Python provides a.get()method to access adictionaryvalue if it exists. This method takes thekeyas the first argument and an optional default value as the second argument, and it returns the value for the specifiedkeyifkeyis in the dictionary. If the second argument is not specified andkeyis not found thenNoneis returned.
# without default
{"name": "Victor"}.get("name")
# returns "Victor"
{"name": "Victor"}.get("nickname")
# returns None
# with default
{"name": "Victor"}.get("nickname", "nickname is not a key")
# returns "nickname is not a key"
// get 메소드를 가끔은 사용할수도 있을 것 같다. 굳이 조건문을 통하지 않더라도 어떠한 dictionary 에 적당한 값이 있는지 없는지를 알기에도 적당할 듯한다.
// 전에 배운 list 형태에서 사용한 pop method 도 사용할 수 있다.
Python dictionaries can remove key-value pairs with the.pop()method. The method takes a key as an argument and removes it from the dictionary. At the same time, it also returns the value that it removes from the dictionary.
r-length tuples, in sorted order, with repeated elements
ExamplesResults
product('ABCD',repeat=2)
AAABACADBABBBCBDCACBCCCDDADBDCDD
permutations('ABCD',2)
ABACADBABCBDCACBCDDADBDC
combinations('ABCD',2)
ABACADBCBDCD
combinations_with_replacement('ABCD', 2)
AAABACADBBBCBDCCCDDD
- itertools.combinations(p, r)
. 이터레이터 객체 p에서 크기 r의 가능한 모든 조합을 갖는 이터레이터를 생성
Returnrlength subsequences of elements from the inputiterable.
The combination tuples are emitted in lexicographic ordering according to the order of the inputiterable. So, if the inputiterableis sorted, the combination tuples will be produced in sorted order.
Elements are treated as unique based on their position, not on their value. So if the input elements are unique, there will be no repeat values in each combination.
Roughly equivalent to:
def combinations(iterable, r):
# combinations('ABCD', 2) --> AB AC AD BC BD CD
# combinations(range(4), 3) --> 012 013 023 123
pool = tuple(iterable)
n = len(pool)
if r > n:
return
indices = list(range(r))
yield tuple(pool[i] for i in indices)
while True:
for i in reversed(range(r)):
if indices[i] != i + n - r:
break
else:
return
indices[i] += 1
for j in range(i+1, r):
indices[j] = indices[j-1] + 1
yield tuple(pool[i] for i in indices)
// 각 요소들을 조합해서 경우의 수에 대해서 모두 보여 주는 것이다. 이것 또한 잘 만 이용하면 좋을 것 같은데...
The code forcombinations()can be also expressed as a subsequence ofpermutations()after filtering entries where the elements are not in sorted order (according to their position in the input pool):
def combinations(iterable, r):
pool = tuple(iterable)
n = len(pool)
for indices in permutations(range(n), r):
if sorted(indices) == list(indices):
yield tuple(pool[i] for i in indices)
The number of items returned isn!/r!/(n-r)!when0<=r<=nor zero whenr>n.
- itertools.permutations(p, r)
. 이터레이터 객체 p에서 크기 r의 가능한 모든 순열을 갖는 이터레이터를 생성
The code forpermutations()can be also expressed as a subsequence ofproduct(), filtered to exclude entries with repeated elements (those from the same position in the input pool):
def permutations(iterable, r=None):
pool = tuple(iterable)
n = len(pool)
r = n if r is None else r
for indices in product(range(n), repeat=r):
if len(set(indices)) == r:
yield tuple(pool[i] for i in indices)
// permutations function 안에서도 for 문과, if 문을 이용해서 tuple 형태로 반환해주고 있다.
* list comprehension
- list comprehension은 for문을 사용하여 한 줄로 리스트를 효과적으로 생성하는 방법임
- 예시
- 조건문은 생략 가능함.
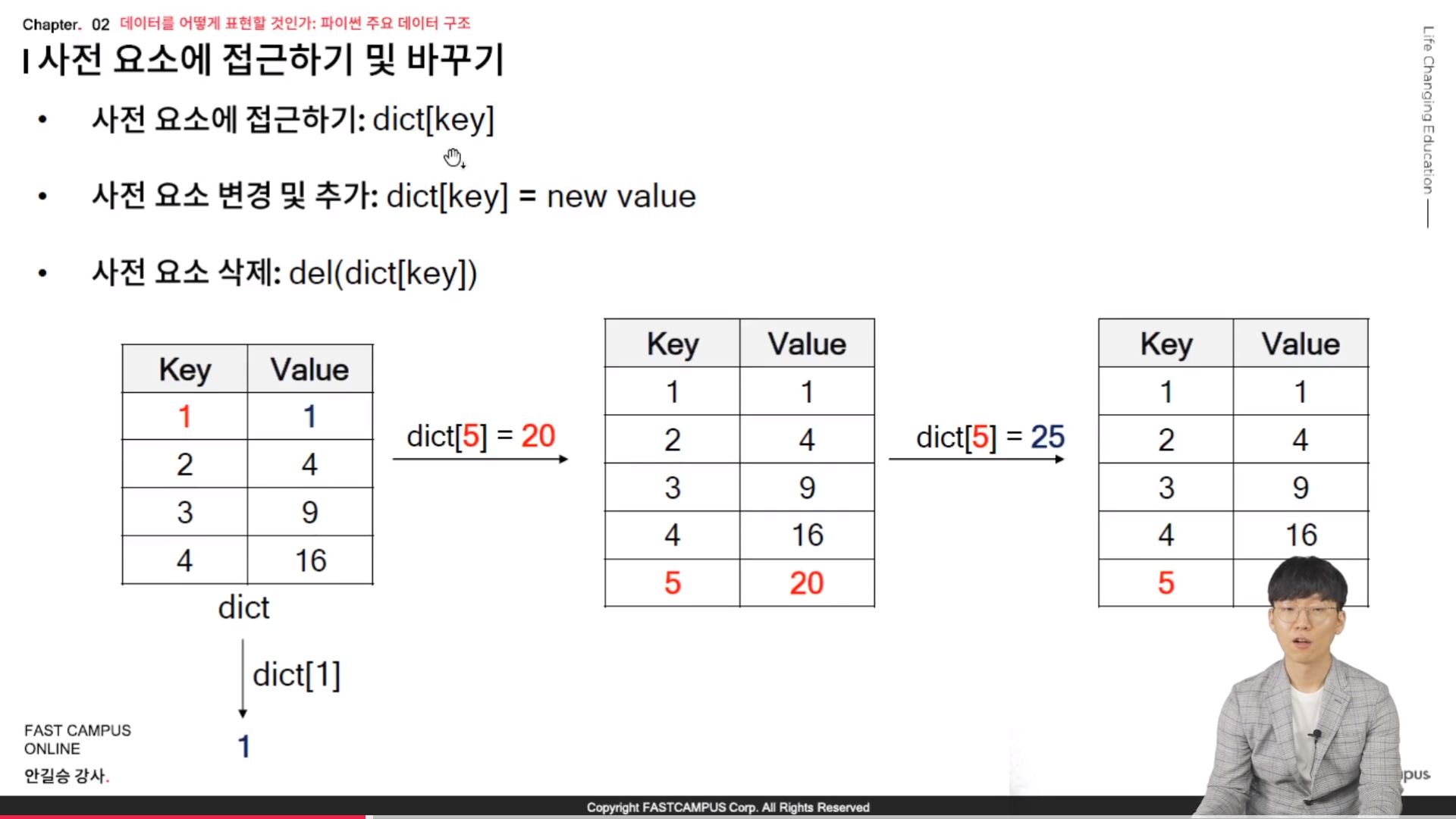
* dictionary comprehension
- dictionary comprehension은 for문을 사용하여 한 줄로 사전을 효과적으로 생성하는 방법임
Chapter 02. 데이터를 어떻게 표현할 것인가 - 파이썬 주요 데이터 구조 - 02. Numpy의 데이터 구조
* 개요
- Numpy의 자료형은 ndarray로 효율적인 배열 연산을 하기 위해 개발되었음
- 리스트와 ndarray는 유연성과 효율성을 기준으로 비교할 수 있음
- list는 float, str 등 모든 요소를 저장할 수 있음
- ndarray 는 float, str 등을 정의해줘야 한다.
- ndarray 는 C로 구현된 내부 반복문을 사용하여 속도가 매우 빠른 편이다.
* 배열 만들기: np.array 함수
- np.array 함수를 사용하여 ndarray를 생성할 수 있음
// 사용하기 전에는 numpy 를 import 해줘야 한다.
import numpy as np
- np 로 as하는 것은 가장 많이 쓰는 약속 같은 것이다.
// numpy 에 대해서 cheat sheet 를 보는 것이 좋을 것 같아서 검색해보면 죄다. 어디로 연결되거나 길다....
- 2차원 배열인 경ㅇ, X[i, j]는 i행 j열에 있는 요소를 나타냄. (c.f. X가 리스트라면, X[i][j]로 접근함.)
- 부울 리스트도 인덱스로 사용할 수 있으며, True인 요소와 대응되는 요소만 가져옴
- 여러 개의 인덱스를 리스트 형태로 입력 받을 수도 있음
* 유니버셜 함수
- 유니버셜 함수는 ndarray의 개별 요소에 반복된 연산을 빠르게 수행하는 것을 주 목적으로 하는 함수
- ndarray x와 y에 대해, 덧셈, 뺄셈, 곱셈, 제곱 등 다양한 배열 간 이항 연산을 지원함.
- 유니버셜 함수는 단순 반복문에 비해, 매우 빠름
* 브로드캐스팅
- 다른 크기의 배열에 유니버셜 함수를 적용하는 규칙 집합으로, 큰 차원의 배열에 맞게 작은 배열이 확장됨.
- 첫번째 케이스와 두번째 케이스가 가장 많이 쓰인다.
- 첫번째 케이스에서 복제를 해서 각각 더한다.
- 브로드캐스팅 예시: z-normalization
* 비교 연산자
- 비교 연산자의 결과는 항상 부울 타입의 배열임
- 따라서 비교 연산자의 결과를 바탕으로 조건에 맞는 요소 탐색에 활용할 수 있음
sum(cond) - True는 1이고, False 0이기 때문에 더해도 개수가 나오게 된다.
[파이썬을 활용한 데이터 전처리 Level UP-Comment] 오늘 강의에서는 새로운 itertools 라는 구문에 대해서 배울 수 있었다. combination 기능을 잘만 이용하면 좀 더 빠른 연산을 할 수 있을 것 같기도 한데.. 불필요한 for 문이나 if 문 등 반복문과 조건문을 줄이기 위해서는 comprehension 문을 잘 사용하여야 하지만, 아직까지 그렇게 손에 있지 않는다. for 문 내에서도 다양한 조건 등을 걸어서 coding을 하다 보니 코딩만 더러워지고 있다. 거기에 time loose만 들어나고..
패치#노트코딩, 주식, 자동매매, 백테스팅, 데이터분석 등 관심 블로그
비전공자이지만 금융 및 관련 프로그래밍에 관심을 두고 열심히 공부중입니다.
우리 모두 경제적 자유를 위해 성공해봅시다!!
※ 혹시, 블로그 내용중 문제되는 내용있으시면 알려주시면 삭제/수정 토록하겠습니다.
※ 모든 내용들은 투자 권유가 아니오니 참고만 하시고, 또한 출처는 모두 표기토록 노력하겠으나 혹시 문제가 되는 글이 있다면 댓글로 남겨주세요~^^