[패스트캠퍼스 수강 후기] 데이터전처리 100% 환급 챌린지 21회차 미션
[파이썬을 활용한 데이터 전처리 Level UP- 20 회차 미션 시작]
* 복습
- 지난번 실습에 대해서도 학습했었고, 특히 지도학습에 대한 부분들이 다시 한번 복습을 해야 할 것 같다.
[03. Part 3) Ch 14. 이건 꼭 알아야 해 - 지도 학습 모델의 핵심 개념 - 02. 모델 개발 프로세스]

* 책에서나 볼 수 있는 프로세스

// 이상적인 프로세스라고 보면 된다.
* 문제 정의
- 전체 프로세스 가운데 가장 중요한 단계로, 명확한 목적 의식을 가지고 프로세스를 시작해야 한다.
// 어떤 것을 예측할 것인것인지, 어떤것을 특징으로 사용할 것인지를 정확하게 지정해야 한다.
- 이 단계에서 수행하는 활동은 다음과 같다.
. 과업 종류 결정 (분류 , 예측 등)
. 클래스 정의
. 도메인 지식 기반의 특징 정의
// 데이터가 수집전이라서 그 분야에 관련된 지식인 도메인 지식을 활용해야 한다.
. 사용 데이터 정의
* 데이터 수집
- 문제 정의에서 정의한 데이터를 수집하는 단계로, 크롤링, 센서 활용, 로그 활용 등으로 데이터를 수집
// survey 등도 활용할 수 있다.
- 기업 내 구축된 DB에서 SQL을 통해 추출하는 경우가 가장 많으며, 이때는 클래스를 중심으로 수집
* 데이터 탐색
// 이 강의에서 초점을 두고 있는 단계
- 데이터가 어떻게 생겼는지를 확인하여, 프로세스를 구체화하는 단계
- 데이터 탐색 단계에서 변수별 분포, 변수 간 상관성, 이상치와 결측치, 변수 개수, 클래스 변수 분포 등을 확인하며, 이 탐색 결과는 데이터 전처리 및 모델 선택에 크게 영향을 미침
. 데이터 크기 확인 -> 과적합 가능성 확인 및 특징 선택 고려
. 특징별 기술 통계 -> 특징 변환 고려 및 이상치 제거 고려
. 특징 간 상관성 -> 특징 삭제 및 주성분 분석 고려
. 결측치 분포 -> 결측치 제거 및 추정 고려
. 변수 개수 -> 차원 축소 기법 고려
. 클래스 변수 분포 -> 비용민감 모델 및 재샘플링 고려
// 탐색결과를 모델링과 전처리에 반영을 한다고 보면 된다.
* 데이터 전처리
- 원활한 모델링을 위해 데이터를 가공하는 단계로, 여기서 수행하는 대표적인 작업은 다음과 같다.
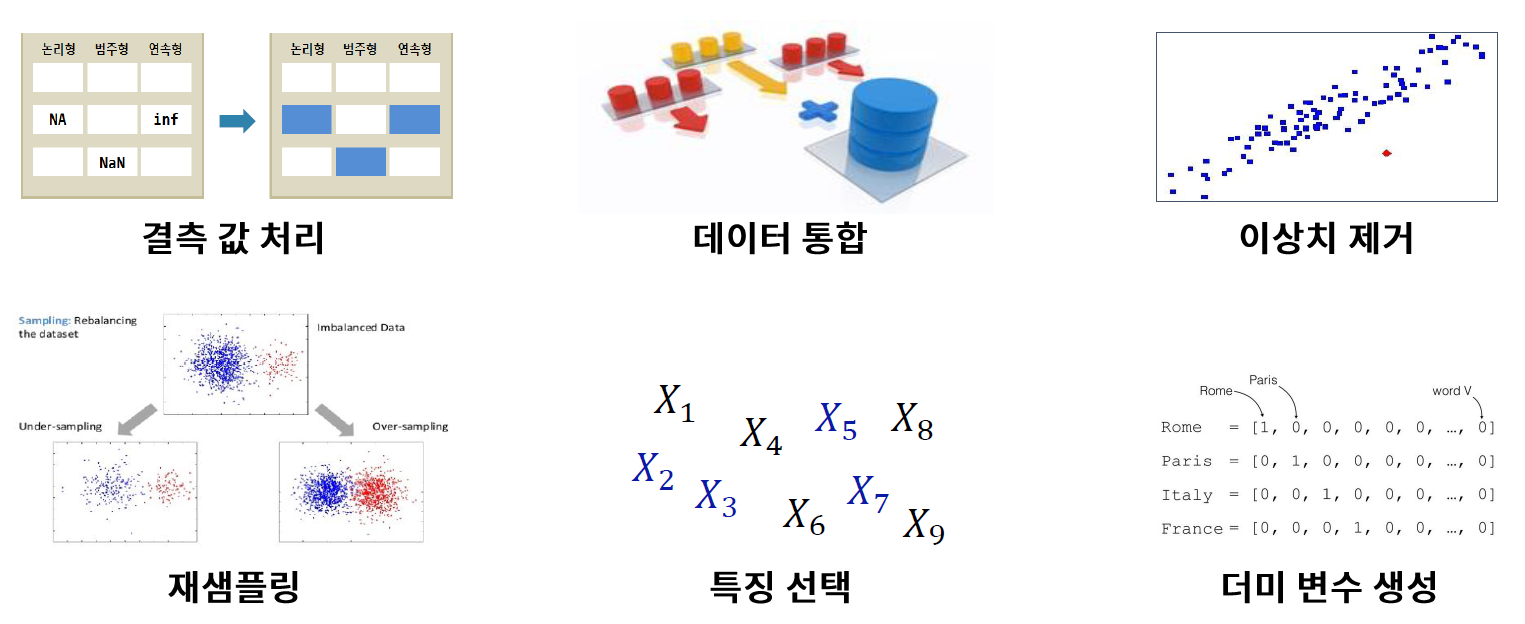
// 데이터를 가공하는 작업이라고 보면 된다.
* 모델링

// 모델선택+하이퍼 파라미터 설정은 하나의 단계로 봐도 무방하다.
* 모델평가
- 분류 모델의 대표적인 지표
. 정확도 (accuracy) : 전체 샘플 가운데 제대로 예측한 샘플의 비율
. 정밀도 (precision) : 긍정 클래스라고 에측한 샘플 가운데 실제 긍정 클래스 샘플의 비율
. 재현율 (recall) : 실제 긍정 클래스 샘플 가운데 제대로 예측된 샘플의 비율
. F1 점수 (F1-score) : 정밀도와 재현율의 조화 평균
- 에측 모델의 대표적인 지표
. 평균 제곱 오차 (mean sqaured erro)
. 평균 절대 오차 (mean absolute error)
. 평균 절대 퍼센트 오차 (mean absolute percentage error)
// 평균 절대 퍼센트 오차는 실제로는 잘 안 쓰인다. 분모가 0이 되는 경우가 있다.
- 잘못된 평가를 피하기 위해, 둘 이상의 평가 지표를 쓰는 것이 바람직하다.
* 결과보고서 작성
- 지금까지의 분석 결과를 바탕으로 보고서를 작성하는 단계
- 결과보고서의 통일된 구성은 없지만, 일반적으로 다음과 같이 구성된다.
1) 분석 목적
2) 데이터 탐색 및 전처리
3) 분석 방법
4) 분석 결과 및 활용 방안
// 어떻게 활용할 것인가가 중요하다.
* 부적절한 문제 정의
// 문제정의가 잘 못 되면 뒤에 결과까지 부적절한 영향을 주게 된다.
- 부적절한 문제 정의의 가장 흔한 유형으로는 (1) 구체적이지 않은 문제 정의, (2) 부적절한 특징 정의, (3) 수집 불가한 데이터 정의가 있다.
// 3 번의 경우 입문자에게 많이 발생 한다.
- 타이어 A사 사례
. 문제 정의 : "타이어 생산 공정에서 발생하는 데이터를 바탕으로 공정을 최적화하고 싶다"
. 제공 데이터 : 생산 공정에서 발생한 거의 모든 데이터
// 최적화라는 단어가 굉장히 모호한 단어이다. 추상적이다.
// 구체적으로 말할 수 있어야 한다.
// 타이어 생산 공정이라는 자체도 모호하다. 1단계만 이뤄진 것이 아니기 때문이다.
// column 에 대해서 데이터 설명서를 요청했지만 기업도 모른다고 답변을 했었다.
// 컬럼에 대한 정확한 정보를 알고 있어야 한다.
- 카드 A사 사례
. 문제 정의 : "일별 콜수요를 예측하고 싶다"
. 특징 : (1) 상담원 수, (2) 상담원의 역량
// 일별로 상담원수가 바뀔 가능성이 거의 없다.
// 다시 말해서 1, 2번의 변수가 영향을 미치지 않는다.
// 역량을 측정하는 것 자체도 모호하다.
* 부적절한 데이터 수집
- 부적절한 데이터 수집의 가장 흔한 유형으로 (1) 측정 오류 등으로 수집한 데이터가 실제 상황을 반영하지 못하는 경우, (2) 해결하고자 하는 문제와 무관한 데이터를 수집한 경우, (3) 특정 이벤트가 데이터에 누락된 경우가 있다.
// 데이터 수집이 잘 못 되면 어떤 방법을 쓰더라도 좋은 성능을 얻을 수가 없다.
- 자동차 시트 A사 사례
. 배경 : 자동차 시트 폼을 보관하는 과정에서 창고의 온도 및 습도 등에 따라, 폼이 수축하기도 이완하기도 한다.
. 문제 정의 : 창고의 환경에 따른 폼의 수축 및 이완정도를 예측하고, 그 정도가 심할 것이라 판단되면 환경을 제어
. 수집데이터 : 창고의 환경 조건과 폼의 수축 / 이완 정도 데이터 (수집 시기 : 2015년 6월 ~8월)
// 문제정의까지는 괜찮았던 정의 단계를 내렸지만...
// 수집데이터의 시기가 6~8월 정도로 이완 정도는 예측 할 수는 있지만, 수축 등의 데이터를 볼 수 없다.
// 통계적인 방향에서 보면 일어나지 않은.. 측정되지 않은 문제는 분석 할 수 없다는 것이다.
// 시기를 겨울철에도 모아서 다시 분석에 활용하였다.
* 부적절한 데이터 탐색
- 피드백 루프를 발생시키는 핵심 원인이 부적절한 데이터 탐색 혹은 데이터 탐색 생략임
// 탐색을 대충하고, 대충 검정해보고 다시 이전으로 돌아가는 현상이 발생한다.
- 데이터 탐색을 제대로 하지 않으면, 적절한 모델 선택 및 전처릴 할 수 없어, 모델 평가 단계에서 좋은 성능을 내는 것이 거의 불가능하다.
- 자동차 A사 사례
. 문제 정의 : 서비스 센터로 등록되는 클레임 가운데 안전 관련 클레임을 자동 검출하는 시스템 개발
. 무적절한 탬색 내용 : 클레임에서 오탈자 및 비표준어가 굉장히 많았지만 빈발 단어의 분포 등 만 확인한다.
. 결과 : 스펠링 교정 등의 전처리를 생략해서, 검출 성능이 매우 낮은 모델이 학습되어 다시 탐색 단계로 되돌아간다.
// 코드를 실행시키고 결과가 나온 시기가 1주일이 걸렸다. 그렇기 때문에 탐색을 꼼꼼히 해야만 된다.
* 부적절한 데이터 전처리
- 데이터 전처리는 크게 모델 개발을 위해 필수적인 전처리와 모델 성능 향상을 위한 전처리로 구분된다.
- 모통 모델 성능 향상을 위한 전처리를 생략해서 이전 단계로 되돌아가는 경우가 가장 흔하다.
// 필수적인 전처리를 반드시 해야 한다. Skip 할 수가 없다.
* 부적절한 모델링 및 모델 평가
- 모델링에서는 주로 부적절한 모델 및 파라미터 선택으로 잘못되는 경우가 대부분이며, 모델링 자체가 잘못되는 경우는 매우 드물다.
- 모델 평강가는 적절하지 않은 지표를 사용해서 잘못되는 경우가 대부분이며, 대표적인 사례로 단일 지표만 써서 부적절한 모델을 우수한 모델이라고 판단하는 경우가 있다.

// 실제 긍적의 재현율은 0 % 가 되어 버린다.
// 여러지표를 사용하는 것이 중요한 것이다.
// 클래스 분류형 문제가 있는 경우는 하나의 클래스로 치우쳐 발생되는 현상일 수 있다.
[03. Part 3) Ch 14. 이건 꼭 알아야 해 - 지도 학습 모델의 핵심 개념 - 03. 주요 모델의 구조 및 특성-1]

* 선형 회귀 모델과 정규화 회귀 모델
- 모델 구조

// 샘플 또는 레코드라고 부른다.
- 비용 함수 : 오차제곱합

// 선형 -> 오차 제곱합
// 정규화 -> 계수에 대한 패널티를 추가 시킨다.
* 선형 회귀 모델과 정규화 회귀 모델
- 특징과 라벨 간 비선형 관계가 무시될 수 있으므로, 특징 변환이 필요

- 특징 간 스케일 사이에 크게 영향을 받아, 예측 모델링을 할 때 스케일링이 필요하다.
- 남다 와 max_iter에 따라 과적합 정도가 직접 결정된다.
// max_iter 는 언제까지 학습 시킬 것인가에 대해서 이야기 하는 것이다.
// 신경망 등에서 대해서 고의적으로 작게 잡아서 학습 시킨다. 과적화를 피하기 위해서 그렇게 하는 경우도 있다는 것이다.
* 실습
// sklearn.linear_model.LinearRegression Documentation
scikit-learn.org/stable/modules/generated/sklearn.linear_model.LinearRegression.html
class sklearn.linear_model.LinearRegression(*, fit_intercept=True, normalize=False, copy_X=True, n_jobs=None)Ordinary least squares Linear Regression.
LinearRegression fits a linear model with coefficients w = (w1, …, wp) to minimize the residual sum of squares between the observed targets in the dataset, and the targets predicted by the linear approximation.
Parameters
fit_interceptbool, default=True
Whether to calculate the intercept for this model. If set to False, no intercept will be used in calculations (i.e. data is expected to be centered).
normalizebool, default=False
This parameter is ignored when fit_intercept is set to False. If True, the regressors X will be normalized before regression by subtracting the mean and dividing by the l2-norm. If you wish to standardize, please use sklearn.preprocessing.StandardScaler before calling fit on an estimator with normalize=False.
copy_Xbool, default=True
If True, X will be copied; else, it may be overwritten.
n_jobsint, default=None
The number of jobs to use for the computation. This will only provide speedup for n_targets > 1 and sufficient large problems. None means 1 unless in a joblib.parallel_backend context. -1 means using all processors. See Glossary for more details.
Attributes
coef_array of shape (n_features, ) or (n_targets, n_features)
Estimated coefficients for the linear regression problem. If multiple targets are passed during the fit (y 2D), this is a 2D array of shape (n_targets, n_features), while if only one target is passed, this is a 1D array of length n_features.
rank_int
Rank of matrix X. Only available when X is dense.
singular_array of shape (min(X, y),)
Singular values of X. Only available when X is dense.
intercept_float or array of shape (n_targets,)
Independent term in the linear model. Set to 0.0 if fit_intercept = False.

// X는 1차원이어서 sklean 의 인풋 구조와 맞지 않아, reshape를 사용한다.
// 1차원일 경우에는 X=[recod1, record2, ...]
// 학습데이터와 평가 데이터를 나눠야지 정확한 결과가 도출 될 수가 있다.
// 모델링 할 때는 스켈링이 반드시 필요하다.
* 로지스틱 회귀 모델
// 회귀 모델이지만 분류에 쓰이는 모델이라고 보면 된다.
- 모델 구조

- 비용 함수 : 크로스 엔트로피

* 로지스틱 회귀 모델
// 결과적으로는 선형식이라고 보면 된다.
// 선형적인 것들은 아래와 같은 특징을 가진다.
- 특징의 구간별로 라벨의 분포가 달라지는 경우, 적절한 구간을 나타낼 수 있도록 특징 변환이 필요하다.

* 실습
// 원본을 다시 쓴다고 하면 copy 를 사용한다고 보면 된다.
// sklearn.linear_model.LogisticRegression Documentation
scikit-learn.org/stable/modules/generated/sklearn.linear_model.LogisticRegression.html
class sklearn.linear_model.LogisticRegression(penalty='l2', *, dual=False, tol=0.0001, C=1.0, fit_intercept=True, intercept_scaling=1, class_weight=None, random_state=None, solver='lbfgs', max_iter=100, multi_class='auto', verbose=0, warm_start=False, n_jobs=None, l1_ratio=None)[source]Logistic Regression (aka logit, MaxEnt) classifier.
In the multiclass case, the training algorithm uses the one-vs-rest (OvR) scheme if the ‘multi_class’ option is set to ‘ovr’, and uses the cross-entropy loss if the ‘multi_class’ option is set to ‘multinomial’. (Currently the ‘multinomial’ option is supported only by the ‘lbfgs’, ‘sag’, ‘saga’ and ‘newton-cg’ solvers.)
This class implements regularized logistic regression using the ‘liblinear’ library, ‘newton-cg’, ‘sag’, ‘saga’ and ‘lbfgs’ solvers. Note that regularization is applied by default. It can handle both dense and sparse input. Use C-ordered arrays or CSR matrices containing 64-bit floats for optimal performance; any other input format will be converted (and copied).
The ‘newton-cg’, ‘sag’, and ‘lbfgs’ solvers support only L2 regularization with primal formulation, or no regularization. The ‘liblinear’ solver supports both L1 and L2 regularization, with a dual formulation only for the L2 penalty. The Elastic-Net regularization is only supported by the ‘saga’ solver.
Read more in the User Guide.
Parameters
penalty{‘l1’, ‘l2’, ‘elasticnet’, ‘none’}, default=’l2’
Used to specify the norm used in the penalization. The ‘newton-cg’, ‘sag’ and ‘lbfgs’ solvers support only l2 penalties. ‘elasticnet’ is only supported by the ‘saga’ solver. If ‘none’ (not supported by the liblinear solver), no regularization is applied.
New in version 0.19: l1 penalty with SAGA solver (allowing ‘multinomial’ + L1)
dualbool, default=False
Dual or primal formulation. Dual formulation is only implemented for l2 penalty with liblinear solver. Prefer dual=False when n_samples > n_features.
tolfloat, default=1e-4
Tolerance for stopping criteria.
Cfloat, default=1.0
Inverse of regularization strength; must be a positive float. Like in support vector machines, smaller values specify stronger regularization.
fit_interceptbool, default=True
Specifies if a constant (a.k.a. bias or intercept) should be added to the decision function.
intercept_scalingfloat, default=1
Useful only when the solver ‘liblinear’ is used and self.fit_intercept is set to True. In this case, x becomes [x, self.intercept_scaling], i.e. a “synthetic” feature with constant value equal to intercept_scaling is appended to the instance vector. The intercept becomes intercept_scaling * synthetic_feature_weight.
Note! the synthetic feature weight is subject to l1/l2 regularization as all other features. To lessen the effect of regularization on synthetic feature weight (and therefore on the intercept) intercept_scaling has to be increased.
class_weightdict or ‘balanced’, default=None
Weights associated with classes in the form {class_label: weight}. If not given, all classes are supposed to have weight one.
The “balanced” mode uses the values of y to automatically adjust weights inversely proportional to class frequencies in the input data as n_samples / (n_classes * np.bincount(y)).
Note that these weights will be multiplied with sample_weight (passed through the fit method) if sample_weight is specified.
New in version 0.17: class_weight=’balanced’
random_stateint, RandomState instance, default=None
Used when solver == ‘sag’, ‘saga’ or ‘liblinear’ to shuffle the data. See Glossary for details.
solver{‘newton-cg’, ‘lbfgs’, ‘liblinear’, ‘sag’, ‘saga’}, default=’lbfgs’
Algorithm to use in the optimization problem.
-
For small datasets, ‘liblinear’ is a good choice, whereas ‘sag’ and ‘saga’ are faster for large ones.
-
For multiclass problems, only ‘newton-cg’, ‘sag’, ‘saga’ and ‘lbfgs’ handle multinomial loss; ‘liblinear’ is limited to one-versus-rest schemes.
-
‘newton-cg’, ‘lbfgs’, ‘sag’ and ‘saga’ handle L2 or no penalty
-
‘liblinear’ and ‘saga’ also handle L1 penalty
-
‘saga’ also supports ‘elasticnet’ penalty
-
‘liblinear’ does not support setting penalty='none'
Note that ‘sag’ and ‘saga’ fast convergence is only guaranteed on features with approximately the same scale. You can preprocess the data with a scaler from sklearn.preprocessing.
New in version 0.17: Stochastic Average Gradient descent solver.
New in version 0.19: SAGA solver.
Changed in version 0.22: The default solver changed from ‘liblinear’ to ‘lbfgs’ in 0.22.
max_iterint, default=100
Maximum number of iterations taken for the solvers to converge.
multi_class{‘auto’, ‘ovr’, ‘multinomial’}, default=’auto’
If the option chosen is ‘ovr’, then a binary problem is fit for each label. For ‘multinomial’ the loss minimised is the multinomial loss fit across the entire probability distribution, even when the data is binary. ‘multinomial’ is unavailable when solver=’liblinear’. ‘auto’ selects ‘ovr’ if the data is binary, or if solver=’liblinear’, and otherwise selects ‘multinomial’.
New in version 0.18: Stochastic Average Gradient descent solver for ‘multinomial’ case.
Changed in version 0.22: Default changed from ‘ovr’ to ‘auto’ in 0.22.
verboseint, default=0
For the liblinear and lbfgs solvers set verbose to any positive number for verbosity.
warm_startbool, default=False
When set to True, reuse the solution of the previous call to fit as initialization, otherwise, just erase the previous solution. Useless for liblinear solver. See the Glossary.
New in version 0.17: warm_start to support lbfgs, newton-cg, sag, saga solvers.
n_jobsint, default=None
Number of CPU cores used when parallelizing over classes if multi_class=’ovr’”. This parameter is ignored when the solver is set to ‘liblinear’ regardless of whether ‘multi_class’ is specified or not. None means 1 unless in a joblib.parallel_backend context. -1 means using all processors. See Glossary for more details.
l1_ratiofloat, default=None
The Elastic-Net mixing parameter, with 0 <= l1_ratio <= 1. Only used if penalty='elasticnet'. Setting l1_ratio=0 is equivalent to using penalty='l2', while setting l1_ratio=1 is equivalent to using penalty='l1'. For 0 < l1_ratio <1, the penalty is a combination of L1 and L2.
Attributes
classes_ndarray of shape (n_classes, )
A list of class labels known to the classifier.
coef_ndarray of shape (1, n_features) or (n_classes, n_features)
Coefficient of the features in the decision function.
coef_ is of shape (1, n_features) when the given problem is binary. In particular, when multi_class='multinomial', coef_ corresponds to outcome 1 (True) and -coef_ corresponds to outcome 0 (False).
intercept_ndarray of shape (1,) or (n_classes,)
Intercept (a.k.a. bias) added to the decision function.
If fit_intercept is set to False, the intercept is set to zero. intercept_ is of shape (1,) when the given problem is binary. In particular, when multi_class='multinomial', intercept_ corresponds to outcome 1 (True) and -intercept_ corresponds to outcome 0 (False).
n_iter_ndarray of shape (n_classes,) or (1, )
Actual number of iterations for all classes. If binary or multinomial, it returns only 1 element. For liblinear solver, only the maximum number of iteration across all classes is given.
Changed in version 0.20: In SciPy <= 1.0.0 the number of lbfgs iterations may exceed max_iter. n_iter_ will now report at most max_iter.
[03. Part 3) Ch 14. 이건 꼭 알아야 해 - 지도 학습 모델의 핵심 개념 - 03. 주요 모델의 구조 및 특성-2]
* k- 최근접 이웃 (k-Nearest Neighbors; kNN)
- 모델 구조
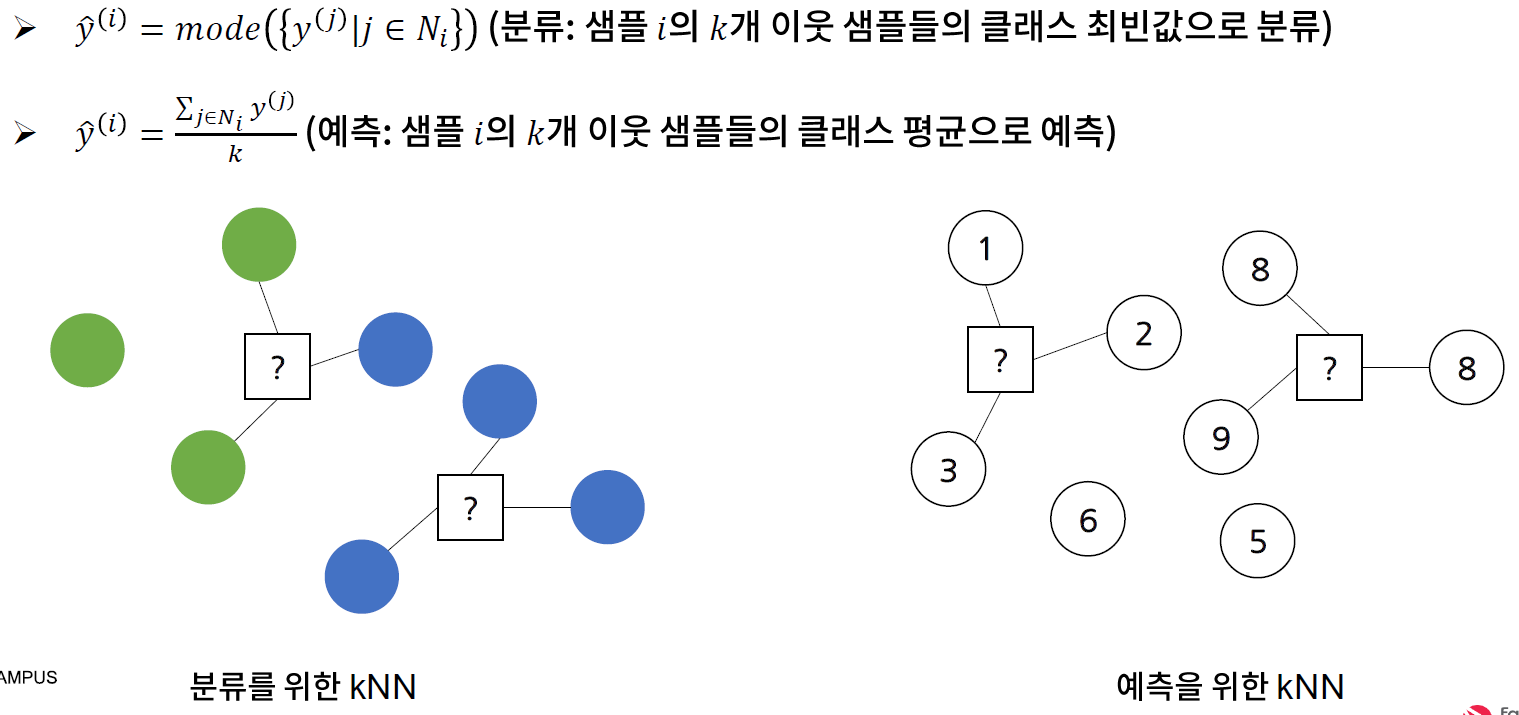
* k - 최근접 이웃 (k-Nearest Neighbors ; kNN)
- 주요 파라미터와 설정 방법
. 이웃 수 (k) : 홀수로 설정하며, 특징 수 대비 샘플 수가 적은 경우에는 k를 작게 설정하는 것이 바람직하다.
// 홀수로 설정하는 이유는 동점을 방지하기 위해서이다.
// 샘플수가 작다는 것은 데이터가 밀도가 작다는 것이다.
. 거리 및 유사도 척도
.. 모든 변수가 서열형 혹은 정수인 경우 : 맨하탄 거리
.. 방향성이 중요한 경우 (예 : 상품 추천 시스템) : 코사인 유사도
.. 모든 변수가 이진형이면서 희소하지 않은 경우 : 매칭 유사도
.. 모든 변수가 이진형이면서 희소한 경우 : 자카드 유사도
.. 그 외 : 유클리디안 거리
// 희소하다는 것은 데이터 들이 0으로 이뤄져있다고 보면 된다. 텍스트 데이터가 그렇게 이뤄져 있다고 보면 된다.
- 특징 추출이 어려우나 유사도 및 거리 계산만 가능한 경우 (예: 시퀀스 데이터) 에 주로 활용
- 모든 특징이 연속형이고 샘플 수가 많지 않은 경우에 좋은 성능을 보인다고 알려져 있음
- 특징 간 스케일 차이에 크게 영향을 받아, 스케일링이 반드시 필요함 (코사인 유사도를 사용하는 경우 제외)
- 거리 및 유사도 계산에 문제가 없다면, 별다른 특징 변환이 필요하지 않다.
* 의사 결정 나무 (Decision tree)
- 모델 구조

// 설명력이 굉장히 높다는 것이 이 의사결정나무의 핵심이라고 볼 수 있다.
- 예측 과정을 잘 설명할 수 있다는 장점 덕분에 많은 프로젝트에서 활용
. A 보험사 : 고객의 이탈 여부를 예측하고, 그 원인을 파악해달라
. B 밸브사 : 밸브의 불량이 발생하는 공정 상의 원인을 파악해달라
. C 홈쇼핑사 : 방송 조건에 따라 예측한 상품 매출액 기준으로 방송 편성표를 추천해주고, 그 근거를 설명해 달라
- 선형 분류기라는 한계로 예측력이 좋은 편에 속하지는 못하나, 최근 각광 받고 있는 앙상블 모델 (예 : XGBoost, lightGBM) 의 기본 모형으로 사용된다.
// 예측력은 좋을지 몰라도 설명력이 떨어진다는 문제가 있다.
- 주요 파라미터
. max_depth : 최대 깊이로 그 크기가 클수록 모델이 복잡해진다.
. min_samples_leaf : 잎 노드에 있어야 하는 최소 샘플 수로, 그 크기가 작을 수록 모델이 복잡해진다.
* 나이브 베이즈 (Navie Bayes)
- 모델 구조
. 베이즈 정리르 사용하고 특징 간 독립을 가정하여 사후 확률을 계산
. 가능도는 조건부 분포를 가정하여 추정한다.
.. 이진형 변수 : 베르누이 분포
.. 범주형 변수 : 다항 분포
.. 연속형 변수 : 가우시안 분포

- 모델 특성
. 특징 간 독립 가정이 실제로는 굉장히 비현실적이므로, 일반적으로 높은 성능을 기대하긴 어렵다.
// 특징 간 독립 가정이 통계학적으로는 많이 쓰이지만.. 높은 성능을 기대하긴 어렵다.
. 설정한 분푸에 따라 성능 차이가 크므로, 특징의 타입이 서로 같은 경웨 사용하기 바람직하다.
. 특징이 매우 많고 그 타입이 같은 문제 (예: 이진형 텍스트 분류)에 주로 사용된다.
. 특징 간 독립 가정이 실제로는 굉장히 비현실적이므로, 일반적으로 높은 성능을 기대하긴 어렵다.
. 설정한 분포에 따라 성능 차이가 크므로, 특징의 타입이 서로 같은 경우에 사용하기 바람직하다.
. 특징이 매우 많고 그 타입이 같은 문제 (예: 이진형 텍스트 분류) 에 주로 사용된다.
* 서포트 벡터 머신 (Support Vector Machine; SVM)
- 모델 구조

- 최적화 모델

- 오차를 최소화하면서 동시에 마진을 최대화하는 분류 모델로, 커널 트릭을 활용하여 저차원 공간을 고차원 공간으로 매핑한다.
- 마진의 개념을 회귀에 활용한 모델을 서포트 벡터 회귀 (Support Vector Regression)이라 한다.
- 주요 파라미터
. kernel : 통상적으로 이진 변수가 많으면 linear 커널이, 연속 변수가 많으면 rbf 커널이 잘 맞는 다고 알려져 있다.
// 특징간 차이는 rbf, 특징간 곱 linear
. C : 오차 패널티에 대한 계수로, 이 값이 작을 수록 마진 최대화에 클수록 학습 오차 최소화에 신경을 쓰며, 보통 10n 범위에서 튜닝한다.
. r : rbf 커널의 파라미터로, 크면 클수록 데이터의 모양을 잡 잡아내지만 오차가 커질 위험이 있으며, C 가 증가하면 r도 증가하게 튜닝하는 것이 일반적이다.
- 파라미터 튜닝이 까다로운 모델이지만, 튜닝만 잘하면 좋은 성능을 보장하는 모델이다.
// 학술에 관심이 있으면 VC 정리...를 확인해보면 좋다.
* 신경망 (Neural Network)
- 모델 구조

- 초기 가중치에 크게 영향을 받는 모델로, 세밀하게 random_state 와 max_iter 값을 조정해야 하다.
// 우연에 많이 기반한다는 의미이다. 데이터가 작으면 작을 수록 그런 경향이 크다.
- 은닉 노드가 하나 추가되면 그에 따라 하나 이상의 가중치가 추가되어, 복잡도가 크게 증가할 수 있다.
- 모든 변수 타입이 연속형인 경우에 성능이 잘 나오는 것으로 알려져 있으며, 은닉 층 구조에 따른 복잡도 조절이 파라미터 튜닝에서 고려해야 할 가장 중요한 요소임
- 최근 딥러닝의 발전으로 크게 주목받는 모델이지만, 특정 주제 (예 : 시계열 예측, 이미지 분류, 객체 탐지 등) 를 제외하고는 깊은 층의 신경망은 과적합으로 인한 성능 이슈가 자주 발생한다.
* 트리 기반의 앙상블 모델
- 최근 의사 결정나무를 기본 모형으로 하는 앙상블 모형이 캐글 등에서 자주 사용되며, 좋은 성능을 보인다.
- 랜덤 포레스트 : 배깅(bagging) 방식으로 여러 트리를 학습하여 결합한 모델
- XGboost & LightGBM : 부스팅 방식으로 여러 트리를 순차적으로 학습하여 결합한 모델
- 랜덤 포레스트를 사용할 때는 트리의 개수와 나무의 최대 깊이를 조정해야 하며, XGboost 와 LightGBM 을 사용할 때는 트리의 개수, 나무의 최대 깊이, 학습률을 조정해야 한다.
. 트리의 개수 : 통상적으로 트리의 개수가 많으면 많을 수록 좋은 성능을 내지만, 어느 수준 이상에서는 거의 큰 차일ㄹ 보이지 않는다.
. 나무의 최대 깊이 : 4이하로 설정해주는 것이 과적합을 피할 수 있어, 바람직하다.
. 학습률 : 이 값은 작으면 작을 수록 과소적합 위험이 있으며, 크면 클수록 과적합 위험이 있다. 통상적으로 0.1로 설정한다.
[파이썬을 활용한 데이터 전처리 Level UP-Comment]
- 모델 개발 프로세스에 대해서 배웠고, 지도학습에서는 선형회귀, 의사결정나무, 신경망 등에 대해서도 배워 볼 수 있었다.
파이썬을 활용한 데이터 전처리 Level UP 올인원 패키지 Online. | 패스트캠퍼스
데이터 분석에 필요한 기초 전처리부터, 데이터의 품질 및 머신러닝 성능 향상을 위한 고급 스킬까지 완전 정복하는 데이터 전처리 트레이닝 온라인 강의입니다.
www.fastcampus.co.kr