 봐야 한다.

// 이런 데이터는 더미화하기에는 좋은 데이터는 아니다.
* (Tip) Pandas.crosstab
- 일반적인 거래 데이터를 교차 테이블 형태로 변환하는데 사용하는 함수

- 참고 : 카이제곱 검정

//이런식의 데이터를 얻게 된다.
// jaccard, average 를 통해서 작업을 진행
// fit 을 해줘야 한다. 물론.
[02. Part 2) 탐색적 데이터 분석 Chapter 11. 비슷한 애들 모여라 - 군집화 - 03. k-평균 군집화]

// 가장 대표적인 군집화라고 보면 된다.
* 기본 개념
- (1) k개의 중심점 설정, (2) 샘플 할당, (3) 중심점 업데이트를 반복하는 방식으로 k개의 군집을 생성하는 알고리즘
// k 는 군집의 갯수


* k - 평균 군집화의 장단점
- 장점 (1) 상대적으로 적은 계산량 O(n)
- 장점 (2) 군집 개수 설정에 제약이 없고 쉽다.
// 가장 널리 쓰이는 군집화라고 보면 된다.
- 단점 (1) 초기 중심 설정에 따른 수행할 때마다 다른 결과를 낼 가능성 존재 (임의성 존재 O)
// 초기점의 설정에 따라서 결과가 다를 수 있다는 임의성이 존재한다.
- 단점 (2) 데이터 분포가 특이하거나 군집별 밀도 차이가 존재하면 좋은 성능을 내기 어렵다.
- 단점 (3) 유클리디안 거리만 사용해야 한다.
- 단점 (4) 수렴하지 않을 가능성 존재
* sklearn.cluster.KMeans
- 주요입력
. n_cluster : 군집 개수
. max_iter : 최대 이터레이션 함수
- 주요 메서드
. fit(x) : 데이터 x에 대한 군집화 모델 학습
. fit_predict(x) : 데이터 x에 대한 군집화 모델 학습 및 라벨 반환
- 주요 속성
. labels_ : fitting 한 데이터에 있는 샘플들이 속한 군집 정보 (ndarray)
. cluster_center_: fitting 한 데이터에 있는 샘플들이 속한 군집 중심점 (ndarray)
// sklearn.cluster.KMeans Documentation
scikit-learn.org/stable/modules/generated/sklearn.cluster.KMeans.html
class sklearn.cluster.KMeans(n_clusters=8, *, init='k-means++', n_init=10, max_iter=300, tol=0.0001, precompute_distances='deprecated', verbose=0, random_state=None, copy_x=True, n_jobs='deprecated', algorithm='auto')K-Means clustering.
Read more in the User Guide.
Parameters
n_clustersint, default=8
The number of clusters to form as well as the number of centroids to generate.
init{‘k-means++’, ‘random’, ndarray, callable}, default=’k-means++’
Method for initialization:
‘k-means++’ : selects initial cluster centers for k-mean clustering in a smart way to speed up convergence. See section Notes in k_init for more details.
‘random’: choose n_clusters observations (rows) at random from data for the initial centroids.
If an ndarray is passed, it should be of shape (n_clusters, n_features) and gives the initial centers.
If a callable is passed, it should take arguments X, n_clusters and a random state and return an initialization.
n_initint, default=10
Number of time the k-means algorithm will be run with different centroid seeds. The final results will be the best output of n_init consecutive runs in terms of inertia.
max_iterint, default=300
Maximum number of iterations of the k-means algorithm for a single run.
tolfloat, default=1e-4
Relative tolerance with regards to Frobenius norm of the difference in the cluster centers of two consecutive iterations to declare convergence.
precompute_distances{‘auto’, True, False}, default=’auto’
Precompute distances (faster but takes more memory).
‘auto’ : do not precompute distances if n_samples * n_clusters > 12 million. This corresponds to about 100MB overhead per job using double precision.
True : always precompute distances.
False : never precompute distances.
Deprecated since version 0.23: ‘precompute_distances’ was deprecated in version 0.22 and will be removed in 0.25. It has no effect.
verboseint, default=0
Verbosity mode.
random_stateint, RandomState instance, default=None
Determines random number generation for centroid initialization. Use an int to make the randomness deterministic. See Glossary.
copy_xbool, default=True
When pre-computing distances it is more numerically accurate to center the data first. If copy_x is True (default), then the original data is not modified. If False, the original data is modified, and put back before the function returns, but small numerical differences may be introduced by subtracting and then adding the data mean. Note that if the original data is not C-contiguous, a copy will be made even if copy_x is False. If the original data is sparse, but not in CSR format, a copy will be made even if copy_x is False.
n_jobsint, default=None
The number of OpenMP threads to use for the computation. Parallelism is sample-wise on the main cython loop which assigns each sample to its closest center.
None or -1 means using all processors.
Deprecated since version 0.23: n_jobs was deprecated in version 0.23 and will be removed in 0.25.
algorithm{“auto”, “full”, “elkan”}, default=”auto”
K-means algorithm to use. The classical EM-style algorithm is “full”. The “elkan” variation is more efficient on data with well-defined clusters, by using the triangle inequality. However it’s more memory intensive due to the allocation of an extra array of shape (n_samples, n_clusters).
For now “auto” (kept for backward compatibiliy) chooses “elkan” but it might change in the future for a better heuristic.
Changed in version 0.18: Added Elkan algorithm
Attributes
cluster_centers_ndarray of shape (n_clusters, n_features)
Coordinates of cluster centers. If the algorithm stops before fully converging (see tol and max_iter), these will not be consistent with labels_.
labels_ndarray of shape (n_samples,)
Labels of each point
inertia_float
Sum of squared distances of samples to their closest cluster center.
n_iter_int
Number of iterations run.
* 실습
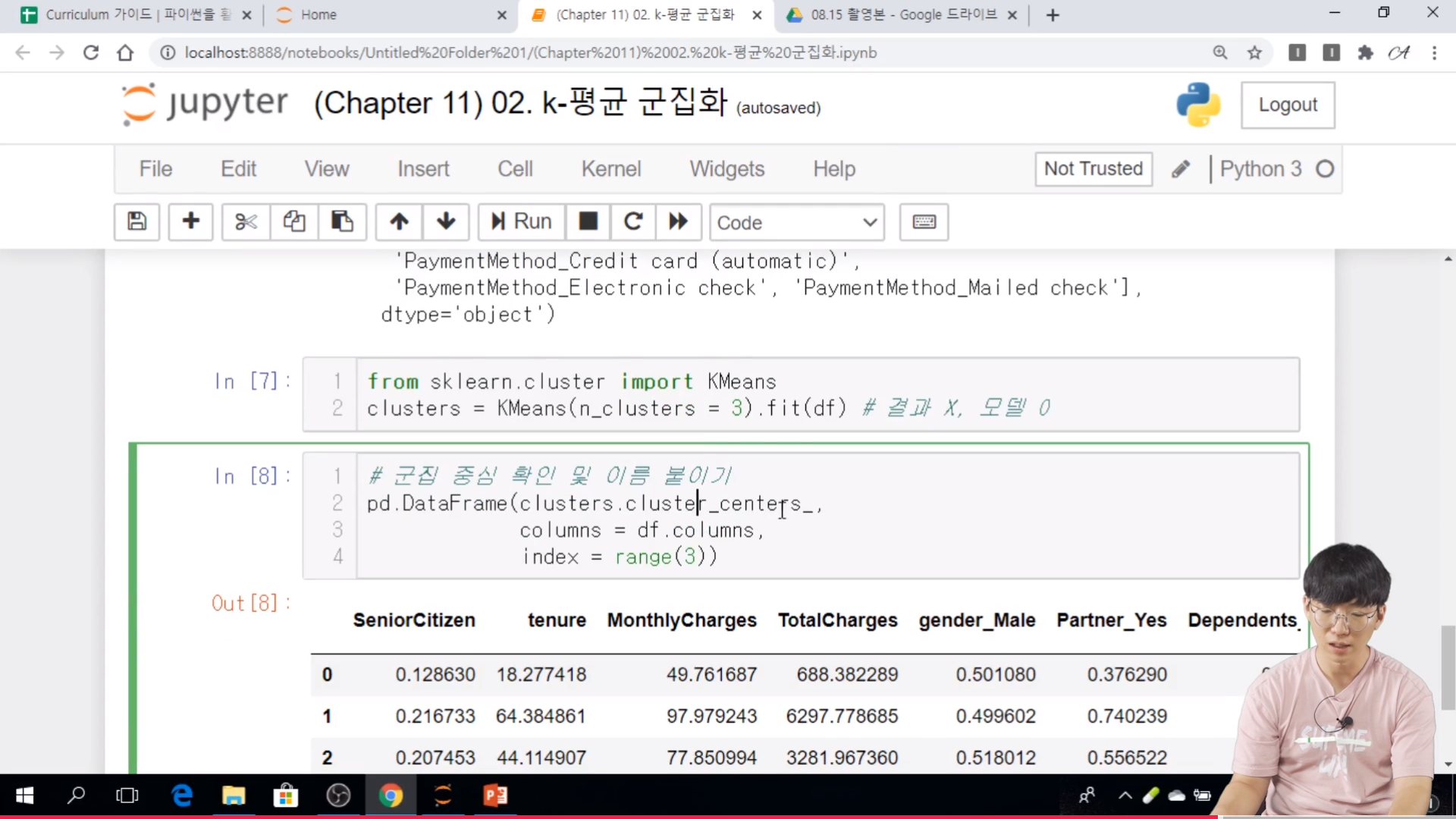
// 결과가 아니라, 모델이라고 생각하면 된다.
[02. Part 2) 어디서 많이 봤던 패턴이다 싶을 때 - 빈발 패턴 탐색 - 01-1. 연관 규칙 탐색(이론)]

* 연관규칙이란?
- "A가 발생하면 B도 발생하더라"라는 형태의 규칙으로, 트랜잭션 데이터를 탐색하는데 사용
. A : 부모 아이템 집합 (antecedent)
. B : 자식 아이템 집합 (consequent)
. A 와 B 는 모두 공집합이 아닌 집합이며, A n B = 공집합 을 만족함 (즉, 공통되는 요소가 없다.)
- 규칙 예시

* 연관규칙 탐색이란?
- 트랜잭션 데이터에서 의미있는 연관규칙을 효율적으로 탐색하는 작업

// 연관규칙으로 만들 수 있는 경우의 수가 굉장히 많은데 그걸 효율적으로 탐색하는 작업이 필요하다.
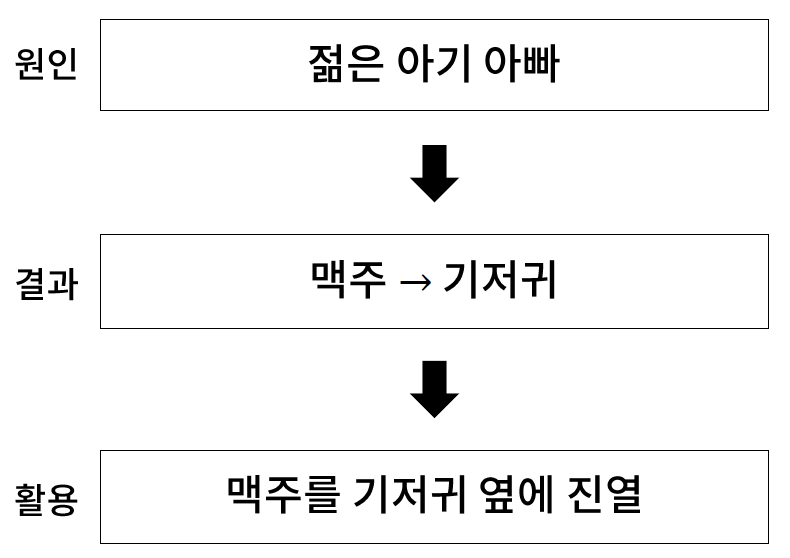
* 연관규칙 탐색의 활용 사례 : 월마트
- 월마트에서는 엄청나게 많은 영수증 데이터에 대해 연관규칙 탐색을 적용하여, 매출을 향상시킨다.
* 연관규칙의 평가 척도
- 지지도 (supprot) : 아이템 집합이 전체 트랜잭션 데이터에서 발생한 비율

- 신뢰도 (confidence) : 부모 아이템 집합이 등장한 트랜잭션 데이터에서 자식 아이템 집합이 발생한 비율

- 지지도와 신뢰도가 높은 연관규칙을 좋은 규칙이라고 판단
* 연관규칙의 평가 척도 계산 예시

// 5 는 거래 ID 의 모든 수를 이야기 하고, 4 는 빵을 샀을 경우
* 아이템집합 격자
- 아이템 집합과 그 관계를 한 눈에 보여주기 위한 그래프

* 지지도에 대한 Apriori 원리 : 개요
- S (A -> B) 가 최소 지지도 (min supprot) 이상이면, 이 규칙을 빈발하다고 한다.
- 아이템 집합의 지지도가 최소 지지도 이상이면, 이 집합을 빈발하다고 한다.
- 지지도에 대한 Apriori 원리 : 어떤 아이템 집합이 빈발하면, 이 아이템의 부분 집합도 빈발한다.

* 지지도에 대한 Apriori 원리 : 작용

* 지지도에 대한 Apriori 원리 : 후보 규칙 생성
- Apriori 원리를 사용하여 모든 최대 빈발 아이템 집합을 찾은 후, 후보 규칙을 모두 생성한다.
. 최대 빈발 아이템 집합 : 최소 지지도 이상이면서, 이 집합의 모든 모집합이 빈발하지 않는 집합
// 모든 집합이라는 것은 부분 집합의 반대라고 생각하면 좋을 것 같다.
. (예시) {A, B, C} 가 빈발한데, {A, B, C, D}, {A, B, C, E}등이빈발하지않으면, {A, B, C}를최대빈발아이템집합이라고한다.
- 만약, {A, B, C} 가 최대 빈발아이템 집합이면, 생성 가능한 후보 규칙은 다음과 같다.

* 신뢰도에 대한 Apriori 원리
- 동일한 아이템 집합으로 생성한 규칙 X1 -> Y1, X2 -> Y2 에 대해서, 다음이 성립한다.
// 동일한 아이템 집합이라는 것이 중요하다.

* 신뢰도에 대한 Apriori 원리 : 적용

* 관련 모듈 : mlxtend
- apriori 함수를 이용한 빈발 아이템 집합 탐색과 association_rules 함수를 이용하여 연관규칙을 탐색하는 두 단계로 수행
- mlxtend.frequent_patterns.apriori(df, min_support):
. df : one hot encoding 형태의 데이터 프레임
. min_support : 최소 지지도
- mlxtend.frequent_patterns.association_rules(frequent_dataset, metric, min_threshod):
. frequent_dataset 에서 찾은 연관 규칙을 데이터 프레임 형태로 반환
. metric : 연관 규칙을 필터링하기 위한 유용성 척도 (default : confidence_
. min_threshold : 지정한 metric 의 최소 기준치
* mlxtend.preprocessin.gTransactionEncoder
- 연관 규칙 탐사에 적절하게 거래 데이터 구조를 바꾸기 위한 함수
- 인스턴스 생성 후, fit(data).transform(data) 를 이용하여 data를 각 아이템의 출현 여부를 갖는 ndarray 및 DataFrame으로 변환

// 범주형 변수들을 처리 할때 OHE 을 사용한다.
// mlxtend.frequent_patterns.apriori 관련 사이트
rasbt.github.io/mlxtend/user_guide/frequent_patterns/apriori/
apriori(df, min_support=0.5, use_colnames=False, max_len=None, verbose=0, low_memory=False)Get frequent itemsets from a one-hot DataFrame
Parameters
-
df : pandas DataFrame
pandas DataFrame the encoded format. Also supports DataFrames with sparse data; for more info, please see (https://pandas.pydata.org/pandas-docs/stable/ user_guide/sparse.html#sparse-data-structures)
Please note that the old pandas SparseDataFrame format is no longer supported in mlxtend >= 0.17.2.
The allowed values are either 0/1 or True/False. For example,
Apple Bananas Beer Chicken Milk Rice 0 True False True True False True 1 True False True False False True 2 True False True False False False 3 True True False False False False 4 False False True True True True 5 False False True False True True 6 False False True False True False 7 True True False False False False
-
min_support : float (default: 0.5)
A float between 0 and 1 for minumum support of the itemsets returned. The support is computed as the fraction transactions_where_item(s)_occur / total_transactions.
-
use_colnames : bool (default: False)
If True, uses the DataFrames' column names in the returned DataFrame instead of column indices.
-
max_len : int (default: None)
Maximum length of the itemsets generated. If None (default) all possible itemsets lengths (under the apriori condition) are evaluated.
-
verbose : int (default: 0)
Shows the number of iterations if >= 1 and low_memory is True. If
=1 and low_memory is False, shows the number of combinations.
-
low_memory : bool (default: False)
If True, uses an iterator to search for combinations above min_support. Note that while low_memory=True should only be used for large dataset if memory resources are limited, because this implementation is approx. 3-6x slower than the default.
Returns
pandas DataFrame with columns ['support', 'itemsets'] of all itemsets that are >= min_support and < than max_len (if max_len is not None). Each itemset in the 'itemsets' column is of type frozenset, which is a Python built-in type that behaves similarly to sets except that it is immutable (For more info, see https://docs.python.org/3.6/library/stdtypes.html#frozenset).
Examples
For usage examples, please see http://rasbt.github.io/mlxtend/user_guide/frequent_patterns/apriori/
// mlxtend.frequent_patterns.association_rules 관련 사이트
rasbt.github.io/mlxtend/user_guide/frequent_patterns/association_rules/
association_rules(df, metric='confidence', min_threshold=0.8, support_only=False)Generates a DataFrame of association rules including the metrics 'score', 'confidence', and 'lift'
Parameters
-
df : pandas DataFrame
pandas DataFrame of frequent itemsets with columns ['support', 'itemsets']
-
metric : string (default: 'confidence')
Metric to evaluate if a rule is of interest. Automatically set to 'support' if support_only=True. Otherwise, supported metrics are 'support', 'confidence', 'lift',
'leverage', and 'conviction' These metrics are computed as follows:
- support(A->C) = support(A+C) [aka 'support'], range: [0, 1] - confidence(A->C) = support(A+C) / support(A), range: [0, 1] - lift(A->C) = confidence(A->C) / support(C), range: [0, inf] - leverage(A->C) = support(A->C) - support(A)*support(C), range: [-1, 1] - conviction = [1 - support(C)] / [1 - confidence(A->C)], range: [0, inf]
-
min_threshold : float (default: 0.8)
Minimal threshold for the evaluation metric, via the metric parameter, to decide whether a candidate rule is of interest.
-
support_only : bool (default: False)
Only computes the rule support and fills the other metric columns with NaNs. This is useful if:
a) the input DataFrame is incomplete, e.g., does not contain support values for all rule antecedents and consequents
b) you simply want to speed up the computation because you don't need the other metrics.
Returns
pandas DataFrame with columns "antecedents" and "consequents" that store itemsets, plus the scoring metric columns: "antecedent support", "consequent support", "support", "confidence", "lift", "leverage", "conviction" of all rules for which metric(rule) >= min_threshold. Each entry in the "antecedents" and "consequents" columns are of type frozenset, which is a Python built-in type that behaves similarly to sets except that it is immutable (For more info, see https://docs.python.org/3.6/library/stdtypes.html#frozenset).
Examples
For usage examples, please see http://rasbt.github.io/mlxtend/user_guide/frequent_patterns/association_rules/
// mlxtend.preprocessin.gTransactionEncoder 관련 사이트
rasbt.github.io/mlxtend/user_guide/preprocessing/TransactionEncoder/
TransactionEncoder()Encoder class for transaction data in Python lists
Parameters
None
Attributes
columns_: list List of unique names in the X input list of lists
Examples
For usage examples, please see http://rasbt.github.io/mlxtend/user_guide/preprocessing/TransactionEncoder/
Methods
fit(X)
Learn unique column names from transaction DataFrame
Parameters
-
X : list of lists
A python list of lists, where the outer list stores the n transactions and the inner list stores the items in each transaction.
For example, [['Apple', 'Beer', 'Rice', 'Chicken'], ['Apple', 'Beer', 'Rice'], ['Apple', 'Beer'], ['Apple', 'Bananas'], ['Milk', 'Beer', 'Rice', 'Chicken'], ['Milk', 'Beer', 'Rice'], ['Milk', 'Beer'], ['Apple', 'Bananas']]
fit_transform(X, sparse=False)
Fit a TransactionEncoder encoder and transform a dataset.
get_params(deep=True)
Get parameters for this estimator.
Parameters
-
deep : boolean, optional
If True, will return the parameters for this estimator and contained subobjects that are estimators.
Returns
-
params : mapping of string to any
Parameter names mapped to their values.
inverse_transform(array)
Transforms an encoded NumPy array back into transactions.
Parameters
-
array : NumPy array [n_transactions, n_unique_items]
The NumPy one-hot encoded boolean array of the input transactions, where the columns represent the unique items found in the input array in alphabetic order
For example,
array([[True , False, True , True , False, True ], [True , False, True , False, False, True ], [True , False, True , False, False, False], [True , True , False, False, False, False], [False, False, True , True , True , True ], [False, False, True , False, True , True ], [False, False, True , False, True , False], [True , True , False, False, False, False]])
The corresponding column labels are available as self.columns_, e.g., ['Apple', 'Bananas', 'Beer', 'Chicken', 'Milk', 'Rice']
Returns
-
X : list of lists
A python list of lists, where the outer list stores the n transactions and the inner list stores the items in each transaction.
For example,
[['Apple', 'Beer', 'Rice', 'Chicken'], ['Apple', 'Beer', 'Rice'], ['Apple', 'Beer'], ['Apple', 'Bananas'], ['Milk', 'Beer', 'Rice', 'Chicken'], ['Milk', 'Beer', 'Rice'], ['Milk', 'Beer'], ['Apple', 'Bananas']]
set_params(params)
Set the parameters of this estimator.
The method works on simple estimators as well as on nested objects (such as pipelines). The latter have parameters of the form <component>__<parameter> so that it's possible to update each component of a nested object.
Returns
self
transform(X, sparse=False)
Transform transactions into a one-hot encoded NumPy array.
Parameters
-
X : list of lists
A python list of lists, where the outer list stores the n transactions and the inner list stores the items in each transaction.
For example, [['Apple', 'Beer', 'Rice', 'Chicken'], ['Apple', 'Beer', 'Rice'], ['Apple', 'Beer'], ['Apple', 'Bananas'], ['Milk', 'Beer', 'Rice', 'Chicken'], ['Milk', 'Beer', 'Rice'], ['Milk', 'Beer'], ['Apple', 'Bananas']]
sparse: bool (default=False) If True, transform will return Compressed Sparse Row matrix instead of the regular one.
Returns
-
array : NumPy array [n_transactions, n_unique_items]
if sparse=False (default). Compressed Sparse Row matrix otherwise The one-hot encoded boolean array of the input transactions, where the columns represent the unique items found in the input array in alphabetic order. Exact representation depends on the sparse argument
For example, array([[True , False, True , True , False, True ], [True , False, True , False, False, True ], [True , False, True , False, False, False], [True , True , False, False, False, False], [False, False, True , True , True , True ], [False, False, True , False, True , True ], [False, False, True , False, True , False], [True , True , False, False, False, False]]) The corresponding column labels are available as self.columns_, e.g., ['Apple', 'Bananas', 'Beer', 'Chicken', 'Milk', 'Rice']
ython
[파이썬을 활용한 데이터 전처리 Level UP-Comment]
- 군집화라는 개념도 어떠한 범주형 형태의 데이터 가공을 통해서 관련된 어떤 변수를 추천한다거나 분석하는 개념
파이썬을 활용한 데이터 전처리 Level UP 올인원 패키지 Online. | 패스트캠퍼스
데이터 분석에 필요한 기초 전처리부터, 데이터의 품질 및 머신러닝 성능 향상을 위한 고급 스킬까지 완전 정복하는 데이터 전처리 트레이닝 온라인 강의입니다.
www.fastcampus.co.kr
'Programming > Python' 카테고리의 다른 글
| [패스트캠퍼스 수강 후기] 데이터전처리 100% 환급 챌린지 18회차 미션 (0) | 2020.11.19 |
|---|---|
| [패스트캠퍼스 수강 후기] 데이터전처리 100% 환급 챌린지 17회차 미션 (0) | 2020.11.18 |
| [패스트캠퍼스 수강 후기] 데이터전처리 100% 환급 챌린지 15회차 미션 (0) | 2020.11.16 |
| [패스트캠퍼스 수강 후기] 데이터전처리 100% 환급 챌린지 14회차 미션 (0) | 2020.11.15 |
| [패스트캠퍼스 수강 후기] 데이터전처리 100% 환급 챌린지 13회차 미션 (0) | 2020.11.14 |


