[패스트캠퍼스 수강 후기] 데이터전처리 100% 환급 챌린지 1 회차 미션 Programming/Python2020. 11. 2. 10:28
오늘부터 패캠에서 수강과목에 대한 환급챌린지를 시작하게되었네요.
어차피 데이터분석에 대해서 공부를 하고 있는 요즘이라..
이런 기회를 통해서 미션을 완료하게 되면 강의도 공짜로 듣고.
그 걸 통해서 공부도 더 열심히하게 되니깐 일거양득....
아자아자!! 화이팅!!!!
Part1. 데이터핸들링
[Chapter 01. 시작에 앞서 데이터 전처리는 왜 중요할까 - 01. 데이터 전처리의 중요성 및 개요]

- 현실데이터는 분석 목적에 맞게 정리되어 있지않아, 데이터 분석 기법을 그대로 적용하기 어려움
* 현실 데이터 사례
- P 밸브사 - 수요 예측의 주문서 데이터가 파일명, 폴더 등이 정리되어 있지 않음.
- 포맷이 다른 주문서: 통일되지 않은 셀 위치와 제목 셀 이름이 정확하지 않음.
- 이런 경우에는 효과적으로 정리하는 방법이 필요함
- M공업사 - 설비 비가동 시점 예측
- 시간으로 정리되어 있으나 시간순서가 비정상적인 시간순서로 정리되어 있음- 기록되지 않은 알람이 포함되어 있음- 결측치 등이 다수 존재- 특수한 형태의 16진수로 구성된 리스트가 있음
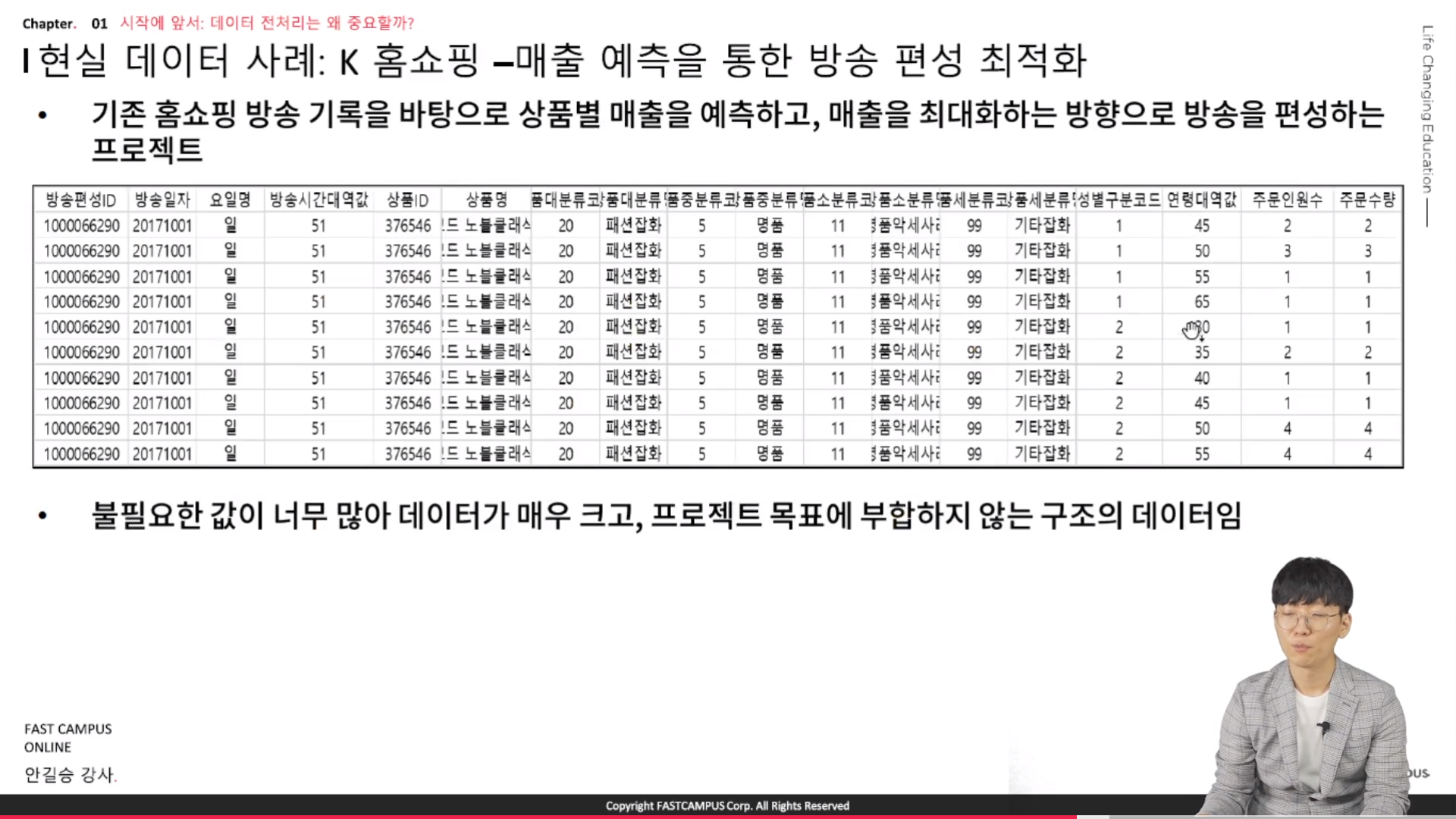
- K홈쇼핑 - 매출 예측을 통한 방송 편성 최적화- 기존 홈쇼핑 방송 기록을 바탕으로 상품별 매출을 예측하고, 매출을 최대화하는 방향으로 방송을 편성하는 프로젝트- 불필요한 값이 너무 많아 데이터가 매우크고, 프로젝트 목표에 부합하지 않는 구조의 데이터임- 이와 같은 경우에는 잘 정리된것 처럼 보이지만 초심자의 경우에는 더 어려움을 느낄 수 있음

- 데이터 분석에 소요되는 시간- 모든 데이터 분석 프로젝트에서 데이터 전처리는 필수적인 과정이며, 많은 분석가들이 데이터 전처리에 가장 많은 시간을 투입함
. Cleaning and organizing data: 60%
. Collecting data sets: 19%
=> 이러한 결과를 바탕으로 전체 분석 시간의 79%를 사용한다고 한다. 전처리 역량이 분석 시간을 줄이는데 가장 중요하다는 의미이다.
// 하기사 코드를 짤때도 디버그야말로...진정한..시간잡아먹기.ㅠ.ㅠ
- 데이터 전처리의 주요 효과- 효율적인 분석을 가능하게 해준다.- 불필요한 정보를 제거함으로써 인사이트를 얻는데 도움이 된다.- 머신러닝 모델의 성능을 향상시킨다.
[Chapter 01. 시작에 앞서 데이터 전처리는 왜 중요할까 - 02. 데이터 전처리를 잘하는 방법]

* 경험을 쌓아라
- 데이터 전처리 역량을 쌓는 가장 확실한 방법은 좋은 경험을 많이 쌓는 것이다.
- 대다수의 경험은 "이런 방법을 쓰니까 시간만 날리더라. 다른 방법이 제일 좋았다"라는 레퍼런스가 됨
- 크롤링한 뉴스에서 단어 추철 및 변환하기 사례.. 데이터 추출하는 과제였는데.. 각각의 중요단어를 추출했어야 하지만.. 간단하게 띄워쓰기 등을 기준으로 했었다.
=> 형태소 분석 등등을 이용했어야 했다.
=> 실수를 통해서 지속적인 경험을 쌓아야지만 효과적인 방법으로 전처리를 할 수가 있다.
* 결과를 생각하라.
- 전처리의 결과인 전처리된 데이터의 구조를 미리 생각해야 불필요한 피드백 루프를 막을 수 있음
- 피드백 루프.. 처리된 데이터가 다시 돌아간다는 의미
* 처리 과정을 생각하라.
- 원 데이터를 결과 데이터로 바꾸기 위한 과정을 단계별로 정의해야 함
- 결과에 대해서 계획을 세워야 한다.
* 검색능력을 쌓아라.
- 데이터 전처리에 대한 기초적인 역량을 십분 발휘하기 위해서는, 필요한 전처리를 수행하는 방법을 검색하는 역량을 쌓아야 한다... 구글링을 많이 해라.
// 개인적으로도 네이버나 국내 검색엔진보다는 구글을 사용하는 것이 좋았다. 되도록이면 한글보다는 영어를 사용해서 전처리를 하는 것이 더 좋다.
- 검색쿼리 Tip: pytho, 모듈, how, 내용을 포함.
[Chapter 02. 데이터를 어떻게 표현할 것인가 - 파이썬 주요 데이터 구조 - 01. 리스트와 튜플]

* 데이터를 어떻게 표현할 것인가: 파이썬 주요 데이터 구조
* 개요
- 리스트(list)와 튜플(tuple) 모두 여러 데이터를 담는 컨테이너형 변수임
- 리스트의 정의: [Data 1, Data 2, ..., Data n]
. 다양한 요소 형태가 가능
ex1) L1 = [1, 2, 3, 4, 5]
ex2) L2 = ['a', 'b', 'c', 1, 2]
ex3) L3 = [1, 2, [3, 4]]
- 튜플의 정의: (Data 1, Data 2, ..., Data n)
ex1) T1 = (1, 2, 3, 4, 5)
ex2) T2 = ('a', 'b', 'c', 1, 2)
ex3) T3 = (1, 2, [3, 4])
* 공통점1. 인덱싱과 슬라이싱
- 리스트와 튜플 모두 인덱싱과 슬라이싱이 가능함
- 인덱싱 방법
. List[i], Tuple[i]: 앞에서 i번째 요소까지 (0부터 시작함)
. List[-i], Tuple[-i]: 뒤에서 i번째 요소(-1부터 시작함)
- 슬라이싱 방법: List[start:end:step], Tuple[start:end:step]
. start인덱스부터 end 인덱스까지 step으로 건너 뛴 부분 리스트 혹은 튜플을 반환
. step은 default가 1로 입력하지 않아도 무방함. List[start:end]
. start와 end도 입력하지 않아도 되나, 콜론( : )은 넣어야 함.
// 콜론을 넣지 않으면 그냥 인덱싱값으로 나온다.
- 연습
List1 = [10, 9, 8, 6]
List1[2]
List1[0:3]
List1[2:]
List1[0:4:2]=> List1[2] = 8
=> List1[0:3] = [10, 9, 8]
=> List1[2: ] = [8, 6]
=> List1[0:4:2] = [10, 8]
위와 같이 인덱싱 및 슬라이싱을 할 수 있다.
슬라이싱 = > 다시 리스트 형태로 반환함
* 공통점2. 순회 가능(interable)
- 리스트와 튜플 모두 for문을 이용하여 순회를 할 수 있음
- 따라서 max, min 등의 순회 가능한 요소를 입력 받는 함수의 입력으로 사용할 수 있음
* 차이점1. 가변과 불변
- 리스트의 요소는 바꿀 수 있으나, 튜플의 요소는 바꿀 수 없음
- 튜플의 요소 변경시에는 Type error가 발생함
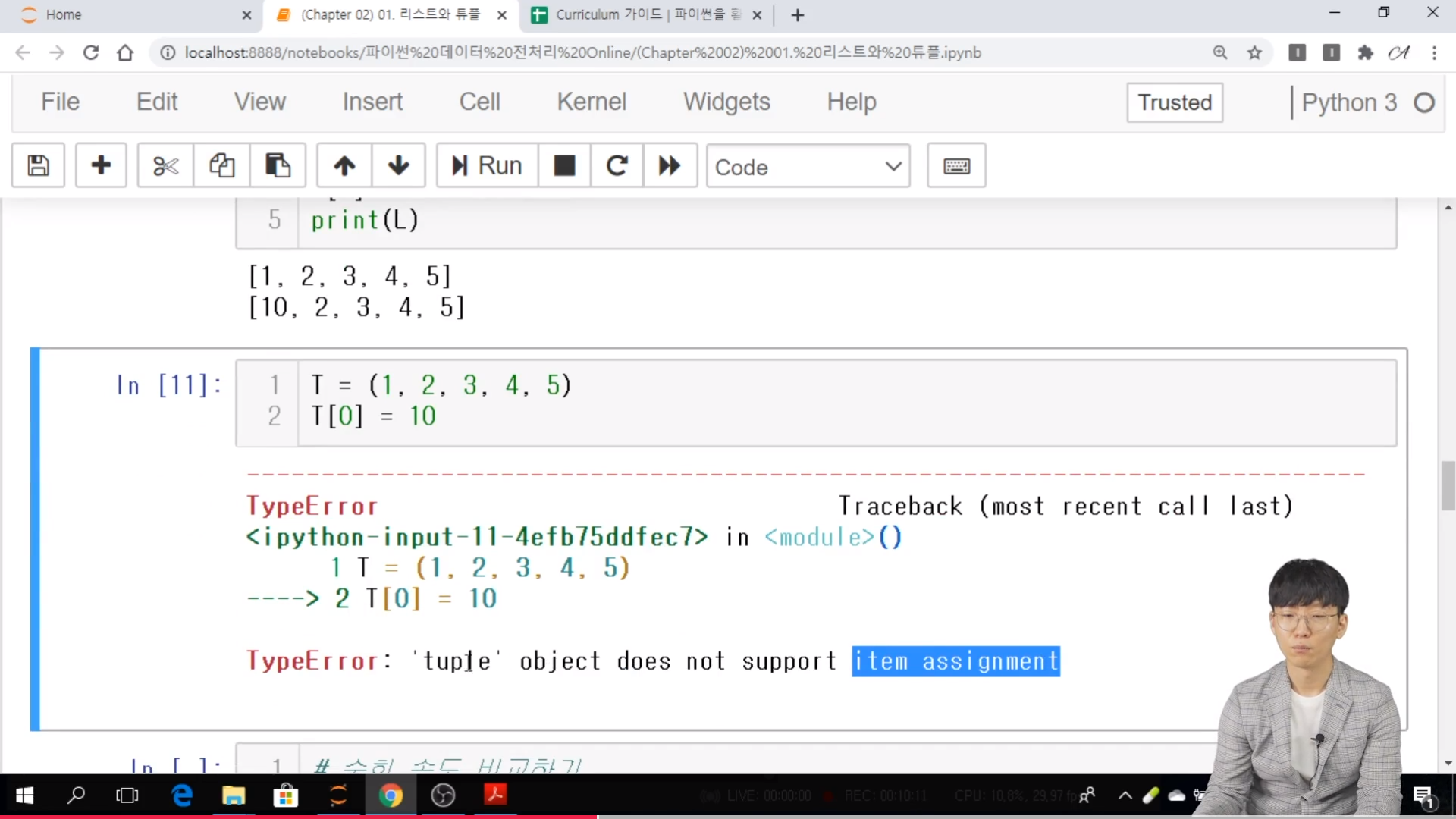
- 따라서 리스트는 사전의 key로 사용할 수 없지만, 튜플은 사전의 key로 사용 가능함.
. Tip1. 불변의 자료형(int, float, str 등)만 사전의 key로 사용할 수 있다.
. Tip2. 조건 등을 입력으로, 해당 조건에 대응되는 값들을 출력으로 하는 사전 구축은 의로 많이 데이터 전처리에서 사용된다.
* 차이점2. 순회 속도
- 순회 속도는 리스트보다 튜플이 약간 더 빠름
- 따라서 요소를 변경할 필요가 없고, 요소에 대한 연산 결과만 필요한 경우에는 리스트보다 튜플이 적합함.
- 데이터가 큰 경우에 한해서, 리스트로 작업후, 튜플로 자료형을 바꾼 후 순회를 하게 시간을 조금이라도 줄 일 수 있게 된다.
- 바꾸는 방법
. 리스트 -> 튜플: tuple(리스트)
. 튜플 -> 리스트: list(튜플)
- time 함수를 사용해서 측정함
// %timeit 을 사용할 수는 없을까?
* 리스트 관련 함수: 요소 추가
- List.append(x): 새로운 요소 x를 맨 뒤에 추가
- List.inser(a, x): 새로운 요소 x를 a위치에 추가 (기존에 있던 요소는 뒤로 한 칸씩 밀림)
- List.remove(x): 기존 요소 x를 제거 (단, x가 여러 개면 맨 앞 하마나 지워지고, 없으면 오류 발생)
- List.pop( ): 맨 마지막 요소를 출력하면서 그 요소를 삭제(stack 구조)
- List.index(x): x의 위치를 반환(단, x가 여러 개면 맨 앞 인덱스를 반환하고, 없으면 오류 발생)
* 리스트 관련 함수: 확장하기
- List1 + List2: 두 리스트를 그대로 이어 붙임(튜플도 가능)
- List1. extend(List2): 함수도 있지만 실제는 더하기 함수를 더 많이 사용한다.
* 튜플 관련 함수
- 튜플은 요소 변경이 불가능하므로, 추가 및 제거 관련 함수를 지원하지 않음.
- 튜플은 사실 소괄호를 쓰지 않아도 된다는 특징 덕분에 SWAP(값을 서로 변경), 함수의 가변인자 및 여러개의 출력을 받는데 많이 사용함.
# 여러개의 요소 일때는 별도의 소괄호를 하지 않아도 인식이 된다.
T = 1, 2, 3, 4
print(T)
# 하나의 요소 일때는 ,를 삽입해줘야 한다.
T = 1,
print(T)=> Result : (1, 2, 3, 4)
자동으로 인식. 여러개의 요소를 가지고 있을 때는 별도 소괄호를 진행하지 않아도 인식이 된다.
=> Result : (1,)만약에 하나의 요소만 튜플로 만들고 싶으면 반드시 ,(쉼표)를 찍어줘야 인식이 된다.
[파이썬을 활용한 데이터 전처리 Level UP-Comment]
현재 데이터는 열심히 모으고 있지만 이것을 어떤식으로 활용할지 또 모은 자료를 어떤식으로 효율적으로 전처리할지에 대해서는 늘 고민이 많았었는데.. 이 기회를 통해서 습득하자!! 열심히~^^
오늘 부터 미션을 위해서 정리하면서 공부해보지만, 다른 여타의 강의와 다르게 기본적인 파이썬 문법을 바로 강의하지 않고 리스트, 튜플에 대해서 먼저 배우기 시작했다. 간략한 문법 설명과 실습을 통해서 빠르게 배울 수 있었다.
앞으로의 강의도 재미있을 것 같다.
파이썬을 활용한 데이터 전처리 Level UP 올인원 패키지 Online. | 패스트캠퍼스
데이터 분석에 필요한 기초 전처리부터, 데이터의 품질 및 머신러닝 성능 향상을 위한 고급 스킬까지 완전 정복하는 데이터 전처리 트레이닝 온라인 강의입니다.
www.fastcampus.co.kr
'Programming > Python' 카테고리의 다른 글
| [패스트캠퍼스 수강 후기] 데이터전처리 100% 환급 챌린지 5 회차 미션 (0) | 2020.11.06 |
|---|---|
| [패스트캠퍼스 수강 후기] 데이터전처리 100% 환급 챌린지 4 회차 미션 (0) | 2020.11.05 |
| [패스트캠퍼스 수강 후기] 데이터전처리 100% 환급 챌린지 3 회차 미션 (0) | 2020.11.04 |
| 주피터 노트북 폰트 변경 (0) | 2020.11.03 |
| [패스트캠퍼스 수강 후기] 데이터전처리 100% 환급 챌린지 2 회차 미션 (0) | 2020.11.03 |


