[패스트캠퍼스 수강 후기] 데이터전처리 100% 환급 챌린지 22회차 미션
[파이썬을 활용한 데이터 전처리 Level UP- 22 회차 미션 시작]
* 복습
- 모델 개발 프로세스에 대해서 배웠고, 지도학습에서는 선형회귀, 의사결정나무, 신경망 등에 대해서도 배워 볼 수 있었다.
[03. Part 3) Ch 15. 이럴땐 이걸 쓰고, 저럴땐 저걸 쓰고 - 지도 학습 모델 & 파라미터 선택 - 01. 그리드 서치]

* 모델 및 파라미터 선정 문제
- 어떠한 데이터에 대해서도 우수한 모델과 그 하이퍼 파라미터는 절대 존재하지 않는다.

- 또한, 분석적인 방법으로 좋은 모델과 하이퍼 파라미터를 선정하는 것도 불가능하다.
* 그리드 서치 개요
- 하이퍼 파라미터 그리드는 한 모델의 하이퍼 파라미터 조합을 나타내며, 그리드 서치란 하이퍼 파라미터 그리드에 속한 모든 파라미터 조합을 비교 평가하는 방법을 의미
// 거리 척도
- 예시 : k - 최근접 이웃의 파라미터 그리드

=> 총 여섯 개의 하이퍼 파라미터 조합에 대한 성능을 평가하여, 그 중 가장 우수한 하이퍼 파라미터를 선택
* 그리드 서치 코드 구현
- sklearn 을 활용하여 그리드 서치를 구현하려면 사전 형태로 하이퍼 파라미터 그리드를 정의해야 한다.
. key: 하이퍼 라미터명(str)
. value : 해당 파라미터의 범위 (list)

* 그리드 서치 코드 구현 : GridSearchCV
- sklearn.model_selection.GridSearchCV
. 주요 입력
.. estimator : 모델 (sklearn 인스턴스)
.. param_grid : 파라미터 그리드 (사전)
.. cv : k 겹 교차 검증에서의 k (2 이상의 자연수)
.. scoring_func : 평가 함수 (sklearn 평가 함수)
. GridSearchCV 인스턴스(GSCV) 의 주요 method 및 attribute
.. GSCV = GridSearchCV (estimator, param_grid, cv, scoring_func) : 인스턴스화
.. GSCV.fit(X, Y) : 특징 벡터 X 와 라벨 Y 에 대해 param_grid 에 속한 파라미터를 갖는 모델을 k - 겹 교차 검증 방식으로 평가하여, 그 중 가장 우수한 파라미터를 찾는다.
.. GSCV.get_params( ) : 가장 우수한 파라미터를 반환
. 사용이 편하다는 장점이 있지만, k - 겹 교차 검증 방식을 사용하기에 느리고, 성능 향상을 위한 전처리 기법을 적용할 수 없다는 단점이 있다.
* 그리드 서치 코드 구현 : ParameterGrid
- sklearn.model_selection.ParameterGrid
. param_grid (사전 형태의 하이퍼 파라미터 그리드) 를 입력 받아, 가능한 모든 파라미터 조합 (사전) 을 요소로 하는 generator 를 반환하는 함수

. GridSearchCV 에 비해 사용이 어렵다는 단점이 있지만, 성능 향상을 위한 전처리 기법을 적용하는데 문제가 없어서 실무에서 휠씬 자주 사용된다.
* ParameterGrid 사용을 위해 알아야 하는 문법 (1/2)
- 파이썬 함수의 입력으로 사전 자료형을 사용하는 경우에는 ** 를 사전 앞에 붙여야 한다.
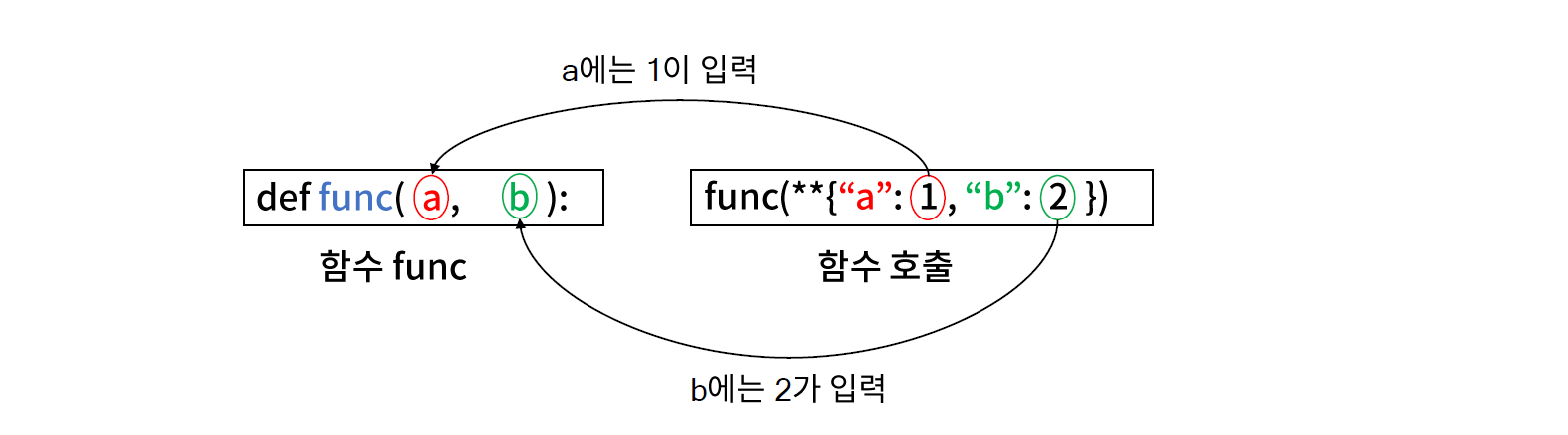
- 이를 활용하면, ParameterGrid 인스턴스를 순회하는 사전 자료형인 변수(파라미터)를 모델의 입력으로 넣을 수 있다.
* ParameterGrid 사용을 위해 알아야 하는 문법 (2/2)
- ParameterGrid 인스턴스를 순회하면서 성능이 가장 우수한 값을 찾으려면 최대값(최소값) 을 찾는 알고리즘을 알아야 한다.
. 내장 함수인 max 함수나 min 함수를 사용해도 되지만, 평가해야 하는 하이퍼 파라미터 개수가 많으면 불필요한 메모리 낭비로 이어질 수 있으며, 더욱이 모델도 같이 추가되야 하므로 메모리 에러로 이어지기 쉽다.
- 알고리즘 예시 : L = [10, 20, 30, 10, 20] 에서의 최대닶을 찾아라.

* 실습

// 비교를 위해서 list 형태로 바꿔준다.
// 실제로는 바꿔주지 않고 parametergrid(grid) 로 순회한다.
// a 와 b 의 순서는 크게 상관이 없다.
// max_value 는 메우 작은 값을 설정 한다. 음의 무한대를 주는 것이 좋지만, domain 이 있으면 그 가장 값을 지정한다.
// 최소값 min_value 는 매우 큰 값으로 잡아 준다. 나머지는 동일하게 적용한다.

// 모델은 여러가지로 적용해보는 것이 좋다.
// sklearn.model_selection.GridSearchCV Documentation
scikit-learn.org/stable/modules/generated/sklearn.model_selection.GridSearchCV.html
class sklearn.model_selection.GridSearchCV(estimator, param_grid, *, scoring=None, n_jobs=None, iid='deprecated', refit=True, cv=None, verbose=0, pre_dispatch='2*n_jobs', error_score=nan, return_train_score=False)Exhaustive search over specified parameter values for an estimator.
Important members are fit, predict.
GridSearchCV implements a “fit” and a “score” method. It also implements “predict”, “predict_proba”, “decision_function”, “transform” and “inverse_transform” if they are implemented in the estimator used.
The parameters of the estimator used to apply these methods are optimized by cross-validated grid-search over a parameter grid.
Read more in the User Guide.
Parameters
estimatorestimator object.
This is assumed to implement the scikit-learn estimator interface. Either estimator needs to provide a score function, or scoring must be passed.
param_griddict or list of dictionaries
Dictionary with parameters names (str) as keys and lists of parameter settings to try as values, or a list of such dictionaries, in which case the grids spanned by each dictionary in the list are explored. This enables searching over any sequence of parameter settings.
scoringstr, callable, list/tuple or dict, default=None
A single str (see The scoring parameter: defining model evaluation rules) or a callable (see Defining your scoring strategy from metric functions) to evaluate the predictions on the test set.
For evaluating multiple metrics, either give a list of (unique) strings or a dict with names as keys and callables as values.
NOTE that when using custom scorers, each scorer should return a single value. Metric functions returning a list/array of values can be wrapped into multiple scorers that return one value each.
See Specifying multiple metrics for evaluation for an example.
If None, the estimator’s score method is used.
n_jobsint, default=None
Number of jobs to run in parallel. None means 1 unless in a joblib.parallel_backend context. -1 means using all processors. See Glossary for more details.
Changed in version v0.20: n_jobs default changed from 1 to None
pre_dispatchint, or str, default=n_jobs
Controls the number of jobs that get dispatched during parallel execution. Reducing this number can be useful to avoid an explosion of memory consumption when more jobs get dispatched than CPUs can process. This parameter can be:
None, in which case all the jobs are immediately created and spawned. Use this for lightweight and fast-running jobs, to avoid delays due to on-demand spawning of the jobs
An int, giving the exact number of total jobs that are spawned
A str, giving an expression as a function of n_jobs, as in ‘2*n_jobs’
iidbool, default=False
If True, return the average score across folds, weighted by the number of samples in each test set. In this case, the data is assumed to be identically distributed across the folds, and the loss minimized is the total loss per sample, and not the mean loss across the folds.
Deprecated since version 0.22: Parameter iid is deprecated in 0.22 and will be removed in 0.24
cvint, cross-validation generator or an iterable, default=None
Determines the cross-validation splitting strategy. Possible inputs for cv are:
-
None, to use the default 5-fold cross validation,
-
integer, to specify the number of folds in a (Stratified)KFold,
-
An iterable yielding (train, test) splits as arrays of indices.
For integer/None inputs, if the estimator is a classifier and y is either binary or multiclass, StratifiedKFold is used. In all other cases, KFold is used.
Refer User Guide for the various cross-validation strategies that can be used here.
Changed in version 0.22: cv default value if None changed from 3-fold to 5-fold.
refitbool, str, or callable, default=True
Refit an estimator using the best found parameters on the whole dataset.
For multiple metric evaluation, this needs to be a str denoting the scorer that would be used to find the best parameters for refitting the estimator at the end.
Where there are considerations other than maximum score in choosing a best estimator, refit can be set to a function which returns the selected best_index_ given cv_results_. In that case, the best_estimator_ and best_params_ will be set according to the returned best_index_ while the best_score_ attribute will not be available.
The refitted estimator is made available at the best_estimator_ attribute and permits using predict directly on this GridSearchCV instance.
Also for multiple metric evaluation, the attributes best_index_, best_score_ and best_params_ will only be available if refit is set and all of them will be determined w.r.t this specific scorer.
See scoring parameter to know more about multiple metric evaluation.
Changed in version 0.20: Support for callable added.
verboseinteger
Controls the verbosity: the higher, the more messages.
error_score‘raise’ or numeric, default=np.nan
Value to assign to the score if an error occurs in estimator fitting. If set to ‘raise’, the error is raised. If a numeric value is given, FitFailedWarning is raised. This parameter does not affect the refit step, which will always raise the error.
return_train_scorebool, default=False
If False, the cv_results_ attribute will not include training scores. Computing training scores is used to get insights on how different parameter settings impact the overfitting/underfitting trade-off. However computing the scores on the training set can be computationally expensive and is not strictly required to select the parameters that yield the best generalization performance.
New in version 0.19.
Changed in version 0.21: Default value was changed from True to False
Attributes
cv_results_dict of numpy (masked) ndarrays
A dict with keys as column headers and values as columns, that can be imported into a pandas DataFrame.
For instance the below given table
|
param_kernel |
param_gamma | param_degree | split0_test_score… |
|
rank_t… |
|
‘poly’ |
– |
2 |
0.80 |
… |
2 |
|
‘poly’ |
– |
3 |
0.70 |
… |
4 |
|
‘rbf’ |
0.1 |
– |
0.80 |
… |
3 |
|
‘rbf’ |
0.2 |
– |
0.93 |
… |
1 |
will be represented by a cv_results_ dict of:
{ 'param_kernel': masked_array(data = ['poly', 'poly', 'rbf', 'rbf'], mask = [False False False False]...) 'param_gamma': masked_array(data = [-- -- 0.1 0.2], mask = [ True True False False]...), 'param_degree': masked_array(data = [2.0 3.0 -- --], mask = [False False True True]...), 'split0_test_score' : [0.80, 0.70, 0.80, 0.93], 'split1_test_score' : [0.82, 0.50, 0.70, 0.78], 'mean_test_score' : [0.81, 0.60, 0.75, 0.85], 'std_test_score' : [0.01, 0.10, 0.05, 0.08], 'rank_test_score' : [2, 4, 3, 1], 'split0_train_score' : [0.80, 0.92, 0.70, 0.93], 'split1_train_score' : [0.82, 0.55, 0.70, 0.87], 'mean_train_score' : [0.81, 0.74, 0.70, 0.90], 'std_train_score' : [0.01, 0.19, 0.00, 0.03], 'mean_fit_time' : [0.73, 0.63, 0.43, 0.49], 'std_fit_time' : [0.01, 0.02, 0.01, 0.01], 'mean_score_time' : [0.01, 0.06, 0.04, 0.04], 'std_score_time' : [0.00, 0.00, 0.00, 0.01], 'params' : [{'kernel': 'poly', 'degree': 2}, ...], }NOTE
The key 'params' is used to store a list of parameter settings dicts for all the parameter candidates.
The mean_fit_time, std_fit_time, mean_score_time and std_score_time are all in seconds.
For multi-metric evaluation, the scores for all the scorers are available in the cv_results_ dict at the keys ending with that scorer’s name ('_<scorer_name>') instead of '_score' shown above. (‘split0_test_precision’, ‘mean_train_precision’ etc.)
best_estimator_estimator
Estimator that was chosen by the search, i.e. estimator which gave highest score (or smallest loss if specified) on the left out data. Not available if refit=False.
See refit parameter for more information on allowed values.
best_score_float
Mean cross-validated score of the best_estimator
For multi-metric evaluation, this is present only if refit is specified.
This attribute is not available if refit is a function.
best_params_dict
Parameter setting that gave the best results on the hold out data.
For multi-metric evaluation, this is present only if refit is specified.
best_index_int
The index (of the cv_results_ arrays) which corresponds to the best candidate parameter setting.
The dict at search.cv_results_['params'][search.best_index_] gives the parameter setting for the best model, that gives the highest mean score (search.best_score_).
For multi-metric evaluation, this is present only if refit is specified.
scorer_function or a dict
Scorer function used on the held out data to choose the best parameters for the model.
For multi-metric evaluation, this attribute holds the validated scoring dict which maps the scorer key to the scorer callable.
n_splits_int
The number of cross-validation splits (folds/iterations).
refit_time_float
Seconds used for refitting the best model on the whole dataset.
This is present only if refit is not False.
New in version 0.20.
// sklearn.model_selection.ParameterGrid Documentation
scikit-learn.org/stable/modules/generated/sklearn.model_selection.ParameterGrid.html
class sklearn.model_selection.ParameterGrid(param_grid)[source]Grid of parameters with a discrete number of values for each.
Can be used to iterate over parameter value combinations with the Python built-in function iter.
Read more in the User Guide.
Parametersparam_griddict of str to sequence, or sequence of such
The parameter grid to explore, as a dictionary mapping estimator parameters to sequences of allowed values.
An empty dict signifies default parameters.
A sequence of dicts signifies a sequence of grids to search, and is useful to avoid exploring parameter combinations that make no sense or have no effect. See the examples below.
[03. Part 3) Ch 15. 이럴땐 이걸 쓰고, 저럴땐 저걸 쓰고 - 지도 학습 모델 & 파라미터 선택 - 02. 기준 (1) 변수 타입]

* 변수 타입 확인 방법
- DataGrame.dtypes
. DataFrame 에 포함된 컬럼들의 데이터 타입 ( object, int64, float64, bool 등 ) 을 반환
- DataFrame.infer_objects( ).dtypes
. DataFrame 에 포함된 컬럼들의 데이터 타입을 추론한 결과를 반환
. (예) ['1', '2'] 라는 값을 가진 컬럼은 비록 object 타입이나, int 타입이라고 추론할 수 있다.
- 주의 : string type 이라고 해서 반드시 범주형이 아니며, int 혹은 float type 이라고 해서 반드시 연속형은 아니다. 반드시 상태 공간의 크기와 도메인 지식 등을 고려해야 한다.
* 변수 타입에 따른 적절한 모델
- 주의 : 모델 성능에는 변수 타입만 영향을 주는 것이 아니므로, 다른 요소도 반드시 고려해야 한다.

* 혼합형 변쉥 적절하지 않은 모델 (1) 회귀 모델
- 혼합형 변수인 경우에는 당연히 변수의 스케일 차이가 존재하는 경우가 흔하다.
- 변수의 스케일에 따라 계수 값이 크게 달라지므로, 예측 안정성이 크게 떨어진다.
. 모든 특징이 라벨에 독립적으로 영향을 준다면, 이진형 특징의 계수 절대값이 스케일이 큰 연속형 특징의 계수 절대값 보다 크게 설정된다.
. 이진형 특징 값에 따라 예측 값이 크게 변동한다.
- 스케일일ㅇ을 하더라도 이진형 특징의 분포가 변하지 않으므로, 이진형 특징의 값에 따른 영향력이 크게 줄지 않는다.
* 혼합형 변수에 적절하지 않은 모델 (2) 나이브 베이즈
- 나이브베이즈는 하나의 확률 분포를 가정하기 때문에, 혼합형 변수를 가지는 데이터에 부적절하다.
. (예시) 베르누이 분포는 연속형 값을 가지는 확률 분포 추정에 매우 부적절
- 따라서 나이브베이즈는 혼합형 변수인 경우에는 절대로 고려해서는 안 되는 모델이다.
* 혼합형 변수에 적절하지 않은 모델 (3) k - 최근접 이웃
- 스케일이 큰 변수에 의해 거리가 사실상 결정되므로, k-NN 은 혼합형 변수에 적절하지 않다.
- 단, 코사인 유사도를 사용하는 경우나, 스케일링을 적용하는 경우에는 큰 무리 없이 사용 가능하다.
[03. Part 3) Ch 15. 이럴땐 이걸 쓰고, 저럴땐 저걸 쓰고 - 지도 학습 모델 & 파라미터 선택 - 03. 기준 (2) 데이터 크기]

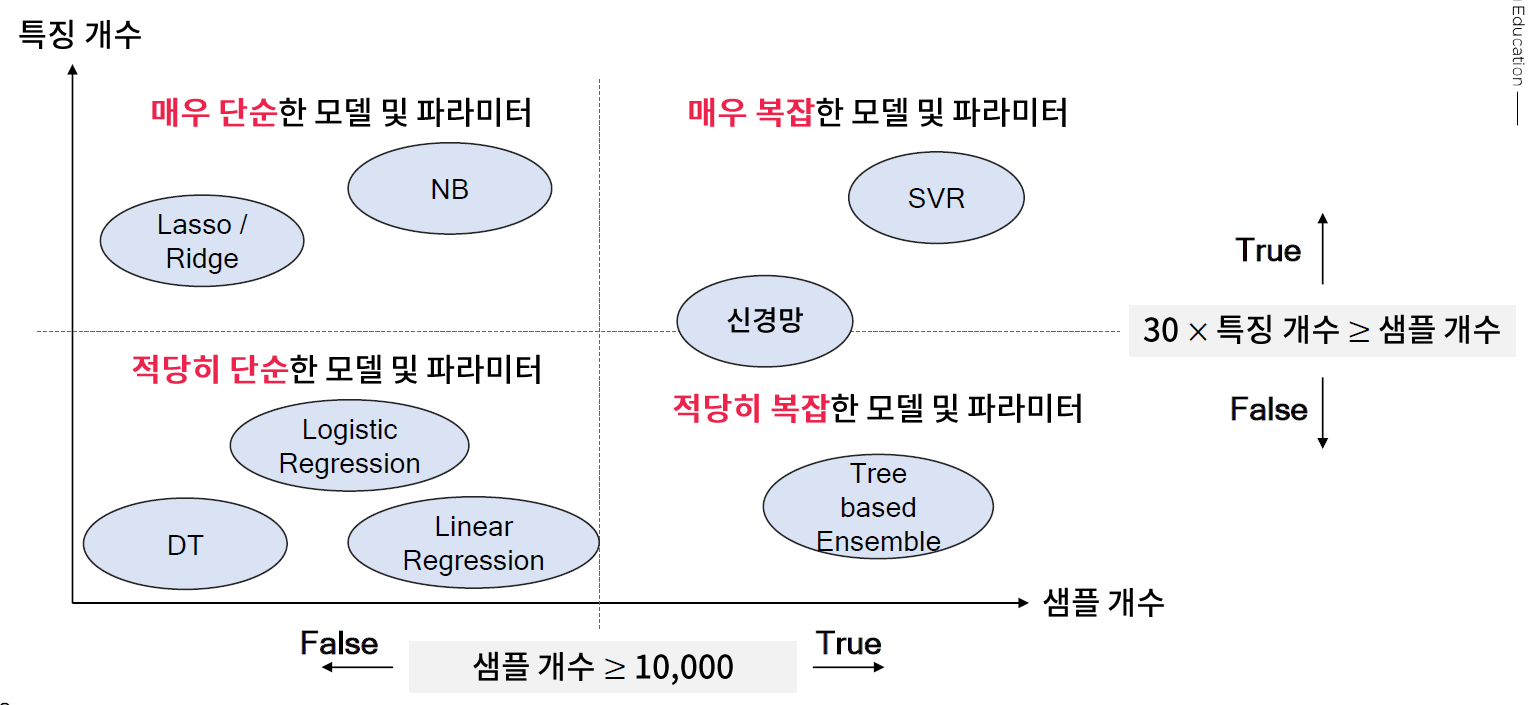
* 샘플 개수와 특징 개수에 따른 과적합 (remind)

* 샘플 개수와 특징 개수에 따른 적절한 모델
* 실습
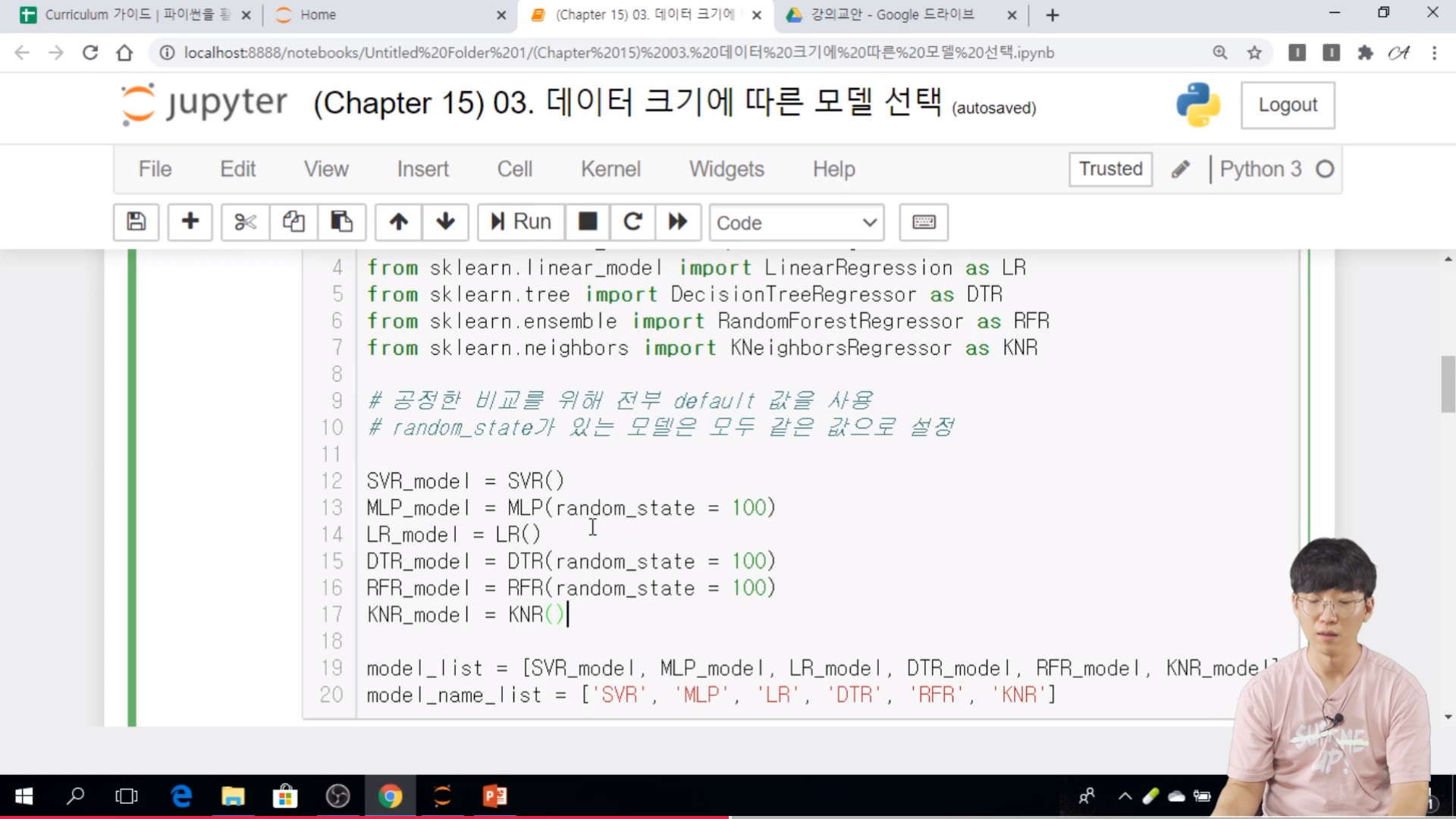
// random_state 가 있는 모델은 모두 같은 값으로 설정한다.
// 모델별 k 겹 교차 검증 기반 (k=5) 의 MAE 값으로 계산한다.
// cv 는 폴더의 갯수. k 값
// 특징이 적으면 복잡한 모델은 나오기 어렵다.
// 샘플이 매우 적고 특징이 상대적으로 많은 경우
[파이썬을 활용한 데이터 전처리 Level UP-Comment]
- 지도학습할 때의 Grid 서치 및 parameterGrid 에 대해서 배울 수 있었다. 동영상 순서가 이상해서 처음엔 약간 이상했지만~^^;;
파이썬을 활용한 데이터 전처리 Level UP 올인원 패키지 Online. | 패스트캠퍼스
데이터 분석에 필요한 기초 전처리부터, 데이터의 품질 및 머신러닝 성능 향상을 위한 고급 스킬까지 완전 정복하는 데이터 전처리 트레이닝 온라인 강의입니다.
www.fastcampus.co.kr