[패스트캠퍼스 수강 후기] 데이터전처리 100% 환급 챌린지 2 회차 미션 Programming/Python2020. 11. 3. 11:37
[파이썬을 활용한 데이터 전처리 Level UP- 2 회차 미션 시작]
* 복습
어제 데이터 전처리에 대한 대략적인 중요성 및 개요에 대해서 들었으며 리스트와 튜플에 대해서 배워보았다.
리스트와 튜플의 가장 큰 차이점은 튜플은 수정을 할 수 없다는 것이다. 그 외에는 리스트와 튜플의 공통점은 Iteration이 된다는 것 등등 많은 부분이 있었다.

Chapter 02. 데이터를 어떻게 표현할 것인가 - 파이썬 주요 데이터 구조 - 02. 사전
* 개요
- 사전(dictionary)이란 키(key)와 값(value) 쌍으로 이루어진 해시 테이블(hash table)임
- key는 불변의 값을 사용하며, value는 불변 혹은 가변에 상관없이 사용 가능함
- 사전은 다음과 같이 정의할 수 있음
dic = {key 1: value 1, key 2: value 2, key 3: value 3}
// Dictionary에 대한 Documention을 찾아봤다. Data Structures안에 내용들이 함께 들어있었다.
docs.python.org/3/tutorial/datastructures.html#dictionaries
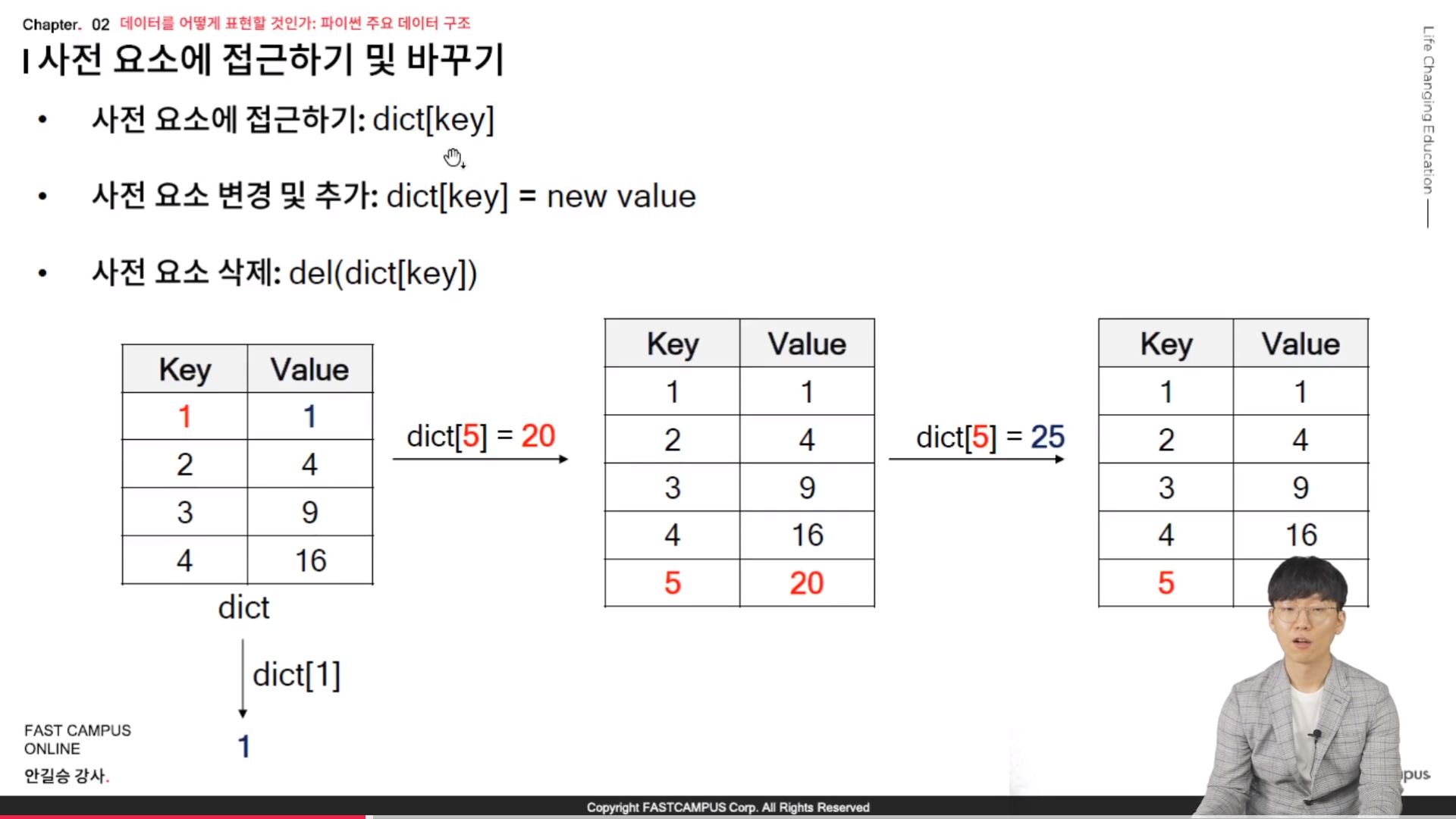
* 사전 요소에 접근하기 및 바꾸기
- 사전 요소에 접근하기: dict[key]
- 사전 요소 변경 및 추가: dict[key] = new value
- 사전 요소 삭제: del(dict[key])
* 사전 관련 함수: 요소 확인하기
- 키 리스트 받기 : .keys( )
- 값 리스트 받기 : .values( )
- key, value 쌍 얻기 : .items( )
=> 위 함수들은 주로 값을 효율적으로 순회하거나 변경할 때 주로 사용된다고 한다.
ex_dict = {"a": "anteater", "b": "bumblebee", "c": "cheetah"}
ex_dict.keys()
# ["a","b","c"]
ex_dict.values()
# ["anteater", "bumblebee", "cheetah"]
ex_dict.items()
# [("a","anteater"),("b","bumblebee"),("c","cheetah")]
// 상기와 같은 내용 이외에도 인터넷으로 공부하다가 알게된 get( ) method
Python provides a .get() method to access a dictionary value if it exists. This method takes the key as the first argument and an optional default value as the second argument, and it returns the value for the specified key if key is in the dictionary. If the second argument is not specified and key is not found then None is returned.
# without default
{"name": "Victor"}.get("name")
# returns "Victor"
{"name": "Victor"}.get("nickname")
# returns None
# with default
{"name": "Victor"}.get("nickname", "nickname is not a key")
# returns "nickname is not a key"// get 메소드를 가끔은 사용할수도 있을 것 같다. 굳이 조건문을 통하지 않더라도 어떠한 dictionary 에 적당한 값이 있는지 없는지를 알기에도 적당할 듯한다.
// 전에 배운 list 형태에서 사용한 pop method 도 사용할 수 있다.
Python dictionaries can remove key-value pairs with the .pop() method. The method takes a key as an argument and removes it from the dictionary. At the same time, it also returns the value that it removes from the dictionary.
famous_museums = {'Washington': 'Smithsonian Institution', 'Paris': 'Le Louvre', 'Athens': 'The Acropolis Museum'}
famous_museums.pop('Athens')
print(famous_museums) # {'Washington': 'Smithsonian Institution', 'Paris': 'Le Louvre'}

Chapter 02. 데이터를 어떻게 표현할 것인가 - 파이썬 주요 데이터 구조 - 03. 반복문과 comprehension
* 반복문 기초
- for문 기초 문법
. 순회 가능한 자료형(리스트, 튜플 등)의 요소를 순서대로 element에 저장하여 특정 구문을 반복함
- break: 현재 속한 반복문을 중지시키며, 보통 if문과 같이 사용
// 사실상 for문법과 함께 while 구문에 대해서 같이 원래 언급을 했는데. 기본적인 문법에 대해서 간략히 하니 확실히 차별성은 느껴진다.
* 대표적인 이터레이터 객체 생성 함수
- 이터레이터 객체는 값을 차례대로 꺼낼 수 있는 객체를 의미 (리스트, 튜플)
- range, itertools 모듈에 있는 주요 함수 등을 통해서도 이터레이터를 생성할 수 있음.
. 단, 이러한 이터레이터는 리스트나 튜플 등이 아니라 순회만 가능한 객체임
* 대표적인 이터레이터 객체 생성 함수 : range
- range(start, end, step)
. start 인데스부터 end 인덱스까지 step으로 건너 뛴 부분 이터레이터 객체를 반환
. 값을 하나만 넣으면 end로 인식됨 : range(end) = ragne(0, end, 1)
. 값을 두 개를 넣으면 start와 end로 인식됨 : range(start, end) = range(start, end, 1)
* 대표적인 이터레이터 객체 생성 함수 : itertools 모듈 함수
- itertools 모듈은 다양한 종류의 이터레이터 객체를 생성하는 함수로 구성됨
- itertools.prouect(*L)
. 순회 가능한 여러 개의 객체를 순서대로 순회하는 이터레이터를 생성
- itertools 모듈 실습
// itertools는 생소해서 구글링을 통해서 좀 알아봤다.
docs.python.org/3/library/itertools.html?highlight=loop
Infinite iterators:
IteratorArgumentsResultsExample
|
start, [step] |
start, start+step, start+2*step, … |
count(10) --> 10 11 12 13 14 ... |
|
|
p |
p0, p1, … plast, p0, p1, … |
cycle('ABCD') --> A B C D A B C D ... |
|
|
elem [,n] |
elem, elem, elem, … endlessly or up to n times |
repeat(10, 3) --> 10 10 10 |
Iterators terminating on the shortest input sequence:
IteratorArgumentsResultsExample
|
p [,func] |
p0, p0+p1, p0+p1+p2, … |
accumulate([1,2,3,4,5]) --> 1 3 6 10 15 |
|
|
p, q, … |
p0, p1, … plast, q0, q1, … |
chain('ABC', 'DEF') --> A B C D E F |
|
|
iterable |
p0, p1, … plast, q0, q1, … |
chain.from_iterable(['ABC', 'DEF']) --> A B C D E F |
|
|
data, selectors |
(d[0] if s[0]), (d[1] if s[1]), … |
compress('ABCDEF', [1,0,1,0,1,1]) --> A C E F |
|
|
pred, seq |
seq[n], seq[n+1], starting when pred fails |
dropwhile(lambda x: x<5, [1,4,6,4,1]) --> 6 4 1 |
|
|
pred, seq |
elements of seq where pred(elem) is false |
filterfalse(lambda x: x%2, range(10)) --> 0 2 4 6 8 |
|
|
iterable[, key] |
sub-iterators grouped by value of key(v) |
||
|
seq, [start,] stop [, step] |
elements from seq[start:stop:step] |
islice('ABCDEFG', 2, None) --> C D E F G |
|
|
func, seq |
func(*seq[0]), func(*seq[1]), … |
starmap(pow, [(2,5), (3,2), (10,3)]) --> 32 9 1000 |
|
|
pred, seq |
seq[0], seq[1], until pred fails |
takewhile(lambda x: x<5, [1,4,6,4,1]) --> 1 4 |
|
|
it, n |
it1, it2, … itn splits one iterator into n |
||
|
p, q, … |
(p[0], q[0]), (p[1], q[1]), … |
zip_longest('ABCD', 'xy', fillvalue='-') --> Ax By C- D- |
Combinatoric iterators:
IteratorArgumentsResults
|
p, q, … [repeat=1] |
cartesian product, equivalent to a nested for-loop |
|
|
p[, r] |
r-length tuples, all possible orderings, no repeated elements |
|
|
p, r |
r-length tuples, in sorted order, no repeated elements |
|
|
p, r |
r-length tuples, in sorted order, with repeated elements |
ExamplesResults
|
product('ABCD', repeat=2) |
AA AB AC AD BA BB BC BD CA CB CC CD DA DB DC DD |
|
permutations('ABCD', 2) |
AB AC AD BA BC BD CA CB CD DA DB DC |
|
combinations('ABCD', 2) |
AB AC AD BC BD CD |
|
combinations_with_replacement('ABCD', 2) |
AA AB AC AD BB BC BD CC CD DD |
- itertools.combinations(p, r)
. 이터레이터 객체 p에서 크기 r의 가능한 모든 조합을 갖는 이터레이터를 생성
Return r length subsequences of elements from the input iterable.
The combination tuples are emitted in lexicographic ordering according to the order of the input iterable. So, if the input iterable is sorted, the combination tuples will be produced in sorted order.
Elements are treated as unique based on their position, not on their value. So if the input elements are unique, there will be no repeat values in each combination.
Roughly equivalent to:
def combinations(iterable, r):
# combinations('ABCD', 2) --> AB AC AD BC BD CD
# combinations(range(4), 3) --> 012 013 023 123
pool = tuple(iterable)
n = len(pool)
if r > n:
return
indices = list(range(r))
yield tuple(pool[i] for i in indices)
while True:
for i in reversed(range(r)):
if indices[i] != i + n - r:
break
else:
return
indices[i] += 1
for j in range(i+1, r):
indices[j] = indices[j-1] + 1
yield tuple(pool[i] for i in indices)// 각 요소들을 조합해서 경우의 수에 대해서 모두 보여 주는 것이다. 이것 또한 잘 만 이용하면 좋을 것 같은데...
The code for combinations() can be also expressed as a subsequence of permutations() after filtering entries where the elements are not in sorted order (according to their position in the input pool):
def combinations(iterable, r):
pool = tuple(iterable)
n = len(pool)
for indices in permutations(range(n), r):
if sorted(indices) == list(indices):
yield tuple(pool[i] for i in indices)The number of items returned is n! / r! / (n-r)! when 0 <= r <= n or zero when r > n.
- itertools.permutations(p, r)
. 이터레이터 객체 p에서 크기 r의 가능한 모든 순열을 갖는 이터레이터를 생성
The code for permutations() can be also expressed as a subsequence of product(), filtered to exclude entries with repeated elements (those from the same position in the input pool):
def permutations(iterable, r=None):
pool = tuple(iterable)
n = len(pool)
r = n if r is None else r
for indices in product(range(n), repeat=r):
if len(set(indices)) == r:
yield tuple(pool[i] for i in indices)// permutations function 안에서도 for 문과, if 문을 이용해서 tuple 형태로 반환해주고 있다.

* list comprehension
- list comprehension은 for문을 사용하여 한 줄로 리스트를 효과적으로 생성하는 방법임
- 예시
- 조건문은 생략 가능함.

* dictionary comprehension
- dictionary comprehension은 for문을 사용하여 한 줄로 사전을 효과적으로 생성하는 방법임
Chapter 02. 데이터를 어떻게 표현할 것인가 - 파이썬 주요 데이터 구조 - 02. Numpy의 데이터 구조

* 개요
- Numpy의 자료형은 ndarray로 효율적인 배열 연산을 하기 위해 개발되었음
- 리스트와 ndarray는 유연성과 효율성을 기준으로 비교할 수 있음
- list는 float, str 등 모든 요소를 저장할 수 있음
- ndarray 는 float, str 등을 정의해줘야 한다.
- ndarray 는 C로 구현된 내부 반복문을 사용하여 속도가 매우 빠른 편이다.
* 배열 만들기: np.array 함수
- np.array 함수를 사용하여 ndarray를 생성할 수 있음
// 사용하기 전에는 numpy 를 import 해줘야 한다.
import numpy as np- np 로 as하는 것은 가장 많이 쓰는 약속 같은 것이다.
// numpy 에 대해서 cheat sheet 를 보는 것이 좋을 것 같아서 검색해보면 죄다. 어디로 연결되거나 길다....
// 공식 홈페이지
// 이곳에서 설명하는 numpy 에 대한 자료는 수백페이지..ㅠ.ㅠ
* 배열 만들기: 다양한 함수
- 관련 함수를 사용해서 특정 패턴을 갖는 ndarray를 생성할 수 있음
. np.zeros(shape)
.. shape(튜플) 모양을 갖는 영벡터/영행렬 생성
.. np.zeros((10,2)) : (10, 2) 크기의 영행렬 생성
// zeros 에 대한 정의는 한번 찾아봤다.
numpy.zeros(shape, dtype=float, order='C')
Return a new array of given shape and type, filled with zeros.
Parametersshapeint or tuple of ints
Shape of the new array, e.g., (2, 3) or 2.
dtypedata-type, optional
The desired data-type for the array, e.g., numpy.int8. Default is numpy.float64.
order{‘C’, ‘F’}, optional, default: ‘C’
Whether to store multi-dimensional data in row-major (C-style) or column-major (Fortran-style) order in memory.
Returnsoutndarray
Array of zeros with the given shape, dtype, and order.
s = (2,2)
np.zeros(s)
# array([[ 0., 0.],
# [ 0., 0.]]). np.arange(start, stop, step)
.. start부터 sotp까지 step만큼 건너뛴 ndarray를 반환 (단, start와 stpe은 생략 가능)
.. np.arrange(1, 5, 0.1) : ndarray([1, 1.1, 1.2, ..., 4.9])
. np.linspace(start, stop, num)
.. start부터 stop까지 num 개수의 요소를 가지는 동간격의 1차원 배열을 반환
.. np.linspace(0, 1, 9) : ndarray([0., 0.125, 0.25, 0.375, 0.5, 0.625, 0.75, 0.875, 1.0])
* 인덱싱과 슬라이싱
- 기본적인 인덱싱과 슬라이싱은 리스트 자료형과 완전히 동일함
- 2차원 배열인 경ㅇ, X[i, j]는 i행 j열에 있는 요소를 나타냄. (c.f. X가 리스트라면, X[i][j]로 접근함.)
- 부울 리스트도 인덱스로 사용할 수 있으며, True인 요소와 대응되는 요소만 가져옴
- 여러 개의 인덱스를 리스트 형태로 입력 받을 수도 있음
* 유니버셜 함수
- 유니버셜 함수는 ndarray의 개별 요소에 반복된 연산을 빠르게 수행하는 것을 주 목적으로 하는 함수
- ndarray x와 y에 대해, 덧셈, 뺄셈, 곱셈, 제곱 등 다양한 배열 간 이항 연산을 지원함.
- 유니버셜 함수는 단순 반복문에 비해, 매우 빠름

* 브로드캐스팅
- 다른 크기의 배열에 유니버셜 함수를 적용하는 규칙 집합으로, 큰 차원의 배열에 맞게 작은 배열이 확장됨.
- 첫번째 케이스와 두번째 케이스가 가장 많이 쓰인다.
- 첫번째 케이스에서 복제를 해서 각각 더한다.
- 브로드캐스팅 예시: z-normalization
* 비교 연산자
- 비교 연산자의 결과는 항상 부울 타입의 배열임
- 따라서 비교 연산자의 결과를 바탕으로 조건에 맞는 요소 탐색에 활용할 수 있음
sum(cond) - True는 1이고, False 0이기 때문에 더해도 개수가 나오게 된다.
[파이썬을 활용한 데이터 전처리 Level UP-Comment]
오늘 강의에서는 새로운 itertools 라는 구문에 대해서 배울 수 있었다. combination 기능을 잘만 이용하면 좀 더 빠른 연산을 할 수 있을 것 같기도 한데.. 불필요한 for 문이나 if 문 등 반복문과 조건문을 줄이기 위해서는 comprehension 문을 잘 사용하여야 하지만, 아직까지 그렇게 손에 있지 않는다.
for 문 내에서도 다양한 조건 등을 걸어서 coding을 하다 보니 코딩만 더러워지고 있다. 거기에 time loose만 들어나고..
좀 더 가다듬을 필요성은 느낀다.
파이썬을 활용한 데이터 전처리 Level UP 올인원 패키지 Online. | 패스트캠퍼스
데이터 분석에 필요한 기초 전처리부터, 데이터의 품질 및 머신러닝 성능 향상을 위한 고급 스킬까지 완전 정복하는 데이터 전처리 트레이닝 온라인 강의입니다.
www.fastcampus.co.kr
'Programming > Python' 카테고리의 다른 글
| [패스트캠퍼스 수강 후기] 데이터전처리 100% 환급 챌린지 5 회차 미션 (0) | 2020.11.06 |
|---|---|
| [패스트캠퍼스 수강 후기] 데이터전처리 100% 환급 챌린지 4 회차 미션 (0) | 2020.11.05 |
| [패스트캠퍼스 수강 후기] 데이터전처리 100% 환급 챌린지 3 회차 미션 (0) | 2020.11.04 |
| 주피터 노트북 폰트 변경 (0) | 2020.11.03 |
| [패스트캠퍼스 수강 후기] 데이터전처리 100% 환급 챌린지 1 회차 미션 (0) | 2020.11.02 |


