[패스트캠퍼스 수강 후기] 데이터전처리 100% 환급 챌린지 24회차 미션
[파이썬을 활용한 데이터 전처리 Level UP- 24 회차 미션 시작]
* 복습
- 파라미터 튜닝
[04. Part 4) Ch 16. 흩어진 데이터 다 모여라 - 데이터 파편화 문제 - 03. 유형 (3) 포맷이 다른 키 변수가 있는 경우 (1) 참조 데이터가 필요 없는 경우]

* 참조 데이터가 필요 없는 경우의 병합
- 시간과 날짜 컬럼 등은 데이터에 다라 포맷이 다른 경우가 잦음
- 키 변수의 포맷이 다른 두 DataFrame 에 대해 merge 를 적용하면, 비정상적으로 병합이 이뤄질 수 있으므로, 하나의 컬럼을 다른 컬럼의 포맷에 맞게 변경해주는 작업이 필요하다.
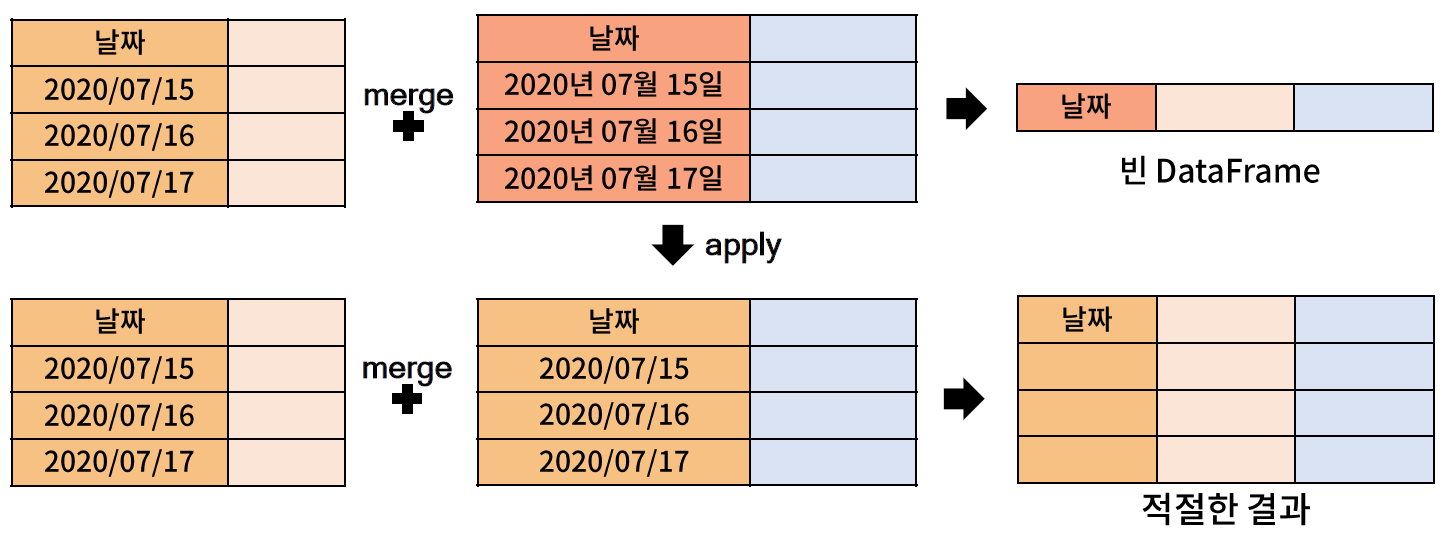
* 관련 문법 : Series.apply
- Series 에 있는 모든 요소에 func 을 일괄 적용하는 함수 (built-in 함수인 map 함수와 유사)
- 주요 입력
. func : Series 의 한 요소를 처리하는 함수

- apply 함수는 머신러닝 코드의 효율성을 위해 굉장히 자주 사용된다.
* 실습
// df1 => 2018-01-01
// df2 => 2018년 1월 1일
// 으로 되어 있기 때문에 각각 포맷을 바꿔 줘야 한다.

// 함수를 짜서 각각 바꿔준다.
// 01 이 있기 때문에 int로 바꿔 준 다음에 1 의 string 타입으로 변경한것이다.
// 다음에는 merge 를 사용해서 각각 합쳐주는 방법이다.
// Series.apply Documentation
pandas.pydata.org/pandas-docs/stable/reference/api/pandas.Series.apply.html
Series.apply(func, convert_dtype=True, args=(), **kwds)Invoke function on values of Series.
Can be ufunc (a NumPy function that applies to the entire Series) or a Python function that only works on single values.
Parameters
funcfunction
Python function or NumPy ufunc to apply.
convert_dtypebool, default True
Try to find better dtype for elementwise function results. If False, leave as dtype=object.
argstuple
Positional arguments passed to func after the series value.
**kwds
Additional keyword arguments passed to func.
Returns
Series or DataFrame
If func returns a Series object the result will be a DataFrame.
[04. Part 4) Ch 16. 흩어진 데이터 다 모여라 - 데이터 파편화 문제 - 03. 유형 (3) 포맷이 다른 키 변수가 있는 경우 (2) 참조 데이터가 필요한 경우]
* 참조 데이터가 필요한 경우의 병합
- 도로명 주소 / 지번 주소, 회원명 / 회원 번호 등과 같이 일정한 패턴이 없이 포맷이 다른 경우에는 컬럼 값을 참조 데이터를 이용하여 변경해야 한다.

// Series 로 되어 있는 것이 참조 데이터이다.
* 관련 문법 : Series.to_dict( )
- Seires 의 Index 를 key, Data 를 Value 로 하는 사전으로 변환

- replace 등 사전을 입력받는 함수를 사용할 때 주로 사용
* 관련문법 : Series.replace
- dict 을 입력 받아, Series 내에 있는 요소 가운데 key 와 같은 값을 value 로 변환해줌

* 실습

// ref_df 를 사전으로 변환. set_index 로 index 를 변경해준다.
// add_prefix( ) 찾아보기
// Padnas.Series.to_dict Documentation
pandas.pydata.org/pandas-docs/stable/reference/api/pandas.Series.to_dict.html
Series.to_dict(into=<class 'dict'>)Convert Series to {label -> value} dict or dict-like object.
Parameters
intoclass, default dict
The collections.abc.Mapping subclass to use as the return object. Can be the actual class or an empty instance of the mapping type you want. If you want a collections.defaultdict, you must pass it initialized.
Returns
collections.abc.Mapping
Key-value representation of Series.
// Pandas.Series.replace Documenation
pandas.pydata.org/pandas-docs/stable/reference/api/pandas.Series.replace.html
Series.replace(to_replace=None, value=None, inplace=False, limit=None, regex=False, method='pad')Replace values given in to_replace with value.
Values of the Series are replaced with other values dynamically. This differs from updating with .loc or .iloc, which require you to specify a location to update with some value.
Parameters
to_replacestr, regex, list, dict, Series, int, float, or None
How to find the values that will be replaced.
-
numeric, str or regex:
-
numeric: numeric values equal to to_replace will be replaced with value
-
str: string exactly matching to_replace will be replaced with value
-
regex: regexs matching to_replace will be replaced with value
-
-
list of str, regex, or numeric:
-
First, if to_replace and value are both lists, they must be the same length.
-
Second, if regex=True then all of the strings in both lists will be interpreted as regexs otherwise they will match directly. This doesn’t matter much for value since there are only a few possible substitution regexes you can use.
-
str, regex and numeric rules apply as above.
-
-
dict:
-
Dicts can be used to specify different replacement values for different existing values. For example, {'a': 'b', 'y': 'z'} replaces the value ‘a’ with ‘b’ and ‘y’ with ‘z’. To use a dict in this way the value parameter should be None.
-
For a DataFrame a dict can specify that different values should be replaced in different columns. For example, {'a': 1, 'b': 'z'} looks for the value 1 in column ‘a’ and the value ‘z’ in column ‘b’ and replaces these values with whatever is specified in value. The value parameter should not be None in this case. You can treat this as a special case of passing two lists except that you are specifying the column to search in.
-
For a DataFrame nested dictionaries, e.g., {'a': {'b': np.nan}}, are read as follows: look in column ‘a’ for the value ‘b’ and replace it with NaN. The value parameter should be None to use a nested dict in this way. You can nest regular expressions as well. Note that column names (the top-level dictionary keys in a nested dictionary) cannot be regular expressions.
-
-
None:
-
This means that the regex argument must be a string, compiled regular expression, or list, dict, ndarray or Series of such elements. If value is also None then this must be a nested dictionary or Series.
-
See the examples section for examples of each of these.
valuescalar, dict, list, str, regex, default None
Value to replace any values matching to_replace with. For a DataFrame a dict of values can be used to specify which value to use for each column (columns not in the dict will not be filled). Regular expressions, strings and lists or dicts of such objects are also allowed.
inplacebool, default False
If True, in place. Note: this will modify any other views on this object (e.g. a column from a DataFrame). Returns the caller if this is True.
limitint, default None
Maximum size gap to forward or backward fill.
regexbool or same types as to_replace, default False
Whether to interpret to_replace and/or value as regular expressions. If this is True then to_replace must be a string. Alternatively, this could be a regular expression or a list, dict, or array of regular expressions in which case to_replace must be None.
method{‘pad’, ‘ffill’, ‘bfill’, None}
The method to use when for replacement, when to_replace is a scalar, list or tuple and value is None.
Changed in version 0.23.0: Added to DataFrame.
Returns
Series
Object after replacement.
Raises
AssertionError
-
If regex is not a bool and to_replace is not None.
TypeError
-
If to_replace is not a scalar, array-like, dict, or None
-
If to_replace is a dict and value is not a list, dict, ndarray, or Series
-
If to_replace is None and regex is not compilable into a regular expression or is a list, dict, ndarray, or Series.
-
When replacing multiple bool or datetime64 objects and the arguments to to_replace does not match the type of the value being replaced
ValueError
-
If a list or an ndarray is passed to to_replace and value but they are not the same length.
// pandas.DataFrame.add_prefix Documentation
pandas.pydata.org/docs/reference/api/pandas.DataFrame.add_prefix.html
DataFrame.add_prefix(prefix)Prefix labels with string prefix.
For Series, the row labels are prefixed. For DataFrame, the column labels are prefixed.
Parameters
prefixstr
The string to add before each label.
Returns
Series or DataFrame
New Series or DataFrame with updated labels.
[04. Part 4) Ch 16. 흩어진 데이터 다 모여라 - 데이터 파편화 문제 - 04. 유형 (4) 거리 기반 병합이 필요한 경우]

* 문제 정의 및 해결 방안
- 아파트 가격 예측 등 지역이 포함되는 문제에서 주소나 위치 변수 등을 기준으로 거리가 가까운 레코드 및 관련 통계치를 통합해야 하는 경우가 종종 있음
// 특히나 지리 데이터를 처리 할 때 많이 일어난다.
- 일반적으로 (1) 각 데이터에 포함된 간 거리를 나타내는 거리 행렬을 생성하고, (2) 거리 행렬의 행 혹은 열 기준 최소 값을 가지는 인덱스를 바탕으로 이웃을 탐색한 뒤, (3) 이웃을 기존 데이터에 부착하는 방식으로 해결함

* 관련문법 : scipy.spatial.distance.cdist
- 두 개의 행렬을 바탕으로 거리 행렬을 반환하는 함수
- 주요 입력
. XA : 거리 행렬 계산 대상인 행렬 (ndarray 및 DataFrame) 로, 함수 출력의 행에 해당
. XB : 거리 행렬 계산 대상인 행렬 (ndarrary 및 DataFrame) 로, 함수 출력의 열에 해당
. metric : 거리 척도 ('cityblock', 'correlation', 'cosine', 'euclidean', 'jaccard', 'matching' 등)

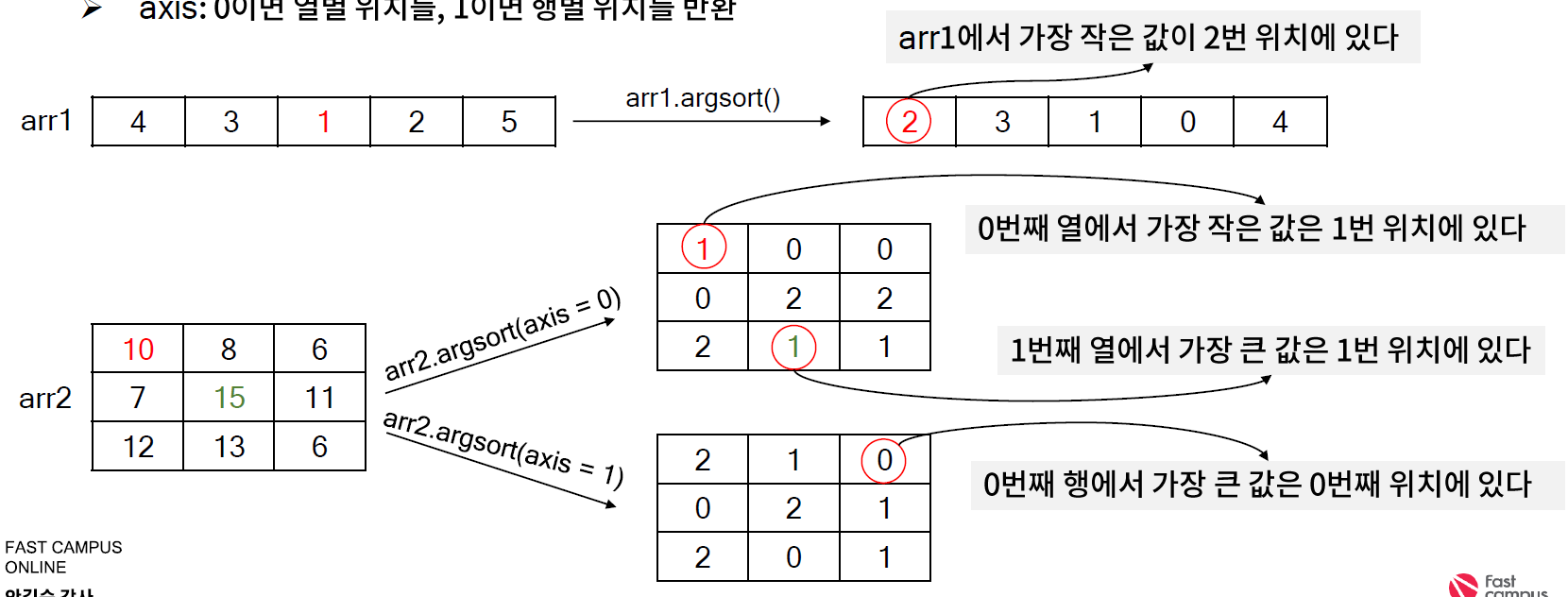
* 관련문법 : ndarray.argsort
- 작은 값부터 순서대로 데이터의 위치를 반환하는 함수로, 이웃을 찾는데 주로 활용 되는 함수
- 주요 입력
. axis : 0 이면 열별 위치를, 1이면 행별 위치를 반환
* 실습

// 각각의 데이터를 merge 를 해준다. 순서를 지키면서 해야 한다. 아니면 merge 가 되지 않는다.

// 역에 대한 위경도로 확인한다.
// 거리 행렬 생성을 위한 컬럼들을 추출한다.
// 위경도 거리 계산을 위한 모듈을 설치한다.
// !pip install haversine 현실감을 위해서 이 라이브러리를 설치 한다.
!pip install haversineCalculate the distance (in various units) between two points on Earth using their latitude and longitude.
[파이썬을 활용한 데이터 전처리 Level UP-Comment]
- merge, apply, argsort, haversine 등을 배울 수 있었다.
파이썬을 활용한 데이터 전처리 Level UP 올인원 패키지 Online. | 패스트캠퍼스
데이터 분석에 필요한 기초 전처리부터, 데이터의 품질 및 머신러닝 성능 향상을 위한 고급 스킬까지 완전 정복하는 데이터 전처리 트레이닝 온라인 강의입니다.
www.fastcampus.co.kr