[패스트캠퍼스 수강 후기] 데이터전처리 100% 환급 챌린지 4 회차 미션 Programming/Python2020. 11. 5. 10:43
[파이썬을 활용한 데이터 전처리 Level UP- 4 회차 미션 시작]
* 복습
- pandas 에서는 dataframe 및 series 에 대해서 배울 수 있었다. 간단한 head( ), 등 데이터를 둘러 보는 것도 함께 둘러 볼 수 있었다.
- 데이터불러오기는 말 그대로 데이터를 어떻게 불러오는가에 대한 내용이었으며, os 를 이용한 path, 그리고 with 함수 등을 이용하는 것에 대해서 배울 수 있었다.
[Chapter 03. 재료 준비하기 - 데이터 불러오기 - 02. read_csv와 to_csv를 사용한 데이터 불러오기 및 내보내기]
* read_csv 함수를 이용한 데이터 불러오기
- pandas의 read_csv 함수는 테이블 형태의 데이터를 불러오는데 효과적인 함수임
#pd.read_csv(filepath, sep, header, index_col, usecols, parse_dates, nrows)- filepath : 파일 경로 및 이름을 지정할 수 있다.
- sep: 구분자(default : ' , ')
// csv 는 comma 를 기본적으로 구분자로 가진다. 만약 바꾸고 싶으면 sep 를 바꿔주면 될 것이다.
- header : 헤더의 위치로 None을 입력하면 컬럼명이 0, 1, 2, .... 로 자동 부여됨 (default: 'infer')
- index_col : 인덱스의 위치 (default : None)
- usecols : 사용할 컬럼 목록 및 위치 목록 (데이터가 큰 경우에 주로 사용)
// 데이터가 너무 커서 column 별로 데이터를 처리 할 때 많이 사용한다.
- nrows : 불러올 행의 개수 ( 데이터가 큰 경우에 주로 사용)
// 이것 역시 데이터가 큰 경우에 주로 사용하게 된다.
* 실습
- 파일 이름만 해도 default로 데이터가 들어간다.
- 첫번째 값들이 header 로 입력되어 있다.
- tsv 데이터 불러오기
- read_csv 로도 .txt 파일을 불러 올 수 있다. 구분자 sep 을 \t 으로 지정해준다.

- header 가 없는 csv 파일도 불러 올수가 있다. 만약에 header 가 없다면 header keyword 를 header = None 으로 설정해주면 된다.
import pandas as pd
df = pd.read_csv('file.csv', header = None)- 만약에 header = None 으로 설정하지 않으면 첫행이 무조건 header 를 입력한다.
만약에 header 가 3번째 부터 시작하면 header=3 으로 입력하면된다.
- df.columns = [이름] 을 통해서 컬럼 이름을 바꿀 수 있다.
- usecols 를 이용해서 큰 데이터를 불러 올 수 있다. usecols=[0, 1, 5, 10] 등 으로 column index 를 입력하거나 이름을 입력해서 불러 올 수 있다.
- index_col 는 반드시 설정해줘야 한다.
// read_csv 도 pandas method 중 하나이고, 아래에 documentation 이 있다.
pandas.pydata.org/pandas-docs/stable/reference/api/pandas.read_csv.html
// Read a comma-separated values (csv) file into DataFrame. -> comma-separated values (CSV) 의 약자
// encoding 도 많이 사용을 하느데, utf-8, cpc949, euc_kr 등 많이 사용한다.
// 읽을 때도 그렇지만 저장할때는 encoding 이 더 중요하다. 크롤링 등을 통해서 얻어온 자료를 자동으로 저장하다가 낭패를 본 경험도 많이 있다.
pandas.read_csv(filepath_or_buffer, sep=',', delimiter=None, header='infer', names=None, index_col=None, usecols=None, squeeze=False, prefix=None, mangle_dupe_cols=True, dtype=None, engine=None, converters=None, true_values=None, false_values=None, skipinitialspace=False, skiprows=None, skipfooter=0, nrows=None, na_values=None, keep_default_na=True, na_filter=True, verbose=False, skip_blank_lines=True, parse_dates=False, infer_datetime_format=False, keep_date_col=False, date_parser=None, dayfirst=False, cache_dates=True, iterator=False, chunksize=None, compression='infer', thousands=None, decimal='.', lineterminator=None, quotechar='"', quoting=0, doublequote=True, escapechar=None, comment=None, encoding=None, dialect=None, error_bad_lines=True, warn_bad_lines=True, delim_whitespace=False, low_memory=True, memory_map=False, float_precision=None)
encoding : str, optional
Encoding to use for UTF when reading/writing (ex. ‘utf-8’). List of Python standard encodings .
docs.python.org/3/library/codecs.html#standard-encodings
// encoding list 에는 korean 에 해당하는 것들이 아래와 같다.
|
Codec |
Aliases |
Languages |
|
cp949 |
949, ms949, uhc |
Korean |
|
euc_kr |
euckr, korean, ksc5601, ks_c-5601, ks_c-5601-1987, ksx1001, ks_x-1001 |
Korean |
|
iso2022_jp_2 |
iso2022jp-2, iso-2022-jp-2 |
Japanese, Korean, Simplified Chinese, Western Europe, Greek |
|
iso2022_kr |
csiso2022kr, iso2022kr, iso-2022-kr |
Korean |
|
johab |
cp1361, ms1361 |
Korean |
|
utf_8 |
U8, UTF, utf8, cp65001 |
all languages |
|
utf_8_sig |
|
all languages |
* to_csv 함수를 이용한 데이터 저장하기
- pandas의 to_csv 함수는 테이블 형태의 데이터를 저장하는데 효과적인 함수임
# df.to_csv(filepath, sep, index)- filepath -> 파일의 경로 및 이름을 저장한다. 확장자를 포함해줘야 하다.
- sep -> 구분자는 default 값으로 ' , ' 가 자동으로 지정되어 있다.
- index -> index 를 저장할지에 대한 여부를 묻는 것이다.
* 실습
- df.to_csv 를 통해서 저장한다. 확장자는 어떤것이든 상관없이 저장은 가능하나 반드시 설정해야 한다.
- index = False 함수를 통해서 인덱스를 포함하지 않는 것으로 설정할 수 있다.
- 인덱스를 포함하게 되면 cell이 비어 있어서 추후에 불러와서 분석하기가 어렵다. 그래서 컬럼으로 인식시켜서 진행 할때가 많다.
// 아래 documentation 참조
pandas.pydata.org/pandas-docs/stable/reference/api/pandas.DataFrame.to_csv.html
DataFrame.to_csv(path_or_buf=None, sep=',', na_rep='', float_format=None, columns=None, header=True, index=True, index_label=None, mode='w', encoding=None, compression='infer', quoting=None, quotechar='"', line_terminator=None, chunksize=None, date_format=None, doublequote=True, escapechar=None, decimal='.', errors='strict')
[Chapter 03. 재료 준비하기 - 데이터 불러오기 - 03. excel 데이터 불러오기 및 내보내기]

* read_excel 함수를 이용한 데이터 불러오기
- pandas의 read_excel 함수는 .xlsx 포맷의 데이터를 불러오는데 효과적인 함수이다.
# pd.read_excel(filepath, sheet_name, header, index_col, usecols, parse_dates, nrows)- filepath -> 파일 경로 및 이름을 불러 온다.
- shee_name -> 불러오고자 하는 sheet 의 이름 및 위치
// sheet_name 을 설정하지 않으면 보통 맨 앞에 sheet를 불러오게 된다.
- header -> 헤더의 위치로 None을 입력하면 컬럼명이 0~~~ 로 숫자.. 자동 부여된다. (default : 'infer')
- index_col -> 인덱스의 위치 (default: Noen)
- usecols -> 사용할 컬럼 목록 및 우치 목록 (데이터가 큰 경우에 주로 사용하게 된다.)
- nrows -> 불러올 행의 개수( 데이터가 큰 경우)
- skiprows -> 불러오지 않을 행의 위치 (리스트)
// skiprows .. 엑셀을 데이터를 저장한 경우가 많아서 그래서 꾸며진 cell 등을 피할려고 할 때 사용한다.
* 실습
- 보통 첫번째 sheet 는 요약 정보를 보여 주기 때문에 target sheet 를 정해주는 것이 좋다.
- skiprows 는 리스트 형태로 저장해야 한다. 그래서 range(6) 으로 저장해줘야 한다.
- use_col 을 이용해서 할 수 도 있다.
// 아래는 documentation 참조
pandas.pydata.org/pandas-docs/stable/reference/api/pandas.read_excel.html
pandas.read_excel(*args, **kwargs)
engine str, default None
If io is not a buffer or path, this must be set to identify io. Supported engines: “xlrd”, “openpyxl”, “odf”, “pyxlsb”, default “xlrd”. Engine compatibility : - “xlrd” supports most old/new Excel file formats. - “openpyxl” supports newer Excel file formats. - “odf” supports OpenDocument file formats (.odf, .ods, .odt). - “pyxlsb” supports Binary Excel files.
// engine 의 경우에는 openpyxl 을 자주 사용했었는데.. 정확히 어떠한 것이 더 유리한지를 모르겠다. memory 등 time loose 가 너무 심한건 아닌지.. 중복 코드도 의심해봐야 한다.
date_parserfunction, optional
Function to use for converting a sequence of string columns to an array of datetime instances. The default uses dateutil.parser.parser to do the conversion. Pandas will try to call date_parser in three different ways, advancing to the next if an exception occurs: 1) Pass one or more arrays (as defined by parse_dates) as arguments; 2) concatenate (row-wise) the string values from the columns defined by parse_dates into a single array and pass that; and 3) call date_parser once for each row using one or more strings (corresponding to the columns defined by parse_dates) as arguments.
// date_parser 도 은근히 많이 사용하는 option 중에 하나 인것 같은데..
* to_excel 함수
- pandas의 to_excel 함수는 테이블 형태의 데이터를 저장하는데 효과적인 함수이다.
# df.to_excel(filepath, index, shee_name, mode)- filepath -> 파일 경로, 이름
- index -> 인덱스를 저장할지 여부, True, False
- sheet_name -> 시트 명 지정
// csv와 유사히지만 sheet 를 여러개를 저장할 수 있다는 것이 장점임
- 여러 시트를 생성해야 하는 경우에는 excelwriter를 사용함.
// filepath 위치 대신해서 써주면 된다.
# writer = pd.ExcelWriter(xlsx file)
# df1.to_excel(writer, sheet_name = 'sheet1')
# df2.to_excel(writer, sheet_name = 'sheet2')
* 실습
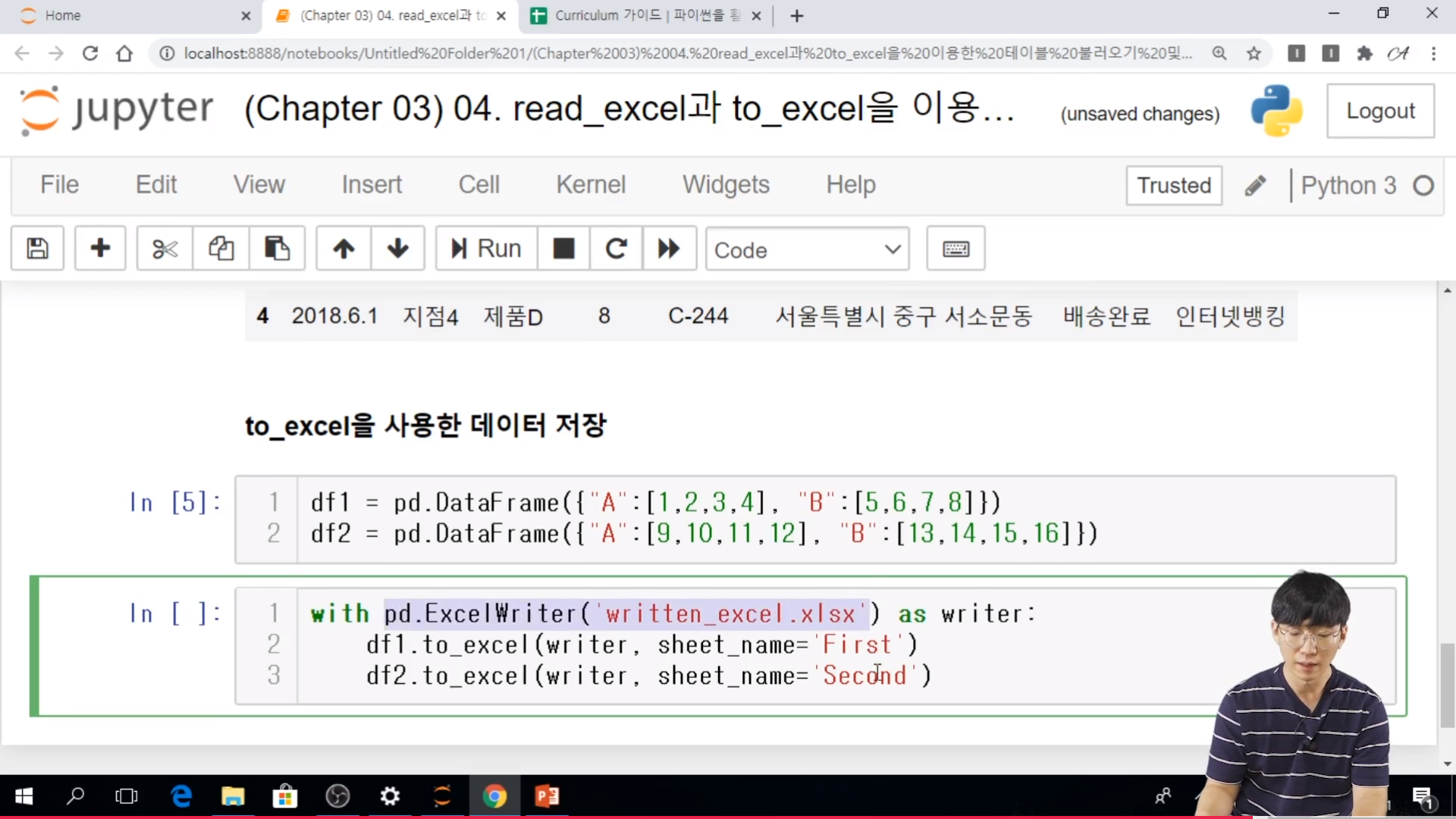
// 여기서도 with 함수를 쓸 수 있다. open 함수랑 동일 한 기능을 사용한다고 보면 된다.
// to_excel documentation
pandas.pydata.org/pandas-docs/stable/reference/api/pandas.DataFrame.to_excel.html
DataFrame.to_excel(excel_writer, sheet_name='Sheet1', na_rep='', float_format=None, columns=None, header=True, index=True, index_label=None, startrow=0, startcol=0, engine=None, merge_cells=True, encoding=None, inf_rep='inf', verbose=True, freeze_panes=None)
// 여기에 있느 to_excel의 parmeters 들은 많이 사용하는 것 같다...
[Chapter 04. 한 눈에 데이터 보기 - 데이터 통합 및 집계 - 01. merge를 이용한 데이터 통합]


* merge가 필요한 상황
- 효율적인 데이터 베이스 관리를 위해서, 잘 정제된 데이터일지라도 데이터가 key 변수를 기준으로 나뉘어 저장되는 경우가 매우 흔하다.
// 공유하고 있는 key를 바탕으로 merge를 사용할 수가 있다.
* pandas.merge
// SQL로 치면 JOIN을 이용하는 것과 동일하다.
- key 변수를 기준으로 두 개의 데이터 프레임을 병함(join) 하는 함수이다.
- 주요 입력
. left -> 통합 대상 데이터 프레임1
. right -> 통합 대상 데이터 프레임2
. on -> 통합 기준 key 변수 및 변수 리스트 (입력을 하지 않으면, 이름이 같은 변수를 key 로 식별함)
// on 을 반드시 써주는 것이 좋다.
. left_on -> 데이터 프레임 1의 key 변수 및 변수 리스트
. right_on -> 데이터 프레임2의 key 변수 및 벼수 리스트
. left_index -> 데이터 프레임1의 인덱스를 key 변수로 사용할 지 여부
. right_index -> 데이터 프레임2의 인덱스를 key 변수로 사용할 지 여부
* 실습
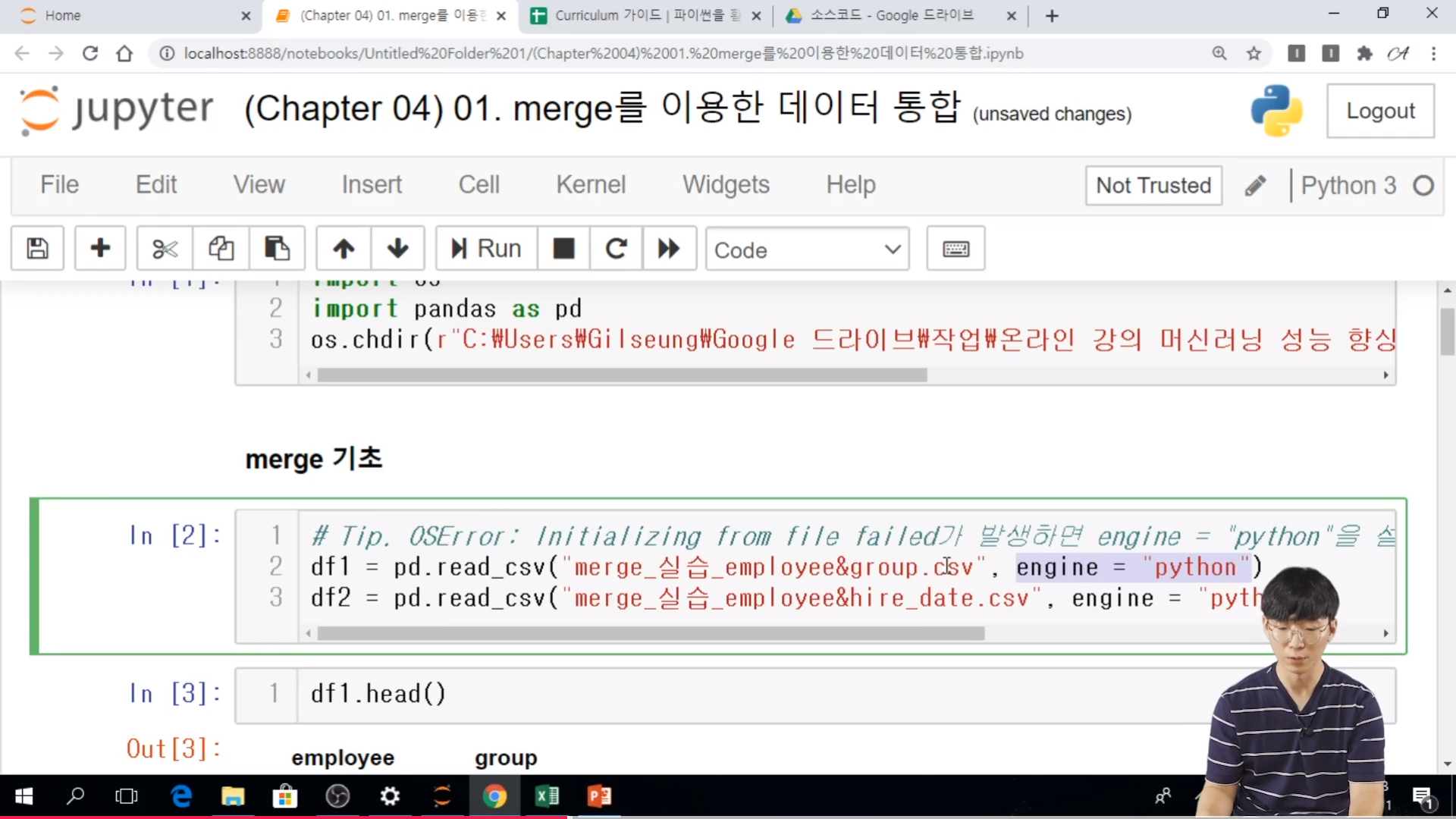
- Tip.. engine = 'python' 은 OSError 를 피하기 위해서 사용하는 것인데. 느려진다는 단점이 있다. 하지만 그걸 예방하기 위해서 사용한다.
- 칼럼명이 같아서 key를 employee 로 인식함.
- on 을 사용해서 각각의 데이터 프레임을 사용할 수도 있고, list 형태로도 만들 수 있다.
- employee 와 name 이 colmun name 만 다르고 내용은 동일하다. 그래서 left_on, right_on 을 사용해서, merge를 할 수가 있다. 하지만, 이런 경우에는 각각의 key column 이 살아 있기 때문에... 지워져야 한다.
- dataframe 에서 컬럼은 axis =1 을 지정해줘야 한다.
- 불러 올때 index_col = 으로 설정해서 인덱스로 불러 올 수 있다.
- 이렇게 되면 right_index = True 값으로 정해줘야지 동일한 key 를 가지는 merge를 사용할수가 있다. 이런 경우에는 위에서 처럼 index 를 사용하지 않을 때 각각 생겨났던 column 이 생겨 나지 않는다. 이건 당연한 것이다. 왜냐하면 index 는 어떤 column 이 아니기 때문이다.
// pandas merge documentation
pandas.pydata.org/pandas-docs/stable/reference/api/pandas.DataFrame.merge.html
DataFrame.merge(right, how='inner', on=None, left_on=None, right_on=None, left_index=False, right_index=False, sort=False, suffixes='_x', '_y', copy=True, indicator=False, validate=None)
// Merge DataFrame or named Series objects with a database-style join. -> DB 스타일의 join.
how{‘left’, ‘right’, ‘outer’, ‘inner’}, default ‘inner’
Type of merge to be performed.
-
left: use only keys from left frame, similar to a SQL left outer join; preserve key order.
-
right: use only keys from right frame, similar to a SQL right outer join; preserve key order.
-
outer: use union of keys from both frames, similar to a SQL full outer join; sort keys lexicographically.
-
inner: use intersection of keys from both frames, similar to a SQL inner join; preserve the order of the left keys.
// how 도 굉장히 많이 쓰는 merge parameter의 한 종류
[파이썬을 활용한 데이터 전처리 Level UP-Comment]
지난 시간에 이어서 데이터를 읽어오는 read_csv, read_excel 등과 각각 저장하는 것에 대해서 배워보았다. merge 함수도 pandas에서 굉장히 사용 빈도가 높은 함수이므로 사용방법에 대해서 좀 더 알아두면 좋을 것 같다.
파이썬을 활용한 데이터 전처리 Level UP 올인원 패키지 Online. | 패스트캠퍼스
데이터 분석에 필요한 기초 전처리부터, 데이터의 품질 및 머신러닝 성능 향상을 위한 고급 스킬까지 완전 정복하는 데이터 전처리 트레이닝 온라인 강의입니다.
www.fastcampus.co.kr
'Programming > Python' 카테고리의 다른 글
| [패스트캠퍼스 수강 후기] 데이터전처리 100% 환급 챌린지 6 회차 미션 (0) | 2020.11.07 |
|---|---|
| [패스트캠퍼스 수강 후기] 데이터전처리 100% 환급 챌린지 5 회차 미션 (0) | 2020.11.06 |
| [패스트캠퍼스 수강 후기] 데이터전처리 100% 환급 챌린지 3 회차 미션 (0) | 2020.11.04 |
| 주피터 노트북 폰트 변경 (0) | 2020.11.03 |
| [패스트캠퍼스 수강 후기] 데이터전처리 100% 환급 챌린지 2 회차 미션 (0) | 2020.11.03 |


